 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeWearVox: An Egocentric Multichannel Voice Assistant Benchmark for Wearables
Dec 25, 2025Wearable devices such as AI glasses are transforming voice assistants into always-available, hands-free collaborators that integrate seamlessly with daily life, but they also introduce challenges like egocentric audio affected by motion and noise, rapid micro-interactions, and the need to distinguish device-directed speech from background conversations. Existing benchmarks largely overlook these complexities, focusing instead on clean or generic conversational audio. To bridge this gap, we present WearVox, the first benchmark designed to rigorously evaluate voice assistants in realistic wearable scenarios. WearVox comprises 3,842 multi-channel, egocentric audio recordings collected via AI glasses across five diverse tasks including Search-Grounded QA, Closed-Book QA, Side-Talk Rejection, Tool Calling, and Speech Translation, spanning a wide range of indoor and outdoor environments and acoustic conditions. Each recording is accompanied by rich metadata, enabling nuanced analysis of model performance under real-world constraints. We benchmark leading proprietary and open-source speech Large Language Models (SLLMs) and find that most real-time SLLMs achieve accuracies on WearVox ranging from 29% to 59%, with substantial performance degradation on noisy outdoor audio, underscoring the difficulty and realism of the benchmark. Additionally, we conduct a case study with two new SLLMs that perform inference with single-channel and multi-channel audio, demonstrating that multi-channel audio inputs significantly enhance model robustness to environmental noise and improve discrimination between device-directed and background speech. Our results highlight the critical importance of spatial audio cues for context-aware voice assistants and establish WearVox as a comprehensive testbed for advancing wearable voice AI research.
Multi-Channel Differential ASR for Robust Wearer Speech Recognition on Smart Glasses
Sep 17, 2025With the growing adoption of wearable devices such as smart glasses for AI assistants, wearer speech recognition (WSR) is becoming increasingly critical to next-generation human-computer interfaces. However, in real environments, interference from side-talk speech remains a significant challenge to WSR and may cause accumulated errors for downstream tasks such as natural language processing. In this work, we introduce a novel multi-channel differential automatic speech recognition (ASR) method for robust WSR on smart glasses. The proposed system takes differential inputs from different frontends that complement each other to improve the robustness of WSR, including a beamformer, microphone selection, and a lightweight side-talk detection model. Evaluations on both simulated and real datasets demonstrate that the proposed system outperforms the traditional approach, achieving up to an 18.0% relative reduction in word error rate.
Thinking in Directivity: Speech Large Language Model for Multi-Talker Directional Speech Recognition
Jun 17, 2025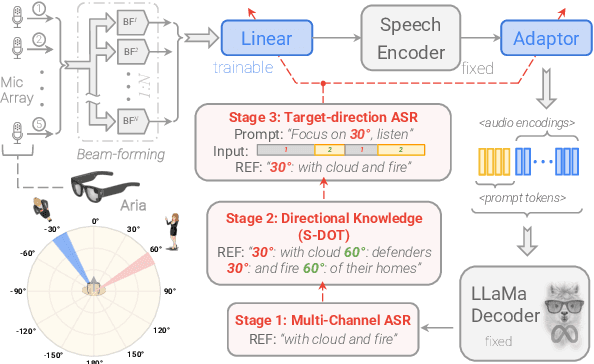
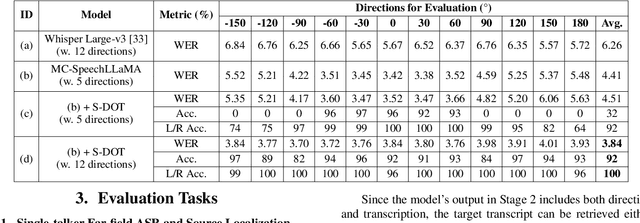
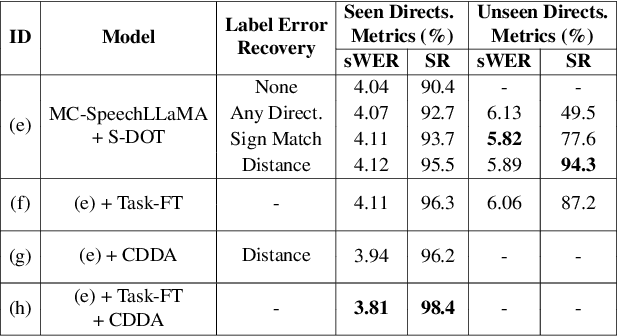
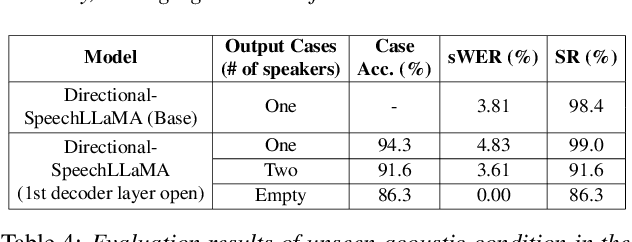
Recent studies have demonstrated that prompting large language models (LLM) with audio encodings enables effective speech recognition capabilities. However, the ability of Speech LLMs to comprehend and process multi-channel audio with spatial cues remains a relatively uninvestigated area of research. In this work, we present directional-SpeechLlama, a novel approach that leverages the microphone array of smart glasses to achieve directional speech recognition, source localization, and bystander cross-talk suppression. To enhance the model's ability to understand directivity, we propose two key techniques: serialized directional output training (S-DOT) and contrastive direction data augmentation (CDDA). Experimental results show that our proposed directional-SpeechLlama effectively captures the relationship between textual cues and spatial audio, yielding strong performance in both speech recognition and source localization tasks.
MASV: Speaker Verification with Global and Local Context Mamba
Dec 14, 2024


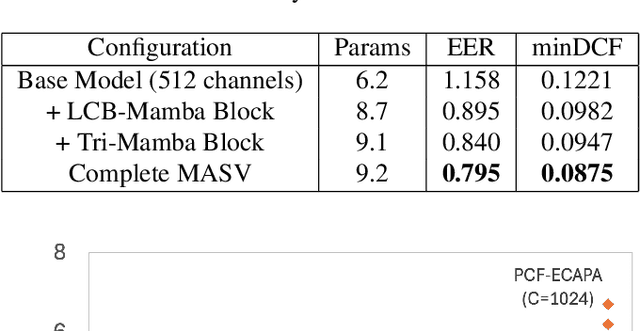
Deep learning models like Convolutional Neural Networks and transformers have shown impressive capabilities in speech verification, gaining considerable attention in the research community. However, CNN-based approaches struggle with modeling long-sequence audio effectively, resulting in suboptimal verification performance. On the other hand, transformer-based methods are often hindered by high computational demands, limiting their practicality. This paper presents the MASV model, a novel architecture that integrates the Mamba module into the ECAPA-TDNN framework. By introducing the Local Context Bidirectional Mamba and Tri-Mamba block, the model effectively captures both global and local context within audio sequences. Experimental results demonstrate that the MASV model substantially enhances verification performance, surpassing existing models in both accuracy and efficiency.
M-BEST-RQ: A Multi-Channel Speech Foundation Model for Smart Glasses
Sep 17, 2024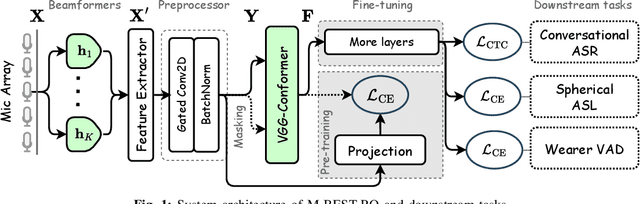

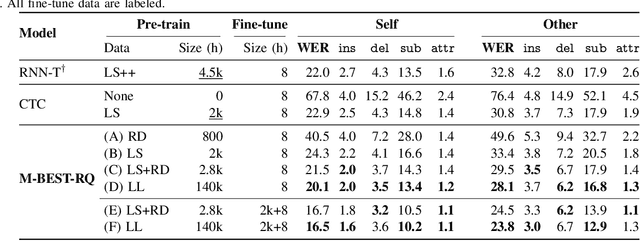
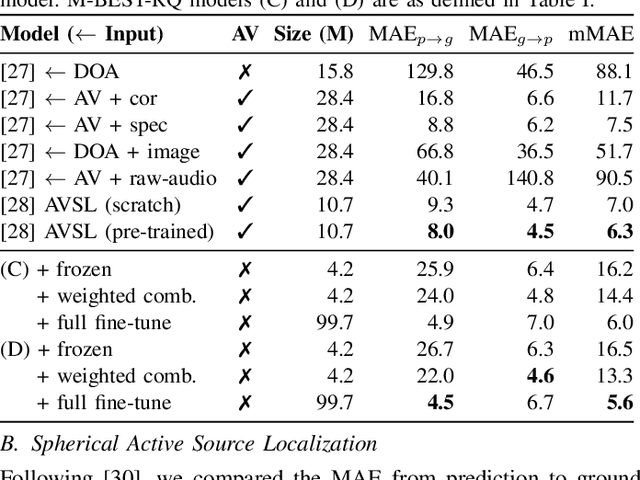
The growing popularity of multi-channel wearable devices, such as smart glasses, has led to a surge of applications such as targeted speech recognition and enhanced hearing. However, current approaches to solve these tasks use independently trained models, which may not benefit from large amounts of unlabeled data. In this paper, we propose M-BEST-RQ, the first multi-channel speech foundation model for smart glasses, which is designed to leverage large-scale self-supervised learning (SSL) in an array-geometry agnostic approach. While prior work on multi-channel speech SSL only evaluated on simulated settings, we curate a suite of real downstream tasks to evaluate our model, namely (i) conversational automatic speech recognition (ASR), (ii) spherical active source localization, and (iii) glasses wearer voice activity detection, which are sourced from the MMCSG and EasyCom datasets. We show that a general-purpose M-BEST-RQ encoder is able to match or surpass supervised models across all tasks. For the conversational ASR task in particular, using only 8 hours of labeled speech, our model outperforms a supervised ASR baseline that is trained on 2000 hours of labeled data, which demonstrates the effectiveness of our approach.
Effective Integration of KAN for Keyword Spotting
Sep 13, 2024



Keyword spotting (KWS) is an important speech processing component for smart devices with voice assistance capability. In this paper, we investigate if Kolmogorov-Arnold Networks (KAN) can be used to enhance the performance of KWS. We explore various approaches to integrate KAN for a model architecture based on 1D Convolutional Neural Networks (CNN). We find that KAN is effective at modeling high-level features in lower-dimensional spaces, resulting in improved KWS performance when integrated appropriately. The findings shed light on understanding KAN for speech processing tasks and on other modalities for future researchers.
Query-by-Example Keyword Spotting Using Spectral-Temporal Graph Attentive Pooling and Multi-Task Learning
Aug 27, 2024



Existing keyword spotting (KWS) systems primarily rely on predefined keyword phrases. However, the ability to recognize customized keywords is crucial for tailoring interactions with intelligent devices. In this paper, we present a novel Query-by-Example (QbyE) KWS system that employs spectral-temporal graph attentive pooling and multi-task learning. This framework aims to effectively learn speaker-invariant and linguistic-informative embeddings for QbyE KWS tasks. Within this framework, we investigate three distinct network architectures for encoder modeling: LiCoNet, Conformer and ECAPA_TDNN. The experimental results on a substantial internal dataset of $629$ speakers have demonstrated the effectiveness of the proposed QbyE framework in maximizing the potential of simpler models such as LiCoNet. Particularly, LiCoNet, which is 13x more efficient, achieves comparable performance to the computationally intensive Conformer model (1.98% vs. 1.63\% FRR at 0.3 FAs/Hr).
Disentangled Training with Adversarial Examples For Robust Small-footprint Keyword Spotting
Aug 23, 2024



A keyword spotting (KWS) engine that is continuously running on device is exposed to various speech signals that are usually unseen before. It is a challenging problem to build a small-footprint and high-performing KWS model with robustness under different acoustic environments. In this paper, we explore how to effectively apply adversarial examples to improve KWS robustness. We propose datasource-aware disentangled learning with adversarial examples to reduce the mismatch between the original and adversarial data as well as the mismatch across original training datasources. The KWS model architecture is based on depth-wise separable convolution and a simple attention module. Experimental results demonstrate that the proposed learning strategy improves false reject rate by $40.31%$ at $1%$ false accept rate on the internal dataset, compared to the strongest baseline without using adversarial examples. Our best-performing system achieves $98.06%$ accuracy on the Google Speech Commands V1 dataset.
AGADIR: Towards Array-Geometry Agnostic Directional Speech Recognition
Jan 18, 2024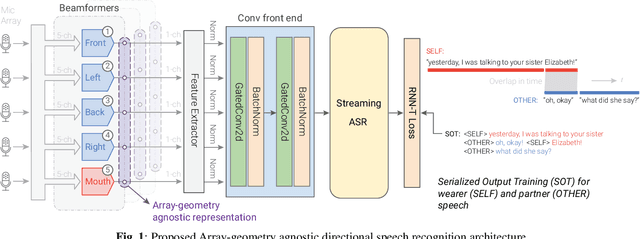

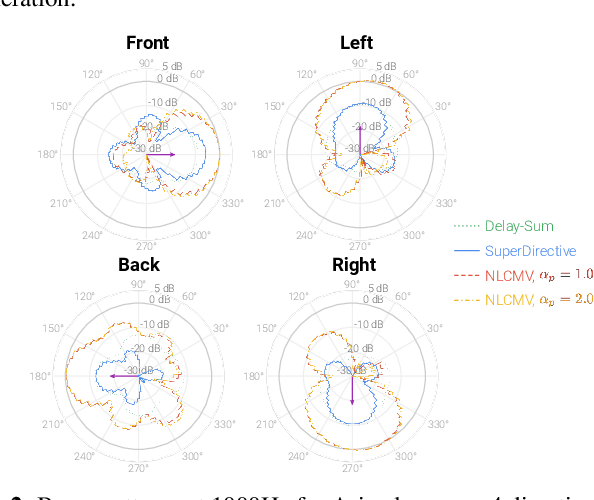

Wearable devices like smart glasses are approaching the compute capability to seamlessly generate real-time closed captions for live conversations. We build on our recently introduced directional Automatic Speech Recognition (ASR) for smart glasses that have microphone arrays, which fuses multi-channel ASR with serialized output training, for wearer/conversation-partner disambiguation as well as suppression of cross-talk speech from non-target directions and noise. When ASR work is part of a broader system-development process, one may be faced with changes to microphone geometries as system development progresses. This paper aims to make multi-channel ASR insensitive to limited variations of microphone-array geometry. We show that a model trained on multiple similar geometries is largely agnostic and generalizes well to new geometries, as long as they are not too different. Furthermore, training the model this way improves accuracy for seen geometries by 15 to 28\% relative. Lastly, we refine the beamforming by a novel Non-Linearly Constrained Minimum Variance criterion.
FADI-AEC: Fast Score Based Diffusion Model Guided by Far-end Signal for Acoustic Echo Cancellation
Jan 08, 2024Despite the potential of diffusion models in speech enhancement, their deployment in Acoustic Echo Cancellation (AEC) has been restricted. In this paper, we propose DI-AEC, pioneering a diffusion-based stochastic regeneration approach dedicated to AEC. Further, we propose FADI-AEC, fast score-based diffusion AEC framework to save computational demands, making it favorable for edge devices. It stands out by running the score model once per frame, achieving a significant surge in processing efficiency. Apart from that, we introduce a novel noise generation technique where far-end signals are utilized, incorporating both far-end and near-end signals to refine the score model's accuracy. We test our proposed method on the ICASSP2023 Microsoft deep echo cancellation challenge evaluation dataset, where our method outperforms some of the end-to-end methods and other diffusion based echo cancellation methods.