 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLearning Audio Concepts from Counterfactual Natural Language
Paper and Code
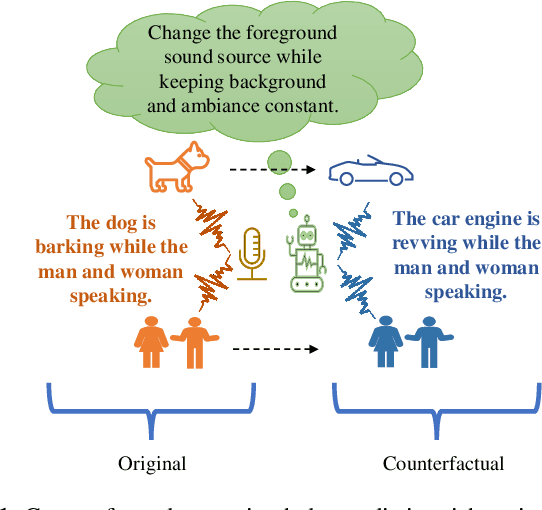
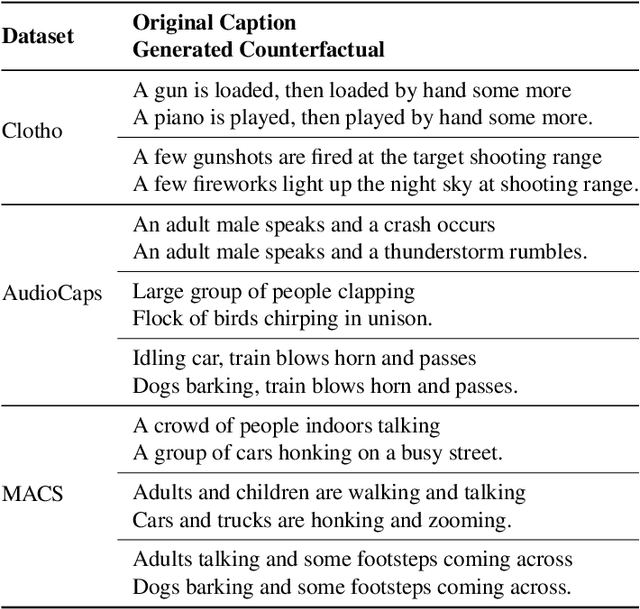

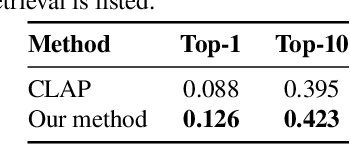
Conventional audio classification relied on predefined classes, lacking the ability to learn from free-form text. Recent methods unlock learning joint audio-text embeddings from raw audio-text pairs describing audio in natural language. Despite recent advancements, there is little exploration of systematic methods to train models for recognizing sound events and sources in alternative scenarios, such as distinguishing fireworks from gunshots at outdoor events in similar situations. This study introduces causal reasoning and counterfactual analysis in the audio domain. We use counterfactual instances and include them in our model across different aspects. Our model considers acoustic characteristics and sound source information from human-annotated reference texts. To validate the effectiveness of our model, we conducted pre-training utilizing multiple audio captioning datasets. We then evaluate with several common downstream tasks, demonstrating the merits of the proposed method as one of the first works leveraging counterfactual information in audio domain. Specifically, the top-1 accuracy in open-ended language-based audio retrieval task increased by more than 43%.