 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRPRA: Predicting an LLM-Judge for Efficient but Performant Inference
Apr 14, 2026Large language models (LLMs) face a fundamental trade-off between computational efficiency (e.g., number of parameters) and output quality, especially when deployed on computationally limited devices such as phones or laptops. One way to address this challenge is by following the example of humans and have models ask for help when they believe they are incapable of solving a problem on their own; we can overcome this trade-off by allowing smaller models to respond to queries when they believe they can provide good responses, and deferring to larger models when they do not believe they can. To this end, in this paper, we investigate the viability of Predict-Answer/Act (PA) and Reason-Predict-Reason-Answer/Act (RPRA) paradigms where models predict -- prior to responding -- how an LLM judge would score their output. We evaluate three approaches: zero-shot prediction, prediction using an in-context report card, and supervised fine-tuning. Our results show that larger models (particularly reasoning models) perform well when predicting generic LLM judges zero-shot, while smaller models can reliably predict such judges well after being fine-tuned or provided with an in-context report card. Altogether, both approaches can substantially improve the prediction accuracy of smaller models, with report cards and fine-tuning achieving mean improvements of up to 55% and 52% across datasets, respectively. These findings suggest that models can learn to predict their own performance limitations, paving the way for more efficient and self-aware AI systems.
Neural Computers
Apr 07, 2026We propose a new frontier: Neural Computers (NCs) -- an emerging machine form that unifies computation, memory, and I/O in a learned runtime state. Unlike conventional computers, which execute explicit programs, agents, which act over external execution environments, and world models, which learn environment dynamics, NCs aim to make the model itself the running computer. Our long-term goal is the Completely Neural Computer (CNC): the mature, general-purpose realization of this emerging machine form, with stable execution, explicit reprogramming, and durable capability reuse. As an initial step, we study whether early NC primitives can be learned solely from collected I/O traces, without instrumented program state. Concretely, we instantiate NCs as video models that roll out screen frames from instructions, pixels, and user actions (when available) in CLI and GUI settings. These implementations show that learned runtimes can acquire early interface primitives, especially I/O alignment and short-horizon control, while routine reuse, controlled updates, and symbolic stability remain open. We outline a roadmap toward CNCs around these challenges. If overcome, CNCs could establish a new computing paradigm beyond today's agents, world models, and conventional computers.
EgoAVU: Egocentric Audio-Visual Understanding
Feb 05, 2026Understanding egocentric videos plays a vital role for embodied intelligence. Recent multi-modal large language models (MLLMs) can accept both visual and audio inputs. However, due to the challenge of obtaining text labels with coherent joint-modality information, whether MLLMs can jointly understand both modalities in egocentric videos remains under-explored. To address this problem, we introduce EgoAVU, a scalable data engine to automatically generate egocentric audio-visual narrations, questions, and answers. EgoAVU enriches human narrations with multimodal context and generates audio-visual narrations through cross-modal correlation modeling. Token-based video filtering and modular, graph-based curation ensure both data diversity and quality. Leveraging EgoAVU, we construct EgoAVU-Instruct, a large-scale training dataset of 3M samples, and EgoAVU-Bench, a manually verified evaluation split covering diverse tasks. EgoAVU-Bench clearly reveals the limitations of existing MLLMs: they bias heavily toward visual signals, often neglecting audio cues or failing to correspond audio with the visual source. Finetuning MLLMs on EgoAVU-Instruct effectively addresses this issue, enabling up to 113% performance improvement on EgoAVU-Bench. Such benefits also transfer to other benchmarks such as EgoTempo and EgoIllusion, achieving up to 28% relative performance gain. Code will be released to the community.
SLAP: Scalable Language-Audio Pretraining with Variable-Duration Audio and Multi-Objective Training
Jan 18, 2026Contrastive language-audio pretraining (CLAP) has achieved notable success in learning semantically rich audio representations and is widely adopted for various audio-related tasks. However, current CLAP models face several key limitations. First, they are typically trained on relatively small datasets, often comprising a few million audio samples. Second, existing CLAP models are restricted to short and fixed duration, which constrains their usage in real-world scenarios with variable-duration audio. Third, the standard contrastive training objective operates on global representations, which may hinder the learning of dense, fine-grained audio features. To address these challenges, we introduce Scalable Language-Audio Pretraining (SLAP), which scales language-audio pretraining to 109 million audio-text pairs with variable audio durations and incorporates multiple training objectives. SLAP unifies contrastive loss with additional self-supervised and captioning losses in a single-stage training, facilitating the learning of richer dense audio representations. The proposed SLAP model achieves new state-of-the-art performance on audio-text retrieval and zero-shot audio classification tasks, demonstrating its effectiveness across diverse benchmarks.
TFKAN: Time-Frequency KAN for Long-Term Time Series Forecasting
Jun 15, 2025Kolmogorov-Arnold Networks (KANs) are highly effective in long-term time series forecasting due to their ability to efficiently represent nonlinear relationships and exhibit local plasticity. However, prior research on KANs has predominantly focused on the time domain, neglecting the potential of the frequency domain. The frequency domain of time series data reveals recurring patterns and periodic behaviors, which complement the temporal information captured in the time domain. To address this gap, we explore the application of KANs in the frequency domain for long-term time series forecasting. By leveraging KANs' adaptive activation functions and their comprehensive representation of signals in the frequency domain, we can more effectively learn global dependencies and periodic patterns. To integrate information from both time and frequency domains, we propose the $\textbf{T}$ime-$\textbf{F}$requency KAN (TFKAN). TFKAN employs a dual-branch architecture that independently processes features from each domain, ensuring that the distinct characteristics of each domain are fully utilized without interference. Additionally, to account for the heterogeneity between domains, we introduce a dimension-adjustment strategy that selectively upscales only in the frequency domain, enhancing efficiency while capturing richer frequency information. Experimental results demonstrate that TFKAN consistently outperforms state-of-the-art (SOTA) methods across multiple datasets. The code is available at https://github.com/LcWave/TFKAN.
ParetoQ: Scaling Laws in Extremely Low-bit LLM Quantization
Feb 04, 2025The optimal bit-width for achieving the best trade-off between quantized model size and accuracy has been a subject of ongoing debate. While some advocate for 4-bit quantization, others propose that 1.58-bit offers superior results. However, the lack of a cohesive framework for different bits has left such conclusions relatively tenuous. We present ParetoQ, the first unified framework that facilitates rigorous comparisons across 1-bit, 1.58-bit, 2-bit, 3-bit, and 4-bit quantization settings. Our findings reveal a notable learning transition between 2 and 3 bits: For 3-bits and above, the fine-tuned models stay close to their original pre-trained distributions, whereas for learning 2-bit networks or below, the representations change drastically. By optimizing training schemes and refining quantization functions, ParetoQ surpasses all previous methods tailored to specific bit widths. Remarkably, our ParetoQ ternary 600M-parameter model even outperforms the previous SoTA ternary 3B-parameter model in accuracy, using only one-fifth of the parameters. Extensive experimentation shows that ternary, 2-bit, and 3-bit quantization maintains comparable performance in the size-accuracy trade-off and generally exceeds 4-bit and binary quantization. Considering hardware constraints, 2-bit quantization offers promising potential for memory reduction and speedup.
MASV: Speaker Verification with Global and Local Context Mamba
Dec 14, 2024


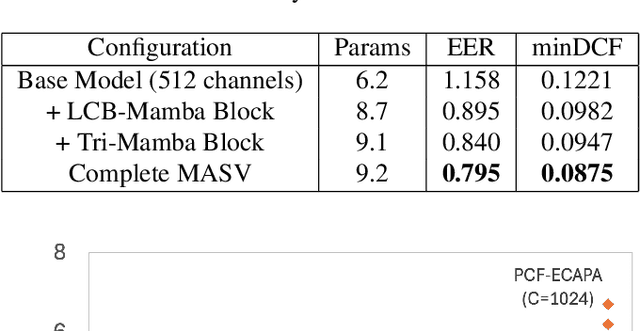
Deep learning models like Convolutional Neural Networks and transformers have shown impressive capabilities in speech verification, gaining considerable attention in the research community. However, CNN-based approaches struggle with modeling long-sequence audio effectively, resulting in suboptimal verification performance. On the other hand, transformer-based methods are often hindered by high computational demands, limiting their practicality. This paper presents the MASV model, a novel architecture that integrates the Mamba module into the ECAPA-TDNN framework. By introducing the Local Context Bidirectional Mamba and Tri-Mamba block, the model effectively captures both global and local context within audio sequences. Experimental results demonstrate that the MASV model substantially enhances verification performance, surpassing existing models in both accuracy and efficiency.
MFF-FTNet: Multi-scale Feature Fusion across Frequency and Temporal Domains for Time Series Forecasting
Nov 26, 2024



Time series forecasting is crucial in many fields, yet current deep learning models struggle with noise, data sparsity, and capturing complex multi-scale patterns. This paper presents MFF-FTNet, a novel framework addressing these challenges by combining contrastive learning with multi-scale feature extraction across both frequency and time domains. MFF-FTNet introduces an adaptive noise augmentation strategy that adjusts scaling and shifting factors based on the statistical properties of the original time series data, enhancing model resilience to noise. The architecture is built around two complementary modules: a Frequency-Aware Contrastive Module (FACM) that refines spectral representations through frequency selection and contrastive learning, and a Complementary Time Domain Contrastive Module (CTCM) that captures both short- and long-term dependencies using multi-scale convolutions and feature fusion. A unified feature representation strategy enables robust contrastive learning across domains, creating an enriched framework for accurate forecasting. Extensive experiments on five real-world datasets demonstrate that MFF-FTNet significantly outperforms state-of-the-art models, achieving a 7.7% MSE improvement on multivariate tasks. These findings underscore MFF-FTNet's effectiveness in modeling complex temporal patterns and managing noise and sparsity, providing a comprehensive solution for both long- and short-term forecasting.
Llama Guard 3-1B-INT4: Compact and Efficient Safeguard for Human-AI Conversations
Nov 18, 2024This paper presents Llama Guard 3-1B-INT4, a compact and efficient Llama Guard model, which has been open-sourced to the community during Meta Connect 2024. We demonstrate that Llama Guard 3-1B-INT4 can be deployed on resource-constrained devices, achieving a throughput of at least 30 tokens per second and a time-to-first-token of 2.5 seconds or less on a commodity Android mobile CPU. Notably, our experiments show that Llama Guard 3-1B-INT4 attains comparable or superior safety moderation scores to its larger counterpart, Llama Guard 3-1B, despite being approximately 7 times smaller in size (440MB).
Agent-as-a-Judge: Evaluate Agents with Agents
Oct 14, 2024



Contemporary evaluation techniques are inadequate for agentic systems. These approaches either focus exclusively on final outcomes -- ignoring the step-by-step nature of agentic systems, or require excessive manual labour. To address this, we introduce the Agent-as-a-Judge framework, wherein agentic systems are used to evaluate agentic systems. This is an organic extension of the LLM-as-a-Judge framework, incorporating agentic features that enable intermediate feedback for the entire task-solving process. We apply the Agent-as-a-Judge to the task of code generation. To overcome issues with existing benchmarks and provide a proof-of-concept testbed for Agent-as-a-Judge, we present DevAI, a new benchmark of 55 realistic automated AI development tasks. It includes rich manual annotations, like a total of 365 hierarchical user requirements. We benchmark three of the popular agentic systems using Agent-as-a-Judge and find it dramatically outperforms LLM-as-a-Judge and is as reliable as our human evaluation baseline. Altogether, we believe that Agent-as-a-Judge marks a concrete step forward for modern agentic systems -- by providing rich and reliable reward signals necessary for dynamic and scalable self-improvement.