 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThinking in Directivity: Speech Large Language Model for Multi-Talker Directional Speech Recognition
Jun 17, 2025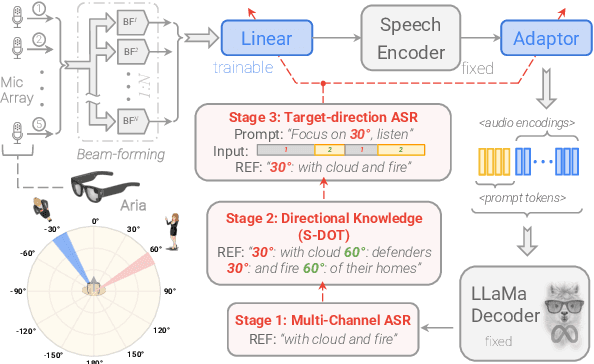
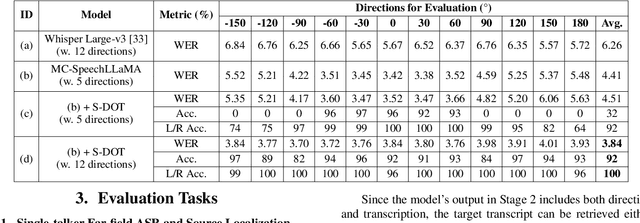
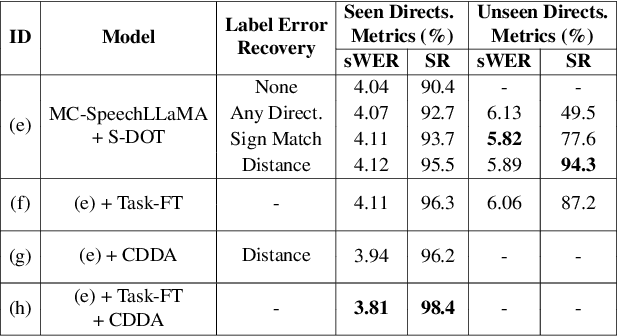
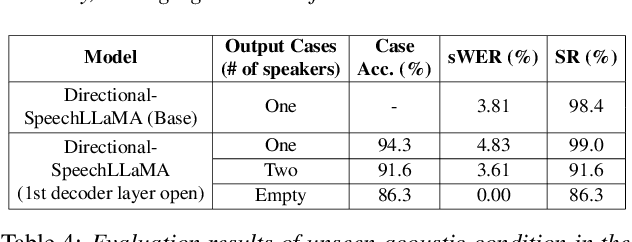
Recent studies have demonstrated that prompting large language models (LLM) with audio encodings enables effective speech recognition capabilities. However, the ability of Speech LLMs to comprehend and process multi-channel audio with spatial cues remains a relatively uninvestigated area of research. In this work, we present directional-SpeechLlama, a novel approach that leverages the microphone array of smart glasses to achieve directional speech recognition, source localization, and bystander cross-talk suppression. To enhance the model's ability to understand directivity, we propose two key techniques: serialized directional output training (S-DOT) and contrastive direction data augmentation (CDDA). Experimental results show that our proposed directional-SpeechLlama effectively captures the relationship between textual cues and spatial audio, yielding strong performance in both speech recognition and source localization tasks.
Effective Integration of KAN for Keyword Spotting
Sep 13, 2024



Keyword spotting (KWS) is an important speech processing component for smart devices with voice assistance capability. In this paper, we investigate if Kolmogorov-Arnold Networks (KAN) can be used to enhance the performance of KWS. We explore various approaches to integrate KAN for a model architecture based on 1D Convolutional Neural Networks (CNN). We find that KAN is effective at modeling high-level features in lower-dimensional spaces, resulting in improved KWS performance when integrated appropriately. The findings shed light on understanding KAN for speech processing tasks and on other modalities for future researchers.
A Study on Robustness to Perturbations for Representations of Environmental Sound
Mar 23, 2022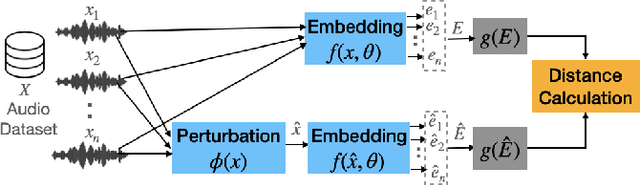
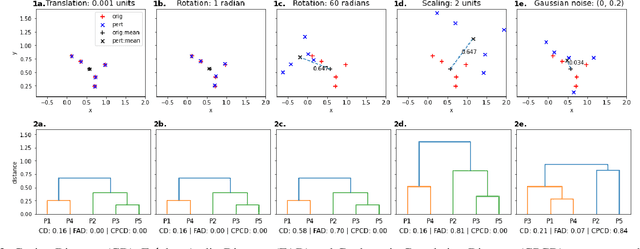
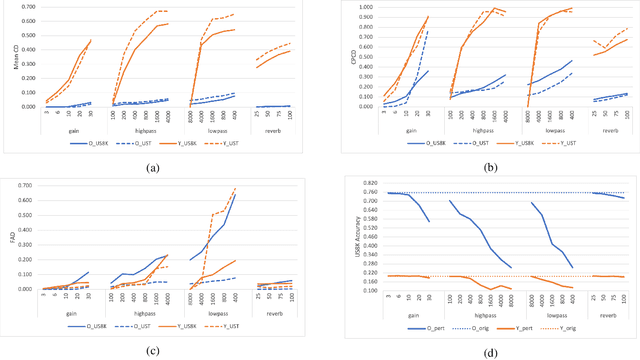
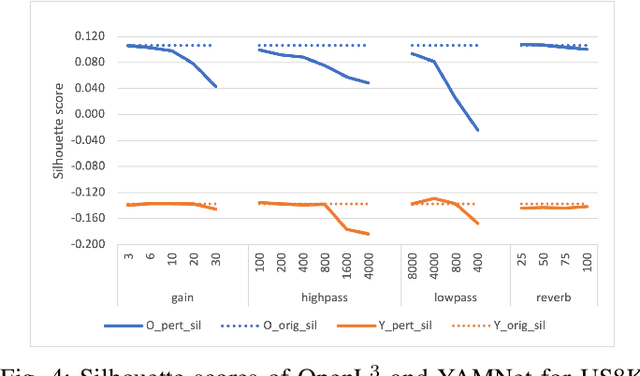
Audio applications involving environmental sound analysis increasingly use general-purpose audio representations, also known as embeddings, for transfer learning. Recently, Holistic Evaluation of Audio Representations (HEAR) evaluated twenty-nine embedding models on nineteen diverse tasks. However, the evaluation's effectiveness depends on the variation already captured within a given dataset. Therefore, for a given data domain, it is unclear how the representations would be affected by the variations caused by myriad microphones' range and acoustic conditions -- commonly known as channel effects. We aim to extend HEAR to evaluate invariance to channel effects in this work. To accomplish this, we imitate channel effects by injecting perturbations to the audio signal and measure the shift in the new (perturbed) embeddings with three distance measures, making the evaluation domain-dependent but not task-dependent. Combined with the downstream performance, it helps us make a more informed prediction of how robust the embeddings are to the channel effects. We evaluate two embeddings -- YAMNet, and OpenL$^3$ on monophonic (UrbanSound8K) and polyphonic (SONYC UST) datasets. We show that one distance measure does not suffice in such task-independent evaluation. Although Fr\'echet Audio Distance (FAD) correlates with the trend of the performance drop in the downstream task most accurately, we show that we need to study this in conjunction with the other distances to get a clear understanding of the overall effect of the perturbation. In terms of the embedding performance, we find OpenL$^3$ to be more robust to YAMNet, which aligns with the HEAR evaluation.
Infrastructure-free, Deep Learned Urban Noise Monitoring at $\sim$100mW
Mar 11, 2022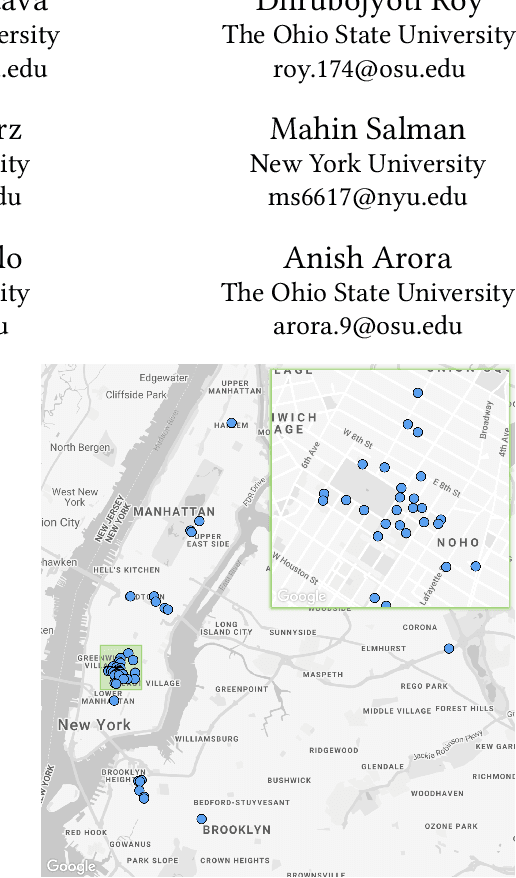
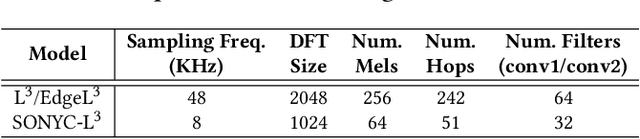
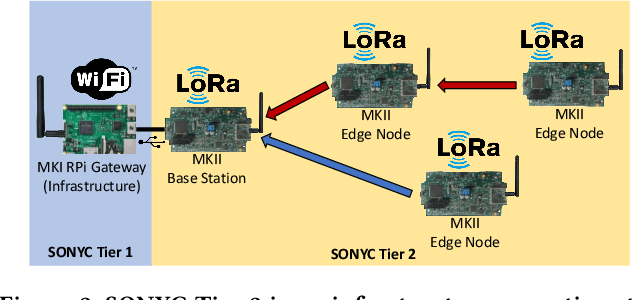
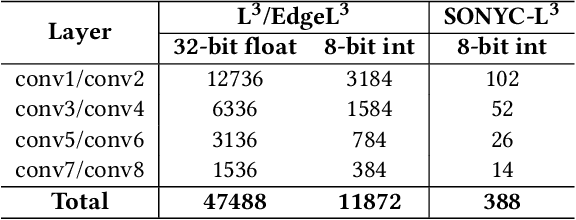
The Sounds of New York City (SONYC) wireless sensor network (WSN) has been fielded in Manhattan and Brooklyn over the past five years, as part of a larger human-in-the-loop cyber-physical control system for monitoring, analyzing, and mitigating urban noise pollution. We describe the evolution of the 2-tier SONYC WSN from an acoustic data collection fabric into a 3-tier in situ noise complaint monitoring WSN, and its current evaluation. The added tier consists of long-range (LoRa), multi-hop networks of a new low-power acoustic mote, MKII ("Mach 2"), that we have designed and fabricated. MKII motes are notable in three ways: First, they advance machine learning capability at mote-scale in this application domain by introducing a real-time Convolutional Neural Network (CNN) based embedding model that is competitive with alternatives while also requiring 10$\times$ lesser training data and $\sim$2 orders of magnitude fewer runtime resources. Second, they are conveniently deployed relatively far from higher-tier base station nodes without assuming power or network infrastructure support at operationally relevant sites (such as construction zones), yielding a relatively low-cost solution. And third, their networking is frequency agile, unlike conventional LoRa networks: it tolerates in a distributed, self-stabilizing way the variable external interference and link fading in the cluttered 902-928MHz ISM band urban environment by dynamically choosing good frequencies using an efficient new method that combines passive and active measurements.
Physics-Guided Problem Decomposition for Scaling Deep Learning of High-dimensional Eigen-Solvers: The Case of Schrödinger's Equation
Feb 15, 2022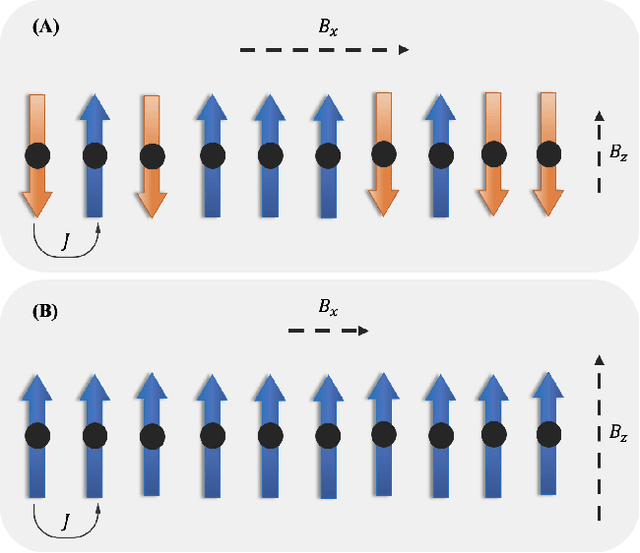

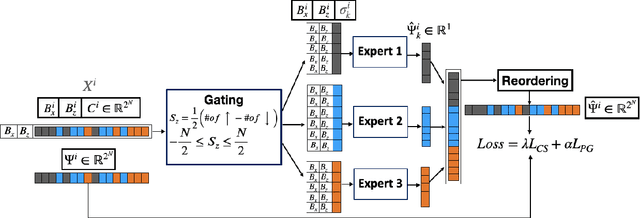
Given their ability to effectively learn non-linear mappings and perform fast inference, deep neural networks (NNs) have been proposed as a viable alternative to traditional simulation-driven approaches for solving high-dimensional eigenvalue equations (HDEs), which are the foundation for many scientific applications. Unfortunately, for the learned models in these scientific applications to achieve generalization, a large, diverse, and preferably annotated dataset is typically needed and is computationally expensive to obtain. Furthermore, the learned models tend to be memory- and compute-intensive primarily due to the size of the output layer. While generalization, especially extrapolation, with scarce data has been attempted by imposing physical constraints in the form of physics loss, the problem of model scalability has remained. In this paper, we alleviate the compute bottleneck in the output layer by using physics knowledge to decompose the complex regression task of predicting the high-dimensional eigenvectors into multiple simpler sub-tasks, each of which are learned by a simple "expert" network. We call the resulting architecture of specialized experts Physics-Guided Mixture-of-Experts (PG-MoE). We demonstrate the efficacy of such physics-guided problem decomposition for the case of the Schr\"{o}dinger's Equation in Quantum Mechanics. Our proposed PG-MoE model predicts the ground-state solution, i.e., the eigenvector that corresponds to the smallest possible eigenvalue. The model is 150x smaller than the network trained to learn the complex task while being competitive in generalization. To improve the generalization of the PG-MoE, we also employ a physics-guided loss function based on variational energy, which by quantum mechanics principles is minimized iff the output is the ground-state solution.
Conformer-Based Self-Supervised Learning for Non-Speech Audio Tasks
Nov 10, 2021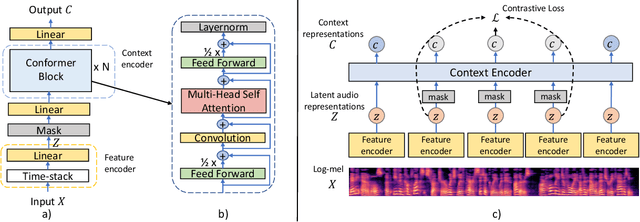
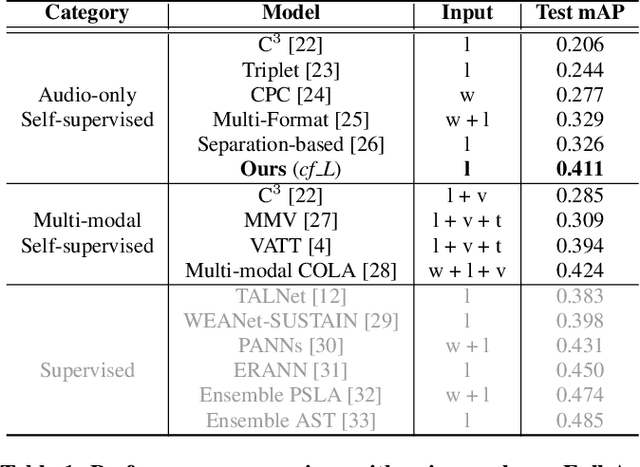

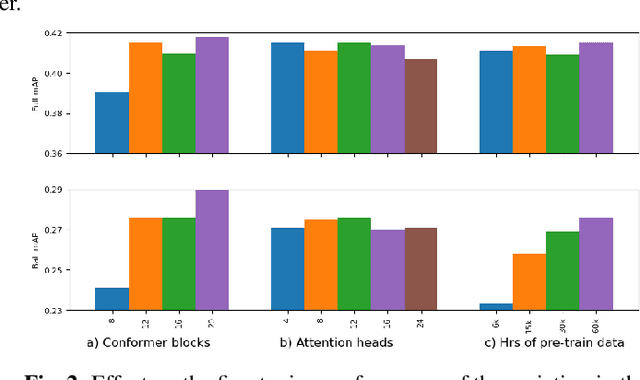
Representation learning from unlabeled data has been of major interest in artificial intelligence research. While self-supervised speech representation learning has been popular in the speech research community, very few works have comprehensively analyzed audio representation learning for non-speech audio tasks. In this paper, we propose a self-supervised audio representation learning method and apply it to a variety of downstream non-speech audio tasks. We combine the well-known wav2vec 2.0 framework, which has shown success in self-supervised learning for speech tasks, with parameter-efficient conformer architectures. Our self-supervised pre-training can reduce the need for labeled data by two-thirds. On the AudioSet benchmark, we achieve a mean average precision (mAP) score of 0.415, which is a new state-of-the-art on this dataset through audio-only self-supervised learning. Our fine-tuned conformers also surpass or match the performance of previous systems pre-trained in a supervised way on several downstream tasks. We further discuss the important design considerations for both pre-training and fine-tuning.
One Size Does Not Fit All: Multi-Scale, Cascaded RNNs for Radar Classification
Sep 06, 2019
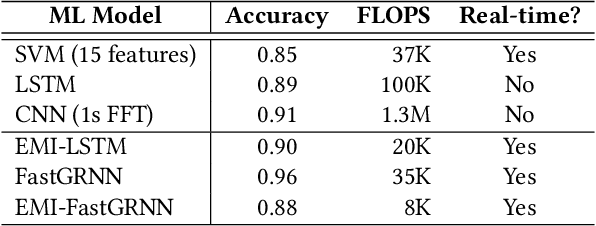


Edge sensing with micro-power pulse-Doppler radars is an emergent domain in monitoring and surveillance with several smart city applications. Existing solutions for the clutter versus multi-source radar classification task are limited in terms of either accuracy or efficiency, and in some cases, struggle with a trade-off between false alarms and recall of sources. We find that this problem can be resolved by learning the classifier across multiple time-scales. We propose a multi-scale, cascaded recurrent neural network architecture, MSC-RNN, comprised of an efficient multi-instance learning (MIL) Recurrent Neural Network (RNN) for clutter discrimination at a lower tier, and a more complex RNN classifier for source classification at the upper tier. By controlling the invocation of the upper RNN with the help of the lower tier conditionally, MSC-RNN achieves an overall accuracy of 0.972. Our approach holistically improves the accuracy and per-class recalls over ML models suitable for radar inferencing. Notably, we outperform cross-domain handcrafted feature engineering with time-domain deep feature learning, while also being up to $\sim$3$\times$ more efficient than a competitive solution.