 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIntegrating Lagrangian Neural Networks into the Dyna Framework for Reinforcement Learning
Mar 09, 2026Model-based reinforcement learning (MBRL) is sample-efficient but depends on the accuracy of the learned dynamics, which are often modeled using black-box methods that do not adhere to physical laws. Those methods tend to produce inaccurate predictions when presented with data that differ from the original training set. In this work, we employ Lagrangian neural networks (LNNs), which enforce an underlying Lagrangian structure to train the model within a Dyna-based MBRL framework. Furthermore, we train the LNN using stochastic gradient-based and state-estimation-based optimizers to learn the network's weights. The state-estimation-based method converges faster than the stochastic gradient-based method during neural network training. Simulation results are provided to illustrate the effectiveness of the proposed LNN-based Dyna framework for MBRL.
Statistical Linear Regression Approach to Kalman Filtering and Smoothing under Cyber-Attacks
Apr 11, 2025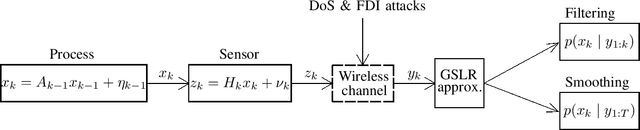
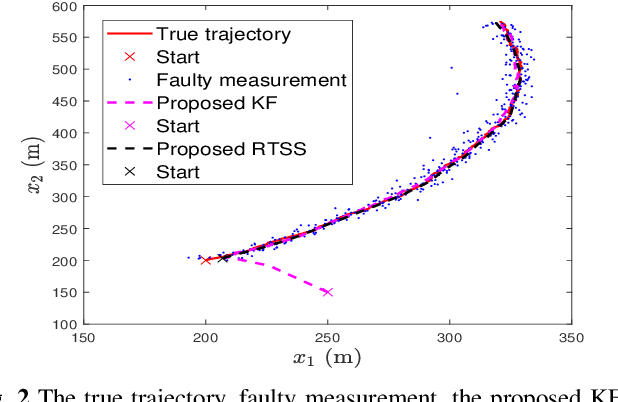
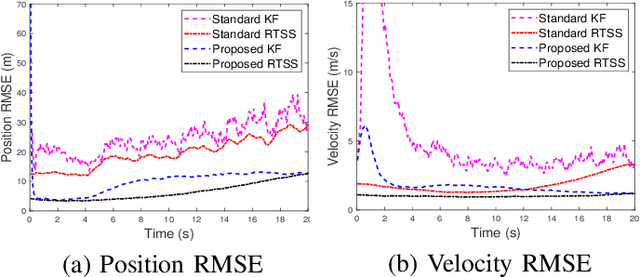
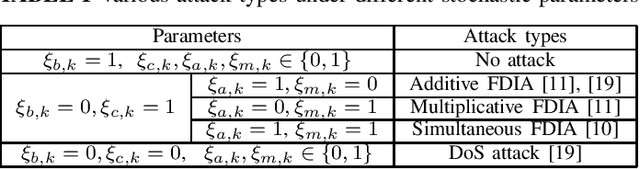
Remote state estimation in cyber-physical systems is often vulnerable to cyber-attacks due to wireless connections between sensors and computing units. In such scenarios, adversaries compromise the system by injecting false data or blocking measurement transmissions via denial-of-service attacks, distorting sensor readings. This paper develops a Kalman filter and Rauch--Tung--Striebel (RTS) smoother for linear stochastic state-space models subject to cyber-attacked measurements. We approximate the faulty measurement model via generalized statistical linear regression (GSLR). The GSLR-based approximated measurement model is then used to develop a Kalman filter and RTS smoother for the problem. The effectiveness of the proposed algorithms under cyber-attacks is demonstrated through a simulated aircraft tracking experiment.
Gaussian Integral based Bayesian Smoother
Jan 12, 2025This work introduces the Gaussian integration to address a smoothing problem of a nonlinear stochastic state space model. The probability densities of states at each time instant are assumed to be Gaussian, and their means and covariances are evaluated by utilizing the odd-even properties of Gaussian integral, which are further utilized to realize Rauch-Tung-Striebel (RTS) smoothing expressions. Given that the Gaussian integration provides an exact solution for the integral of a polynomial function over a Gaussian probability density function, it is anticipated to provide more accurate results than other existing Gaussian approximation-based smoothers such as extended Kalman, cubature Kalman, and unscented Kalman smoothers, especially when polynomial types of nonlinearity are present in the state space models. The developed smoothing algorithm is applied to the Van der Pol oscillator, where the nonlinearity associated with their dynamics is represented using polynomial functions. Simulation results are provided to demonstrate the superiority of the proposed algorithm.
High-Fidelity Audio Compression with Improved RVQGAN
Jun 11, 2023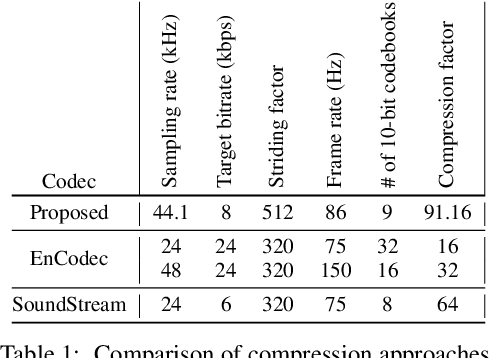
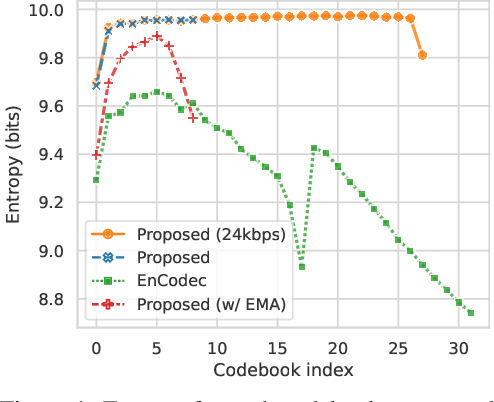
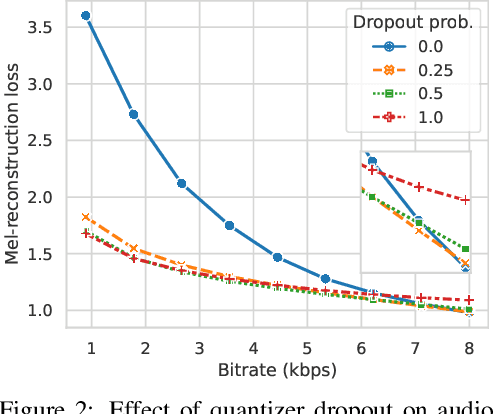
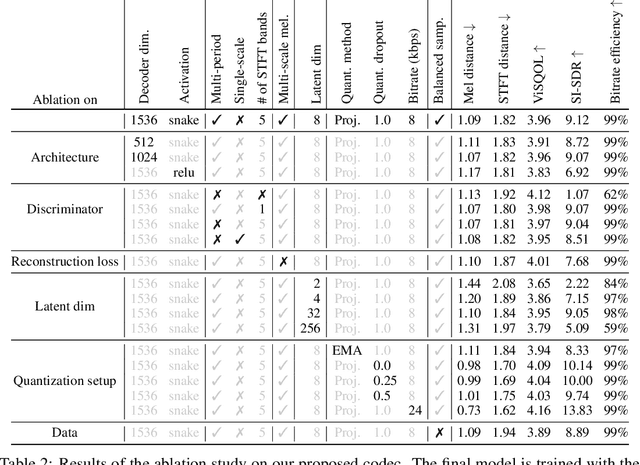
Language models have been successfully used to model natural signals, such as images, speech, and music. A key component of these models is a high quality neural compression model that can compress high-dimensional natural signals into lower dimensional discrete tokens. To that end, we introduce a high-fidelity universal neural audio compression algorithm that achieves ~90x compression of 44.1 KHz audio into tokens at just 8kbps bandwidth. We achieve this by combining advances in high-fidelity audio generation with better vector quantization techniques from the image domain, along with improved adversarial and reconstruction losses. We compress all domains (speech, environment, music, etc.) with a single universal model, making it widely applicable to generative modeling of all audio. We compare with competing audio compression algorithms, and find our method outperforms them significantly. We provide thorough ablations for every design choice, as well as open-source code and trained model weights. We hope our work can lay the foundation for the next generation of high-fidelity audio modeling.
Tracking an Underwater Target with Unknown Measurement Noise Statistics Using Variational Bayesian Filters
May 15, 2023This paper considers a bearings-only tracking problem using noisy measurements of unknown noise statistics from a passive sensor. It is assumed that the process and measurement noise follows the Gaussian distribution where the measurement noise has an unknown non-zero mean and unknown covariance. Here an adaptive nonlinear filtering technique is proposed where the joint distribution of the measurement noise mean and its covariance are considered to be following normal inverse Wishart distribution (NIW). Using the variational Bayesian (VB) method the estimation technique is derived with optimized tuning parameters i.e, the confidence parameter and the initial degree of freedom of the measurement noise mean and the covariance, respectively. The proposed filtering technique is compared with the adaptive filtering techniques based on maximum likelihood and maximum aposteriori in terms of root mean square error in position and velocity, bias norm, average normalized estimation error squared, percentage of track loss, and relative execution time. Both adaptive filtering techniques are implemented using the traditional Gaussian approximate filters and are applied to a bearings-only tracking problem illustrated with moderately nonlinear and highly nonlinear scenarios to track a target following a nearly straight line path. Two cases are considered for each scenario, one when the measurement noise covariance is static and another when the measurement noise covariance is varying linearly with the distance between the target and the ownship. In this work, the proposed adaptive filters using the VB approach are found to be superior to their corresponding adaptive filters based on the maximum aposteriori and the maximum likelihood at the expense of higher computation cost.
Parametric Scaling of Preprocessing assisted U-net Architecture for Improvised Retinal Vessel Segmentation
Mar 18, 2022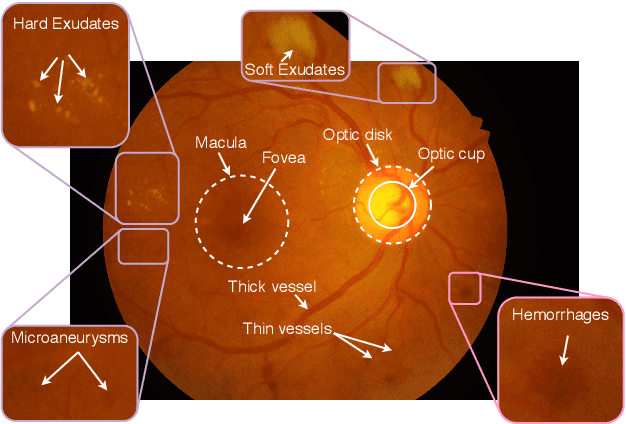
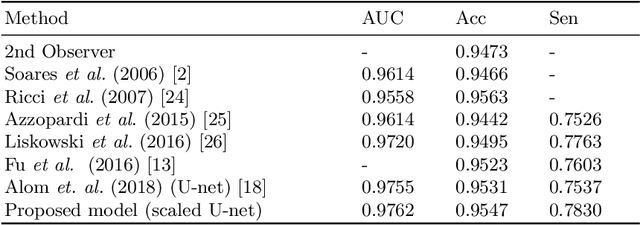
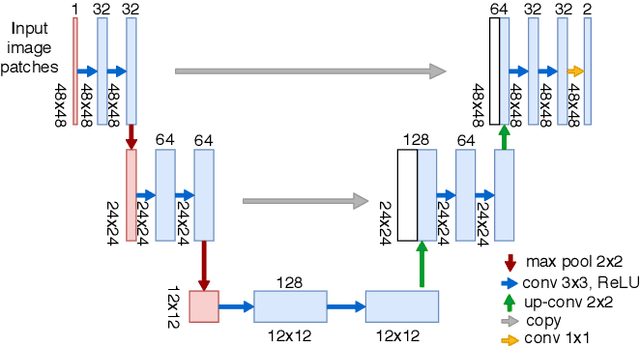

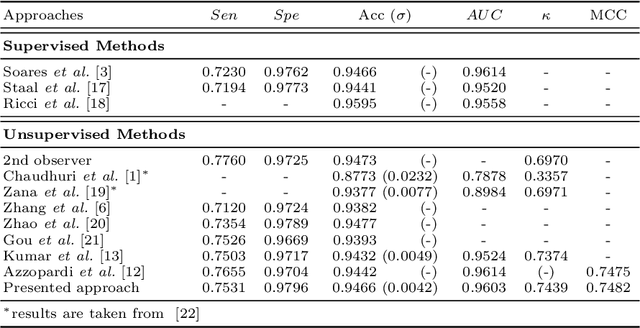
Extracting blood vessels from retinal fundus images plays a decisive role in diagnosing the progression in pertinent diseases. In medical image analysis, vessel extraction is a semantic binary segmentation problem, where blood vasculature needs to be extracted from the background. Here, we present an image enhancement technique based on the morphological preprocessing coupled with a scaled U-net architecture. Despite a relatively less number of trainable network parameters, the scaled version of U-net architecture provides better performance compare to other methods in the domain. We validated the proposed method on retinal fundus images from the DRIVE database. A significant improvement as compared to the other algorithms in the domain, in terms of the area under ROC curve (>0.9762) and classification accuracy (>95.47%) are evident from the results. Furthermore, the proposed method is resistant to the central vessel reflex while sensitive to detect blood vessels in the presence of background items viz. exudates, optic disc, and fovea.
Application of Top-hat Transformation for Enhanced Blood Vessel Extraction
Mar 18, 2022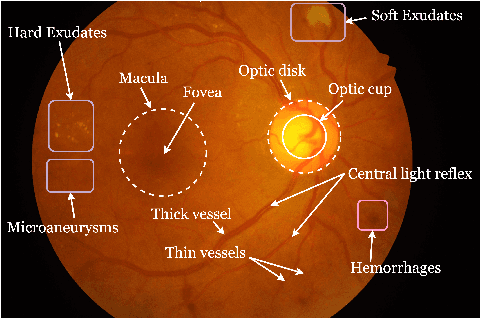
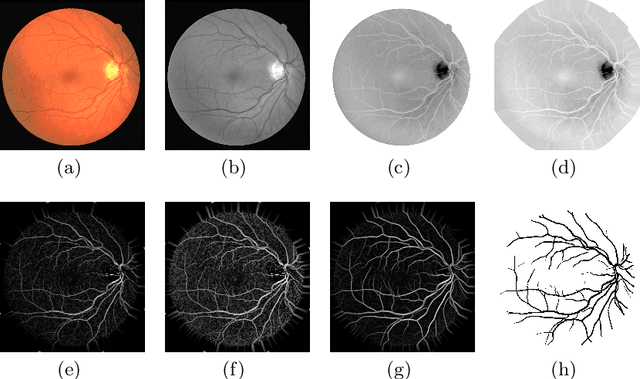
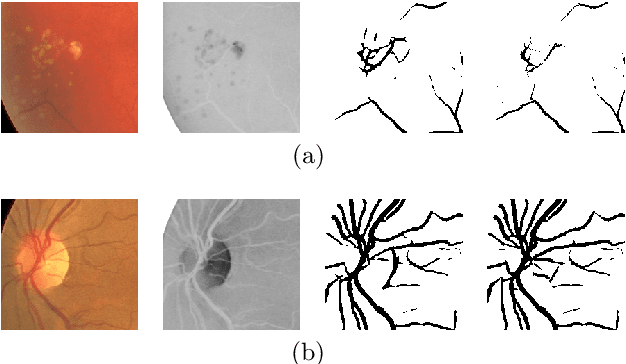
In the medical domain, different computer-aided diagnosis systems have been proposed to extract blood vessels from retinal fundus images for the clinical treatment of vascular diseases. Accurate extraction of blood vessels from the fundus images using a computer-generated method can help the clinician to produce timely and accurate reports for the patient suffering from these diseases. In this article, we integrate top-hat based preprocessing approach with fine-tuned B-COSFIRE filter to achieve more accurate segregation of blood vessel pixels from the background. The use of top-hat transformation in the preprocessing stage enhances the efficacy of the algorithm to extract blood vessels in presence of structures like fovea, exudates, haemorrhages, etc. Furthermore, to reduce the false positives, small clusters of blood vessel pixels are removed in the postprocessing stage. Further, we find that the proposed algorithm is more efficient as compared to various modern algorithms reported in the literature.
Pattern Based Multivariable Regression using Deep Learning (PBMR-DP)
Mar 09, 2022
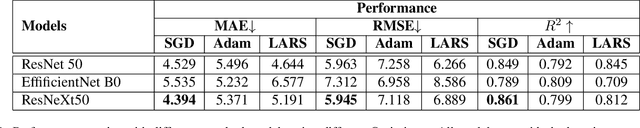
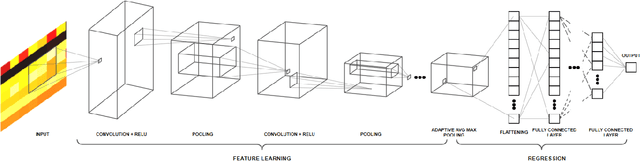

We propose a deep learning methodology for multivariate regression that is based on pattern recognition that triggers fast learning over sensor data. We used a conversion of sensors-to-image which enables us to take advantage of Computer Vision architectures and training processes. In addition to this data preparation methodology, we explore the use of state-of-the-art architectures to generate regression outputs to predict agricultural crop continuous yield information. Finally, we compare with some of the top models reported in MLCAS2021. We found that using a straightforward training process, we were able to accomplish an MAE of 4.394, RMSE of 5.945, and R^2 of 0.861.
Wav2CLIP: Learning Robust Audio Representations From CLIP
Oct 21, 2021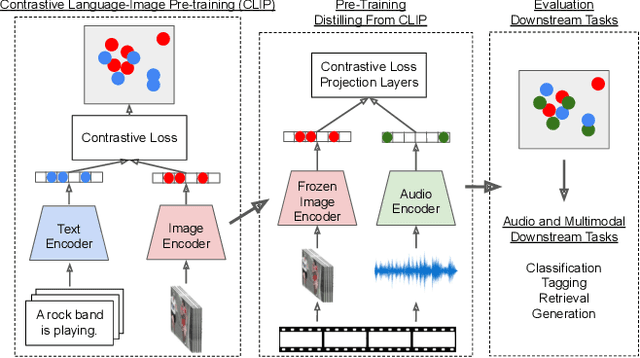
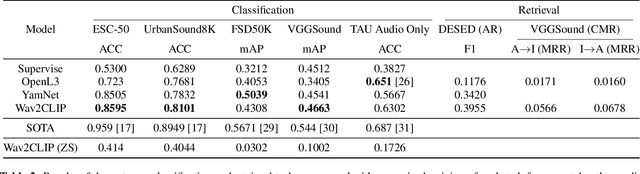
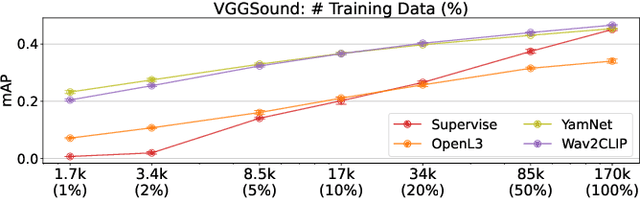
We propose Wav2CLIP, a robust audio representation learning method by distilling from Contrastive Language-Image Pre-training (CLIP). We systematically evaluate Wav2CLIP on a variety of audio tasks including classification, retrieval, and generation, and show that Wav2CLIP can outperform several publicly available pre-trained audio representation algorithms. Wav2CLIP projects audio into a shared embedding space with images and text, which enables multimodal applications such as zero-shot classification, and cross-modal retrieval. Furthermore, Wav2CLIP needs just ~10% of the data to achieve competitive performance on downstream tasks compared with fully supervised models, and is more efficient to pre-train than competing methods as it does not require learning a visual model in concert with an auditory model. Finally, we demonstrate image generation from Wav2CLIP as qualitative assessment of the shared embedding space. Our code and model weights are open sourced and made available for further applications.
Chunked Autoregressive GAN for Conditional Waveform Synthesis
Oct 19, 2021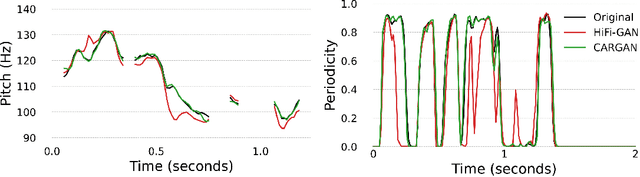

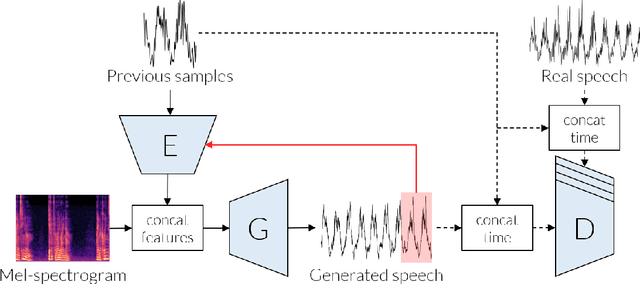
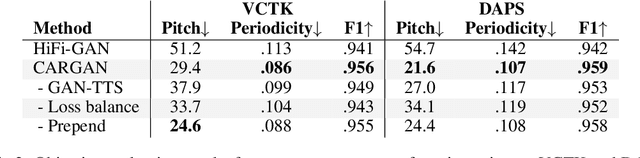
Conditional waveform synthesis models learn a distribution of audio waveforms given conditioning such as text, mel-spectrograms, or MIDI. These systems employ deep generative models that model the waveform via either sequential (autoregressive) or parallel (non-autoregressive) sampling. Generative adversarial networks (GANs) have become a common choice for non-autoregressive waveform synthesis. However, state-of-the-art GAN-based models produce artifacts when performing mel-spectrogram inversion. In this paper, we demonstrate that these artifacts correspond with an inability for the generator to learn accurate pitch and periodicity. We show that simple pitch and periodicity conditioning is insufficient for reducing this error relative to using autoregression. We discuss the inductive bias that autoregression provides for learning the relationship between instantaneous frequency and phase, and show that this inductive bias holds even when autoregressively sampling large chunks of the waveform during each forward pass. Relative to prior state-of- the-art GAN-based models, our proposed model, Chunked Autoregressive GAN (CARGAN) reduces pitch error by 40-60%, reduces training time by 58%, maintains a fast generation speed suitable for real-time or interactive applications, and maintains or improves subjective quality.