 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBridging Local and Global Knowledge: Cascaded Mixture-of-Experts Learning for Near-Shortest Path Routing
Mar 16, 2026While deep learning models that leverage local features have demonstrated significant potential for near-optimal routing in dense Euclidean graphs, they struggle to generalize well in sparse networks where topological irregularities require broader structural awareness. To address this limitation, we train a Cascaded Mixture of Experts (Ca-MoE) to solve the all-pairs near-shortest path (APNSP) routing problem. Our Ca-MoE is a modular two-tier architecture that supports the decision-making for forwarder selection with lower-tier experts relying on local features and upper-tier experts relying on global features. It performs adaptive inference wherein the upper-tier experts are triggered only when the lower-tier ones do not suffice to achieve adequate decision quality. Computational efficiency is thus achieved by escalating model capacity only when necessitated by topological complexity, and parameter redundancy is avoided. Furthermore, we incorporate an online meta-learning strategy that facilitates independent expert fine-tuning and utilizes a stability-focused update mechanism to prevent catastrophic forgetting as new graph environments are encountered. Experimental evaluations demonstrate that Ca-MoE routing improves accuracy by up to 29.1% in sparse networks compared to single-expert baselines and maintains performance within 1%-6% of the theoretical upper bound across diverse graph densities.
MoCap2Radar: A Spatiotemporal Transformer for Synthesizing Micro-Doppler Radar Signatures from Motion Capture
Nov 14, 2025
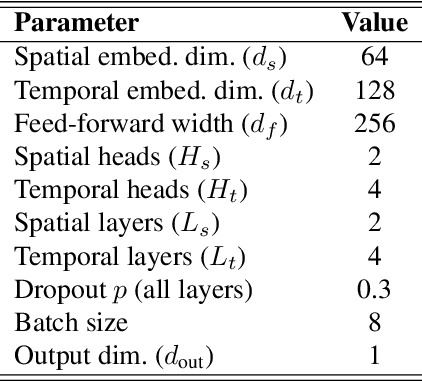
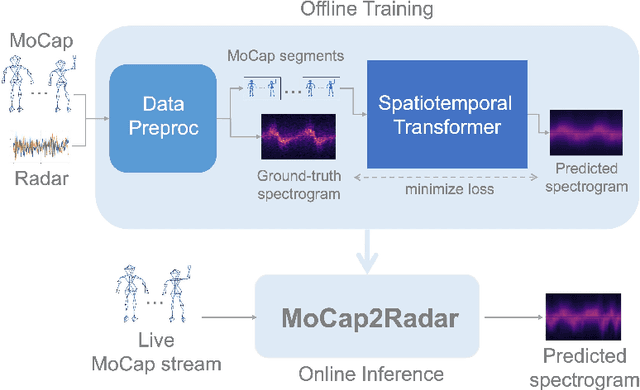

We present a pure machine learning process for synthesizing radar spectrograms from Motion-Capture (MoCap) data. We formulate MoCap-to-spectrogram translation as a windowed sequence-to-sequence task using a transformer-based model that jointly captures spatial relations among MoCap markers and temporal dynamics across frames. Real-world experiments show that the proposed approach produces visually and quantitatively plausible doppler radar spectrograms and achieves good generalizability. Ablation experiments show that the learned model includes both the ability to convert multi-part motion into doppler signatures and an understanding of the spatial relations between different parts of the human body. The result is an interesting example of using transformers for time-series signal processing. It is especially applicable to edge computing and Internet of Things (IoT) radars. It also suggests the ability to augment scarce radar datasets using more abundant MoCap data for training higher-level applications. Finally, it requires far less computation than physics-based methods for generating radar data.
MUDAS: Mote-scale Unsupervised Domain Adaptation in Multi-label Sound Classification
Jun 12, 2025Unsupervised Domain Adaptation (UDA) is essential for adapting machine learning models to new, unlabeled environments where data distribution shifts can degrade performance. Existing UDA algorithms are designed for single-label tasks and rely on significant computational resources, limiting their use in multi-label scenarios and in resource-constrained IoT devices. Overcoming these limitations is particularly challenging in contexts such as urban sound classification, where overlapping sounds and varying acoustics require robust, adaptive multi-label capabilities on low-power, on-device systems. To address these limitations, we introduce Mote-scale Unsupervised Domain Adaptation for Sounds (MUDAS), a UDA framework developed for multi-label sound classification in resource-constrained IoT settings. MUDAS efficiently adapts models by selectively retraining the classifier in situ using high-confidence data, minimizing computational and memory requirements to suit on-device deployment. Additionally, MUDAS incorporates class-specific adaptive thresholds to generate reliable pseudo-labels and applies diversity regularization to improve multi-label classification accuracy. In evaluations on the SONYC Urban Sound Tagging (SONYC-UST) dataset recorded at various New York City locations, MUDAS demonstrates notable improvements in classification accuracy over existing UDA algorithms, achieving good performance in a resource-constrained IoT setting.
PAMLR: A Passive-Active Multi-Armed Bandit-Based Solution for LoRa Channel Allocation
Oct 07, 2024



Achieving low duty cycle operation in low-power wireless networks in urban environments is complicated by the complex and variable dynamics of external interference and fading. We explore the use of reinforcement learning for achieving low power consumption for the task of optimal selection of channels. The learning relies on a hybrid of passive channel sampling for dealing with external interference and active channel sampling for dealing with fading. Our solution, Passive-Active Multi-armed bandit for LoRa (PAMLR, pronounced "Pamela"), balances the two types of samples to achieve energy-efficient channel selection: active channel measurements are tuned to an appropriately low level to update noise thresholds, and to compensate passive channel measurements are tuned to an appropriately high level for selecting the top-most channels from channel exploration using the noise thresholds. The rates of both types of samples are adapted in response to channel dynamics. Based on extensive testing in multiple environments in different cities, we validate that PAMLR can maintain excellent communication quality, as demonstrated by a low SNR regret compared to the optimal channel allocation policy, while substantially minimizing the energy cost associated with channel measurements.
* 10 pages
Learning from A Single Graph is All You Need for Near-Shortest Path Routing in Wireless Networks
Aug 18, 2023

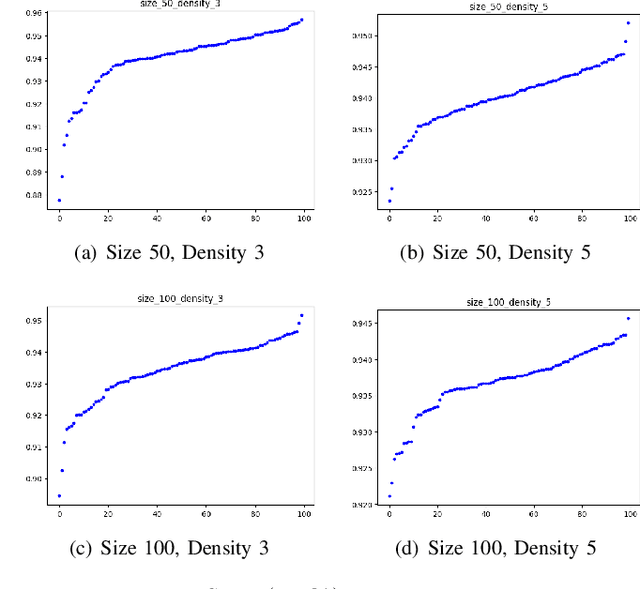

We propose a learning algorithm for local routing policies that needs only a few data samples obtained from a single graph while generalizing to all random graphs in a standard model of wireless networks. We thus solve the all-pairs near-shortest path problem by training deep neural networks (DNNs) that efficiently and scalably learn routing policies that are local, i.e., they only consider node states and the states of neighboring nodes. Remarkably, one of these DNNs we train learns a policy that exactly matches the performance of greedy forwarding; another generally outperforms greedy forwarding. Our algorithm design exploits network domain knowledge in several ways: First, in the selection of input features and, second, in the selection of a ``seed graph'' and subsamples from its shortest paths. The leverage of domain knowledge provides theoretical explainability of why the seed graph and node subsampling suffice for learning that is efficient, scalable, and generalizable. Simulation-based results on uniform random graphs with diverse sizes and densities empirically corroborate that using samples generated from a few routing paths in a modest-sized seed graph quickly learns a model that is generalizable across (almost) all random graphs in the wireless network model.
A Study on Robustness to Perturbations for Representations of Environmental Sound
Mar 23, 2022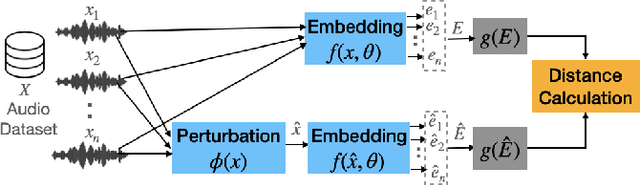
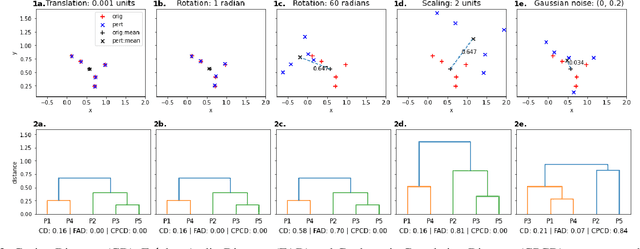
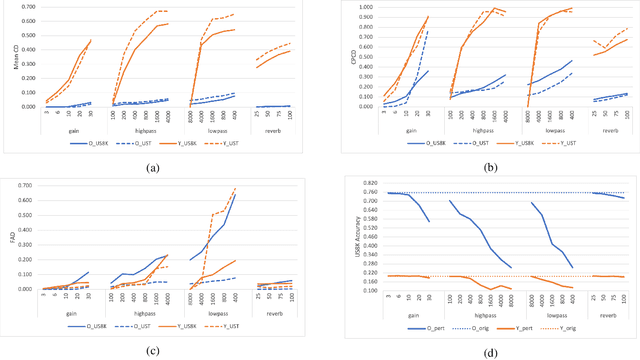
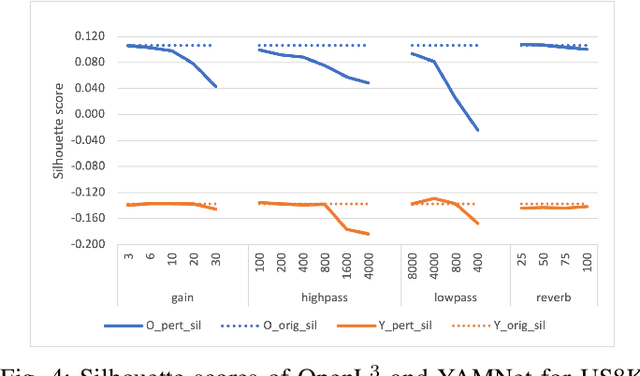
Audio applications involving environmental sound analysis increasingly use general-purpose audio representations, also known as embeddings, for transfer learning. Recently, Holistic Evaluation of Audio Representations (HEAR) evaluated twenty-nine embedding models on nineteen diverse tasks. However, the evaluation's effectiveness depends on the variation already captured within a given dataset. Therefore, for a given data domain, it is unclear how the representations would be affected by the variations caused by myriad microphones' range and acoustic conditions -- commonly known as channel effects. We aim to extend HEAR to evaluate invariance to channel effects in this work. To accomplish this, we imitate channel effects by injecting perturbations to the audio signal and measure the shift in the new (perturbed) embeddings with three distance measures, making the evaluation domain-dependent but not task-dependent. Combined with the downstream performance, it helps us make a more informed prediction of how robust the embeddings are to the channel effects. We evaluate two embeddings -- YAMNet, and OpenL$^3$ on monophonic (UrbanSound8K) and polyphonic (SONYC UST) datasets. We show that one distance measure does not suffice in such task-independent evaluation. Although Fr\'echet Audio Distance (FAD) correlates with the trend of the performance drop in the downstream task most accurately, we show that we need to study this in conjunction with the other distances to get a clear understanding of the overall effect of the perturbation. In terms of the embedding performance, we find OpenL$^3$ to be more robust to YAMNet, which aligns with the HEAR evaluation.
Infrastructure-free, Deep Learned Urban Noise Monitoring at $\sim$100mW
Mar 11, 2022
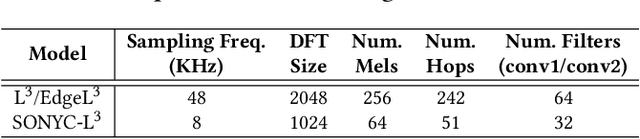
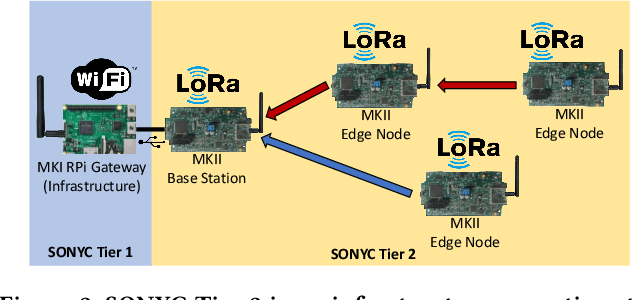
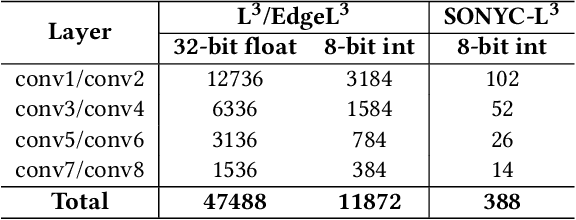
The Sounds of New York City (SONYC) wireless sensor network (WSN) has been fielded in Manhattan and Brooklyn over the past five years, as part of a larger human-in-the-loop cyber-physical control system for monitoring, analyzing, and mitigating urban noise pollution. We describe the evolution of the 2-tier SONYC WSN from an acoustic data collection fabric into a 3-tier in situ noise complaint monitoring WSN, and its current evaluation. The added tier consists of long-range (LoRa), multi-hop networks of a new low-power acoustic mote, MKII ("Mach 2"), that we have designed and fabricated. MKII motes are notable in three ways: First, they advance machine learning capability at mote-scale in this application domain by introducing a real-time Convolutional Neural Network (CNN) based embedding model that is competitive with alternatives while also requiring 10$\times$ lesser training data and $\sim$2 orders of magnitude fewer runtime resources. Second, they are conveniently deployed relatively far from higher-tier base station nodes without assuming power or network infrastructure support at operationally relevant sites (such as construction zones), yielding a relatively low-cost solution. And third, their networking is frequency agile, unlike conventional LoRa networks: it tolerates in a distributed, self-stabilizing way the variable external interference and link fading in the cluttered 902-928MHz ISM band urban environment by dynamically choosing good frequencies using an efficient new method that combines passive and active measurements.
Physics-Guided Problem Decomposition for Scaling Deep Learning of High-dimensional Eigen-Solvers: The Case of Schrödinger's Equation
Feb 15, 2022

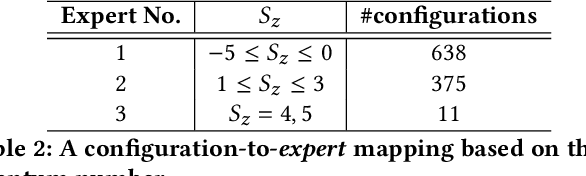
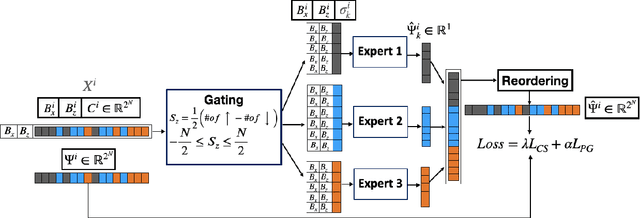
Given their ability to effectively learn non-linear mappings and perform fast inference, deep neural networks (NNs) have been proposed as a viable alternative to traditional simulation-driven approaches for solving high-dimensional eigenvalue equations (HDEs), which are the foundation for many scientific applications. Unfortunately, for the learned models in these scientific applications to achieve generalization, a large, diverse, and preferably annotated dataset is typically needed and is computationally expensive to obtain. Furthermore, the learned models tend to be memory- and compute-intensive primarily due to the size of the output layer. While generalization, especially extrapolation, with scarce data has been attempted by imposing physical constraints in the form of physics loss, the problem of model scalability has remained. In this paper, we alleviate the compute bottleneck in the output layer by using physics knowledge to decompose the complex regression task of predicting the high-dimensional eigenvectors into multiple simpler sub-tasks, each of which are learned by a simple "expert" network. We call the resulting architecture of specialized experts Physics-Guided Mixture-of-Experts (PG-MoE). We demonstrate the efficacy of such physics-guided problem decomposition for the case of the Schr\"{o}dinger's Equation in Quantum Mechanics. Our proposed PG-MoE model predicts the ground-state solution, i.e., the eigenvector that corresponds to the smallest possible eigenvalue. The model is 150x smaller than the network trained to learn the complex task while being competitive in generalization. To improve the generalization of the PG-MoE, we also employ a physics-guided loss function based on variational energy, which by quantum mechanics principles is minimized iff the output is the ground-state solution.
One Size Does Not Fit All: Multi-Scale, Cascaded RNNs for Radar Classification
Sep 06, 2019
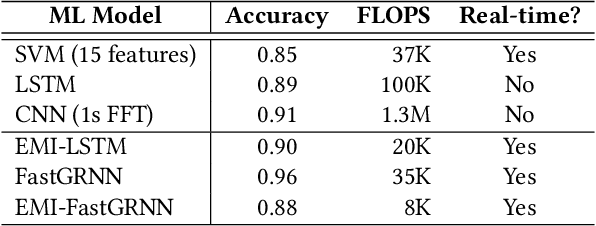


Edge sensing with micro-power pulse-Doppler radars is an emergent domain in monitoring and surveillance with several smart city applications. Existing solutions for the clutter versus multi-source radar classification task are limited in terms of either accuracy or efficiency, and in some cases, struggle with a trade-off between false alarms and recall of sources. We find that this problem can be resolved by learning the classifier across multiple time-scales. We propose a multi-scale, cascaded recurrent neural network architecture, MSC-RNN, comprised of an efficient multi-instance learning (MIL) Recurrent Neural Network (RNN) for clutter discrimination at a lower tier, and a more complex RNN classifier for source classification at the upper tier. By controlling the invocation of the upper RNN with the help of the lower tier conditionally, MSC-RNN achieves an overall accuracy of 0.972. Our approach holistically improves the accuracy and per-class recalls over ML models suitable for radar inferencing. Notably, we outperform cross-domain handcrafted feature engineering with time-domain deep feature learning, while also being up to $\sim$3$\times$ more efficient than a competitive solution.