 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMind the Prompt: Prompting Strategies in Audio Generations for Improving Sound Classification
Apr 04, 2025



This paper investigates the design of effective prompt strategies for generating realistic datasets using Text-To-Audio (TTA) models. We also analyze different techniques for efficiently combining these datasets to enhance their utility in sound classification tasks. By evaluating two sound classification datasets with two TTA models, we apply a range of prompt strategies. Our findings reveal that task-specific prompt strategies significantly outperform basic prompt approaches in data generation. Furthermore, merging datasets generated using different TTA models proves to enhance classification performance more effectively than merely increasing the training dataset size. Overall, our results underscore the advantages of these methods as effective data augmentation techniques using synthetic data.
Learning Audio Concepts from Counterfactual Natural Language
Jan 10, 2024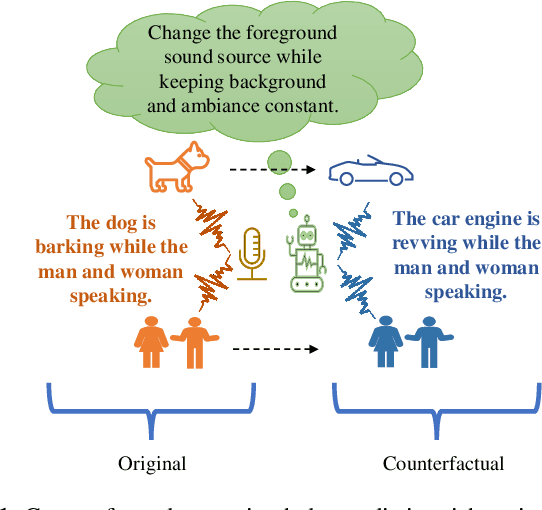
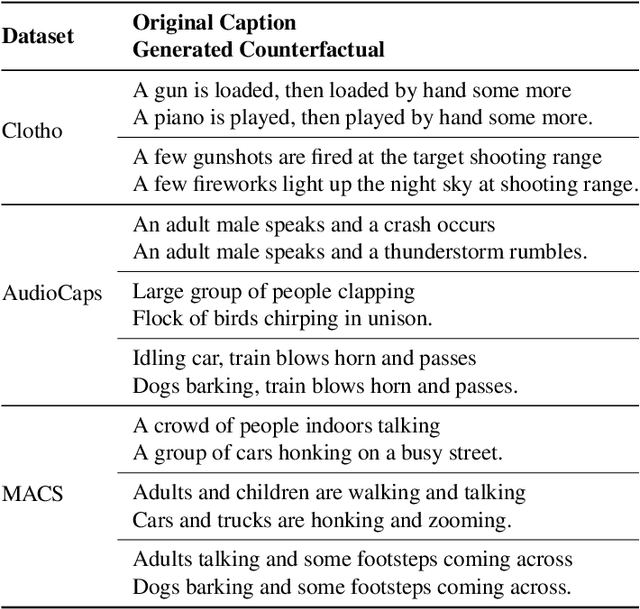

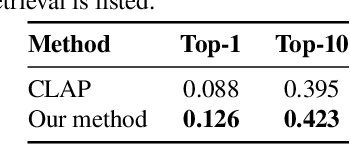
Conventional audio classification relied on predefined classes, lacking the ability to learn from free-form text. Recent methods unlock learning joint audio-text embeddings from raw audio-text pairs describing audio in natural language. Despite recent advancements, there is little exploration of systematic methods to train models for recognizing sound events and sources in alternative scenarios, such as distinguishing fireworks from gunshots at outdoor events in similar situations. This study introduces causal reasoning and counterfactual analysis in the audio domain. We use counterfactual instances and include them in our model across different aspects. Our model considers acoustic characteristics and sound source information from human-annotated reference texts. To validate the effectiveness of our model, we conducted pre-training utilizing multiple audio captioning datasets. We then evaluate with several common downstream tasks, demonstrating the merits of the proposed method as one of the first works leveraging counterfactual information in audio domain. Specifically, the top-1 accuracy in open-ended language-based audio retrieval task increased by more than 43%.
MOSAIC: Learning Unified Multi-Sensory Object Property Representations for Robot Perception
Sep 15, 2023A holistic understanding of object properties across diverse sensory modalities (e.g., visual, audio, and haptic) is essential for tasks ranging from object categorization to complex manipulation. Drawing inspiration from cognitive science studies that emphasize the significance of multi-sensory integration in human perception, we introduce MOSAIC (Multi-modal Object property learning with Self-Attention and Integrated Comprehension), a novel framework designed to facilitate the learning of unified multi-sensory object property representations. While it is undeniable that visual information plays a prominent role, we acknowledge that many fundamental object properties extend beyond the visual domain to encompass attributes like texture, mass distribution, or sounds, which significantly influence how we interact with objects. In MOSAIC, we leverage this profound insight by distilling knowledge from the extensive pre-trained Contrastive Language-Image Pre-training (CLIP) model, aligning these representations not only across vision but also haptic and auditory sensory modalities. Through extensive experiments on a dataset where a humanoid robot interacts with 100 objects across 10 exploratory behaviors, we demonstrate the versatility of MOSAIC in two task families: object categorization and object-fetching tasks. Our results underscore the efficacy of MOSAIC's unified representations, showing competitive performance in category recognition through a simple linear probe setup and excelling in the fetch object task under zero-shot transfer conditions. This work pioneers the application of CLIP-based sensory grounding in robotics, promising a significant leap in multi-sensory perception capabilities for autonomous systems. We have released the code, datasets, and additional results: https://github.com/gtatiya/MOSAIC.
Audio-Text Models Do Not Yet Leverage Natural Language
Mar 19, 2023Multi-modal contrastive learning techniques in the audio-text domain have quickly become a highly active area of research. Most works are evaluated with standard audio retrieval and classification benchmarks assuming that (i) these models are capable of leveraging the rich information contained in natural language, and (ii) current benchmarks are able to capture the nuances of such information. In this work, we show that state-of-the-art audio-text models do not yet really understand natural language, especially contextual concepts such as sequential or concurrent ordering of sound events. Our results suggest that existing benchmarks are not sufficient to assess these models' capabilities to match complex contexts from the audio and text modalities. We propose a Transformer-based architecture and show that, unlike prior work, it is capable of modeling the sequential relationship between sound events in the text and audio, given appropriate benchmark data. We advocate for the collection or generation of additional, diverse, data to allow future research to fully leverage natural language for audio-text modeling.
How to Listen? Rethinking Visual Sound Localization
Apr 11, 2022
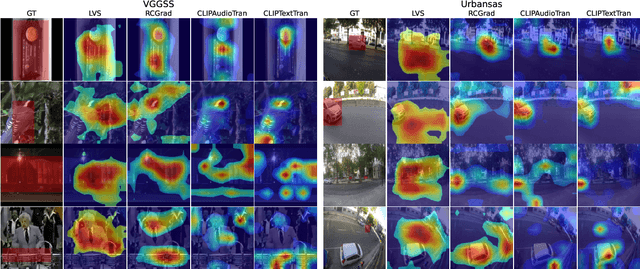

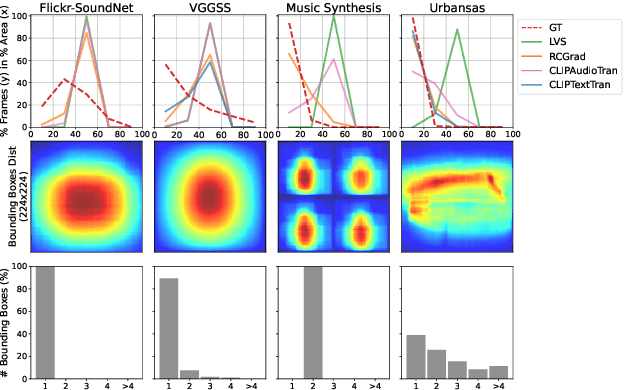
Localizing visual sounds consists on locating the position of objects that emit sound within an image. It is a growing research area with potential applications in monitoring natural and urban environments, such as wildlife migration and urban traffic. Previous works are usually evaluated with datasets having mostly a single dominant visible object, and proposed models usually require the introduction of localization modules during training or dedicated sampling strategies, but it remains unclear how these design choices play a role in the adaptability of these methods in more challenging scenarios. In this work, we analyze various model choices for visual sound localization and discuss how their different components affect the model's performance, namely the encoders' architecture, the loss function and the localization strategy. Furthermore, we study the interaction between these decisions, the model performance, and the data, by digging into different evaluation datasets spanning different difficulties and characteristics, and discuss the implications of such decisions in the context of real-world applications. Our code and model weights are open-sourced and made available for further applications.
A Study on Robustness to Perturbations for Representations of Environmental Sound
Mar 23, 2022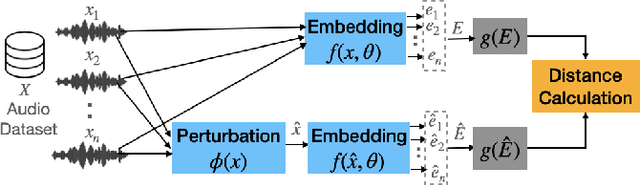
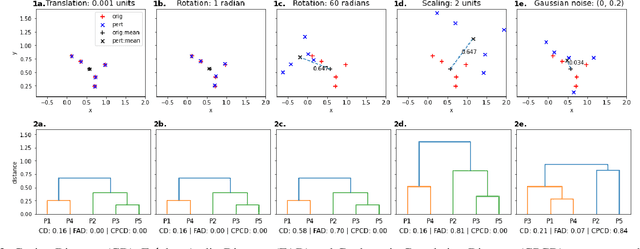
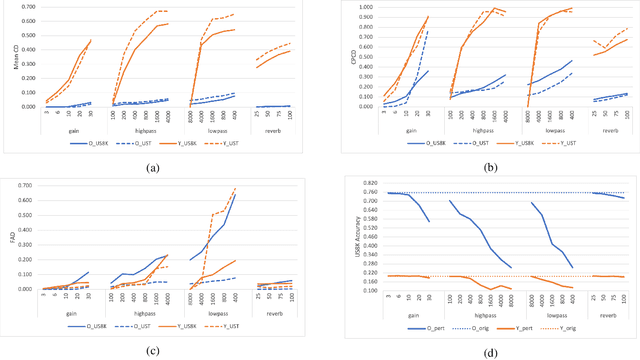
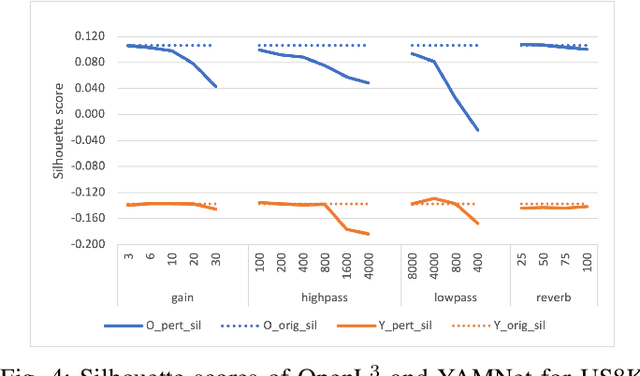
Audio applications involving environmental sound analysis increasingly use general-purpose audio representations, also known as embeddings, for transfer learning. Recently, Holistic Evaluation of Audio Representations (HEAR) evaluated twenty-nine embedding models on nineteen diverse tasks. However, the evaluation's effectiveness depends on the variation already captured within a given dataset. Therefore, for a given data domain, it is unclear how the representations would be affected by the variations caused by myriad microphones' range and acoustic conditions -- commonly known as channel effects. We aim to extend HEAR to evaluate invariance to channel effects in this work. To accomplish this, we imitate channel effects by injecting perturbations to the audio signal and measure the shift in the new (perturbed) embeddings with three distance measures, making the evaluation domain-dependent but not task-dependent. Combined with the downstream performance, it helps us make a more informed prediction of how robust the embeddings are to the channel effects. We evaluate two embeddings -- YAMNet, and OpenL$^3$ on monophonic (UrbanSound8K) and polyphonic (SONYC UST) datasets. We show that one distance measure does not suffice in such task-independent evaluation. Although Fr\'echet Audio Distance (FAD) correlates with the trend of the performance drop in the downstream task most accurately, we show that we need to study this in conjunction with the other distances to get a clear understanding of the overall effect of the perturbation. In terms of the embedding performance, we find OpenL$^3$ to be more robust to YAMNet, which aligns with the HEAR evaluation.
Wav2CLIP: Learning Robust Audio Representations From CLIP
Oct 21, 2021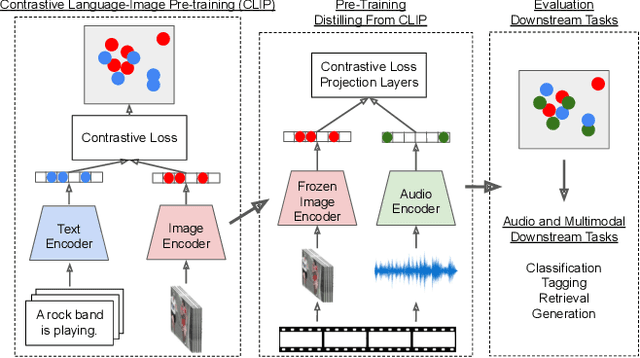
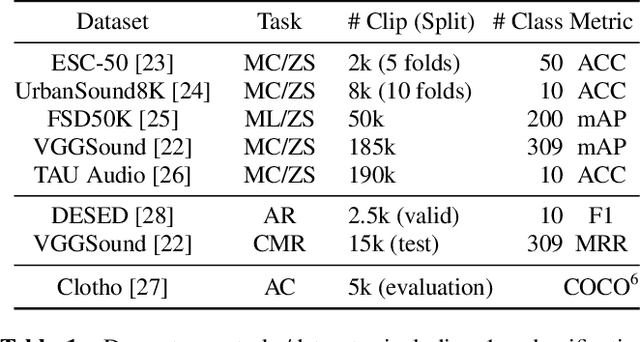
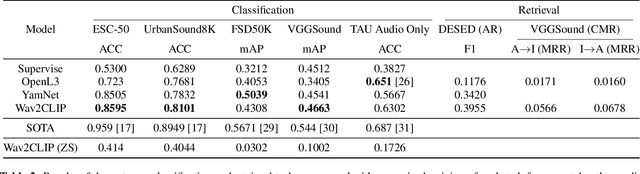
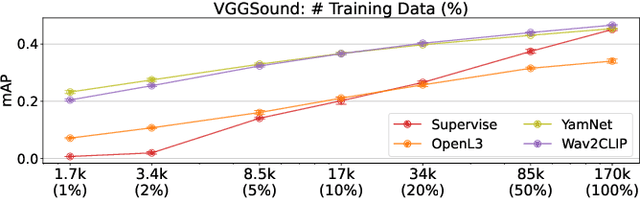
We propose Wav2CLIP, a robust audio representation learning method by distilling from Contrastive Language-Image Pre-training (CLIP). We systematically evaluate Wav2CLIP on a variety of audio tasks including classification, retrieval, and generation, and show that Wav2CLIP can outperform several publicly available pre-trained audio representation algorithms. Wav2CLIP projects audio into a shared embedding space with images and text, which enables multimodal applications such as zero-shot classification, and cross-modal retrieval. Furthermore, Wav2CLIP needs just ~10% of the data to achieve competitive performance on downstream tasks compared with fully supervised models, and is more efficient to pre-train than competing methods as it does not require learning a visual model in concert with an auditory model. Finally, we demonstrate image generation from Wav2CLIP as qualitative assessment of the shared embedding space. Our code and model weights are open sourced and made available for further applications.
Exploring modality-agnostic representations for music classification
Jun 02, 2021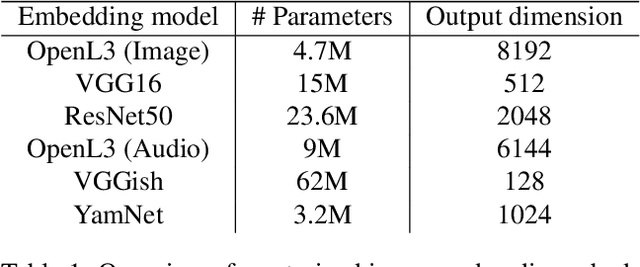
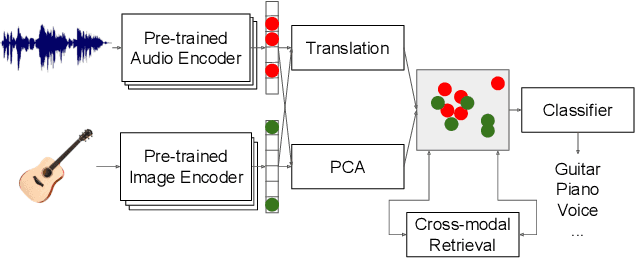
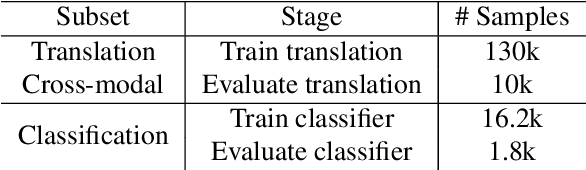
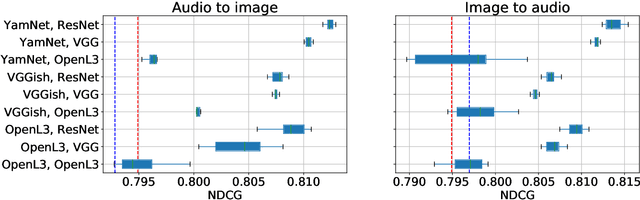
Music information is often conveyed or recorded across multiple data modalities including but not limited to audio, images, text and scores. However, music information retrieval research has almost exclusively focused on single modality recognition, requiring development of separate models for each modality. Some multi-modal works require multiple coexisting modalities given to the model as inputs, constraining the use of these models to the few cases where data from all modalities are available. To the best of our knowledge, no existing model has the ability to take inputs from varying modalities, e.g. images or sounds, and classify them into unified music categories. We explore the use of cross-modal retrieval as a pretext task to learn modality-agnostic representations, which can then be used as inputs to classifiers that are independent of modality. We select instrument classification as an example task for our study as both visual and audio components provide relevant semantic information. We train music instrument classifiers that can take both images or sounds as input, and perform comparably to sound-only or image-only classifiers. Furthermore, we explore the case when there is limited labeled data for a given modality, and the impact in performance by using labeled data from other modalities. We are able to achieve almost 70% of best performing system in a zero-shot setting. We provide a detailed analysis of experimental results to understand the potential and limitations of the approach, and discuss future steps towards modality-agnostic classifiers.
Multi-Task Self-Supervised Pre-Training for Music Classification
Feb 05, 2021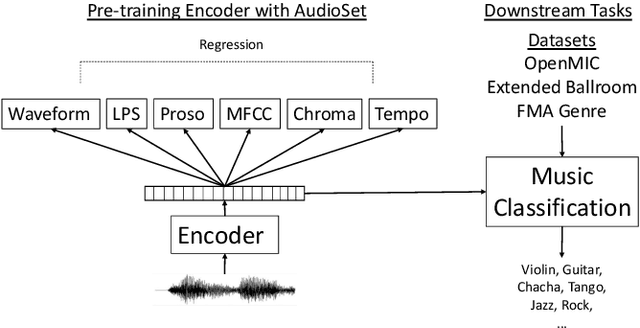
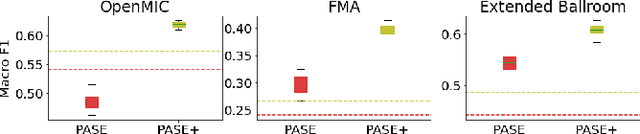
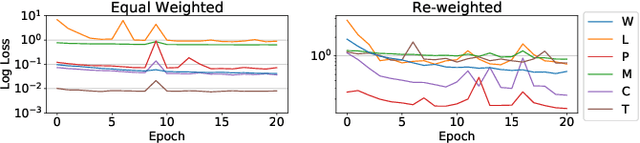
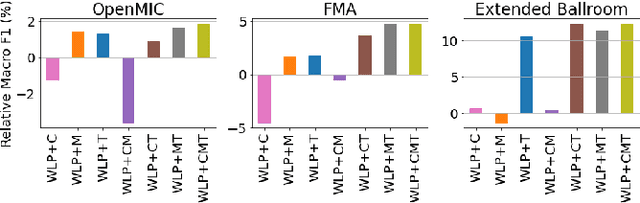
Deep learning is very data hungry, and supervised learning especially requires massive labeled data to work well. Machine listening research often suffers from limited labeled data problem, as human annotations are costly to acquire, and annotations for audio are time consuming and less intuitive. Besides, models learned from labeled dataset often embed biases specific to that particular dataset. Therefore, unsupervised learning techniques become popular approaches in solving machine listening problems. Particularly, a self-supervised learning technique utilizing reconstructions of multiple hand-crafted audio features has shown promising results when it is applied to speech domain such as emotion recognition and automatic speech recognition (ASR). In this paper, we apply self-supervised and multi-task learning methods for pre-training music encoders, and explore various design choices including encoder architectures, weighting mechanisms to combine losses from multiple tasks, and worker selections of pretext tasks. We investigate how these design choices interact with various downstream music classification tasks. We find that using various music specific workers altogether with weighting mechanisms to balance the losses during pre-training helps improve and generalize to the downstream tasks.
SONYC-UST-V2: An Urban Sound Tagging Dataset with Spatiotemporal Context
Sep 11, 2020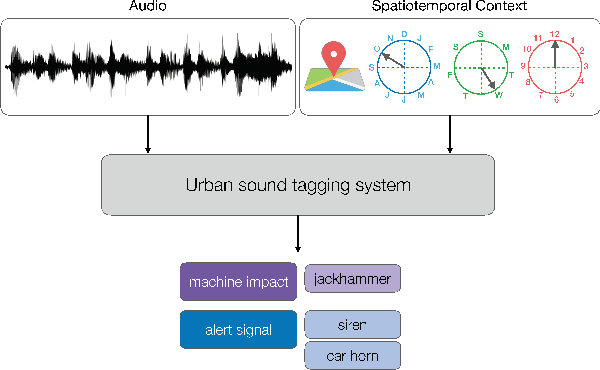
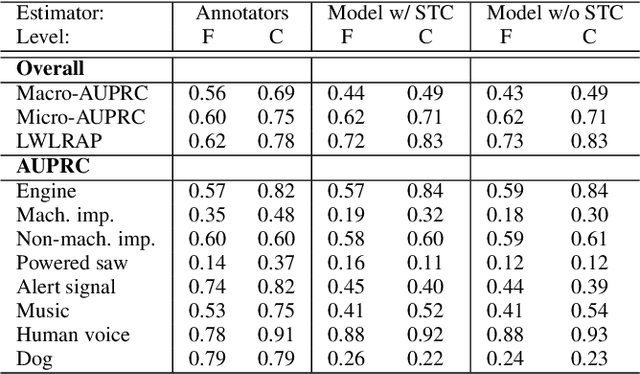
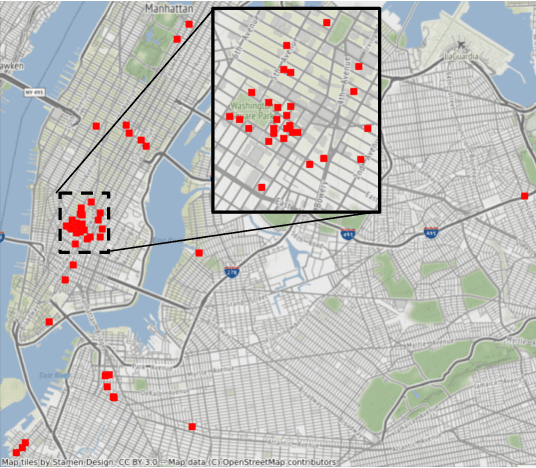
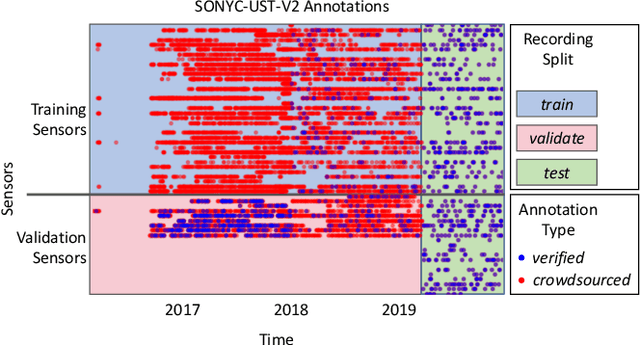
We present SONYC-UST-V2, a dataset for urban sound tagging with spatiotemporal information. This dataset is aimed for the development and evaluation of machine listening systems for real-world urban noise monitoring. While datasets of urban recordings are available, this dataset provides the opportunity to investigate how spatiotemporal metadata can aid in the prediction of urban sound tags. SONYC-UST-V2 consists of 18510 audio recordings from the "Sounds of New York City" (SONYC) acoustic sensor network, including the timestamp of audio acquisition and location of the sensor. The dataset contains annotations by volunteers from the Zooniverse citizen science platform, as well as a two-stage verification with our team. In this article, we describe our data collection procedure and propose evaluation metrics for multilabel classification of urban sound tags. We report the results of a simple baseline model that exploits spatiotemporal information.