 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEffective Integration of KAN for Keyword Spotting
Sep 13, 2024Keyword spotting (KWS) is an important speech processing component for smart devices with voice assistance capability. In this paper, we investigate if Kolmogorov-Arnold Networks (KAN) can be used to enhance the performance of KWS. We explore various approaches to integrate KAN for a model architecture based on 1D Convolutional Neural Networks (CNN). We find that KAN is effective at modeling high-level features in lower-dimensional spaces, resulting in improved KWS performance when integrated appropriately. The findings shed light on understanding KAN for speech processing tasks and on other modalities for future researchers.
Query-by-Example Keyword Spotting Using Spectral-Temporal Graph Attentive Pooling and Multi-Task Learning
Aug 27, 2024



Existing keyword spotting (KWS) systems primarily rely on predefined keyword phrases. However, the ability to recognize customized keywords is crucial for tailoring interactions with intelligent devices. In this paper, we present a novel Query-by-Example (QbyE) KWS system that employs spectral-temporal graph attentive pooling and multi-task learning. This framework aims to effectively learn speaker-invariant and linguistic-informative embeddings for QbyE KWS tasks. Within this framework, we investigate three distinct network architectures for encoder modeling: LiCoNet, Conformer and ECAPA_TDNN. The experimental results on a substantial internal dataset of $629$ speakers have demonstrated the effectiveness of the proposed QbyE framework in maximizing the potential of simpler models such as LiCoNet. Particularly, LiCoNet, which is 13x more efficient, achieves comparable performance to the computationally intensive Conformer model (1.98% vs. 1.63\% FRR at 0.3 FAs/Hr).
Certifying Global Robustness for Deep Neural Networks
May 31, 2024



A globally robust deep neural network resists perturbations on all meaningful inputs. Current robustness certification methods emphasize local robustness, struggling to scale and generalize. This paper presents a systematic and efficient method to evaluate and verify global robustness for deep neural networks, leveraging the PAC verification framework for solid guarantees on verification results. We utilize probabilistic programs to characterize meaningful input regions, setting a realistic standard for global robustness. Additionally, we introduce the cumulative robustness curve as a criterion in evaluating global robustness. We design a statistical method that combines multi-level splitting and regression analysis for the estimation, significantly reducing the execution time. Experimental results demonstrate the efficiency and effectiveness of our verification method and its capability to find rare and diversified counterexamples for adversarial training.
Incentivizing Federated Learning
May 22, 2022
Federated Learning is an emerging distributed collaborative learning paradigm used by many of applications nowadays. The effectiveness of federated learning relies on clients' collective efforts and their willingness to contribute local data. However, due to privacy concerns and the costs of data collection and model training, clients may not always contribute all the data they possess, which would negatively affect the performance of the global model. This paper presents an incentive mechanism that encourages clients to contribute as much data as they can obtain. Unlike previous incentive mechanisms, our approach does not monetize data. Instead, we implicitly use model performance as a reward, i.e., significant contributors are paid off with better models. We theoretically prove that clients will use as much data as they can possibly possess to participate in federated learning under certain conditions with our incentive mechanism
KNN-enhanced Deep Learning Against Noisy Labels
Dec 08, 2020

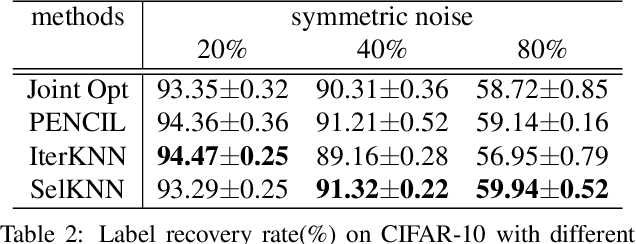
Supervised learning on Deep Neural Networks (DNNs) is data hungry. Optimizing performance of DNN in the presence of noisy labels has become of paramount importance since collecting a large dataset will usually bring in noisy labels. Inspired by the robustness of K-Nearest Neighbors (KNN) against data noise, in this work, we propose to apply deep KNN for label cleanup. Our approach leverages DNNs for feature extraction and KNN for ground-truth label inference. We iteratively train the neural network and update labels to simultaneously proceed towards higher label recovery rate and better classification performance. Experiment results show that under the same setting, our approach outperforms existing label correction methods and achieves better accuracy on multiple datasets, e.g.,76.78% on Clothing1M dataset.