 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePhysics-Guided Problem Decomposition for Scaling Deep Learning of High-dimensional Eigen-Solvers: The Case of Schrödinger's Equation
Feb 15, 2022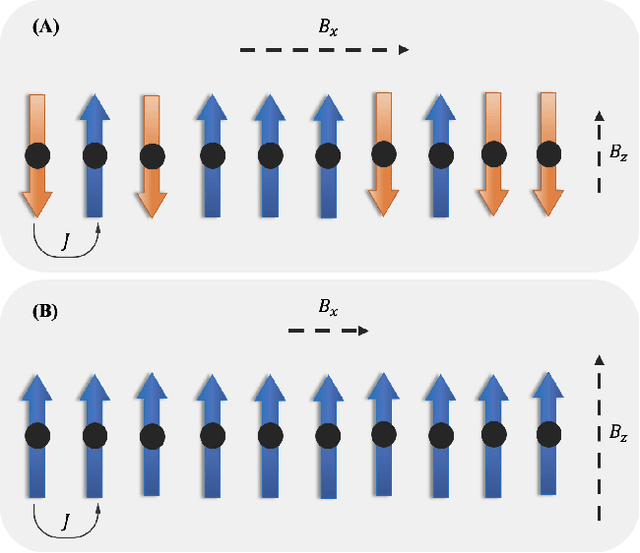

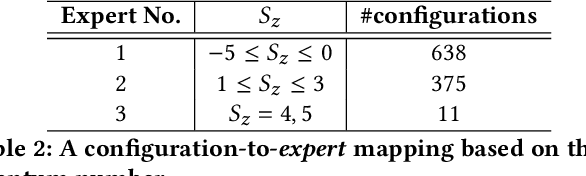
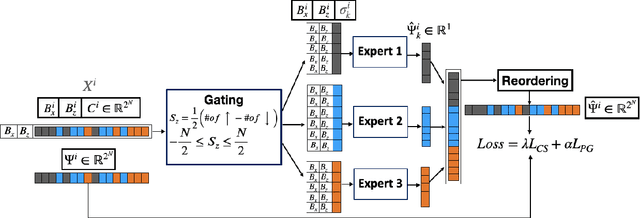
Given their ability to effectively learn non-linear mappings and perform fast inference, deep neural networks (NNs) have been proposed as a viable alternative to traditional simulation-driven approaches for solving high-dimensional eigenvalue equations (HDEs), which are the foundation for many scientific applications. Unfortunately, for the learned models in these scientific applications to achieve generalization, a large, diverse, and preferably annotated dataset is typically needed and is computationally expensive to obtain. Furthermore, the learned models tend to be memory- and compute-intensive primarily due to the size of the output layer. While generalization, especially extrapolation, with scarce data has been attempted by imposing physical constraints in the form of physics loss, the problem of model scalability has remained. In this paper, we alleviate the compute bottleneck in the output layer by using physics knowledge to decompose the complex regression task of predicting the high-dimensional eigenvectors into multiple simpler sub-tasks, each of which are learned by a simple "expert" network. We call the resulting architecture of specialized experts Physics-Guided Mixture-of-Experts (PG-MoE). We demonstrate the efficacy of such physics-guided problem decomposition for the case of the Schr\"{o}dinger's Equation in Quantum Mechanics. Our proposed PG-MoE model predicts the ground-state solution, i.e., the eigenvector that corresponds to the smallest possible eigenvalue. The model is 150x smaller than the network trained to learn the complex task while being competitive in generalization. To improve the generalization of the PG-MoE, we also employ a physics-guided loss function based on variational energy, which by quantum mechanics principles is minimized iff the output is the ground-state solution.