 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHigh-Fidelity Audio Compression with Improved RVQGAN
Jun 11, 2023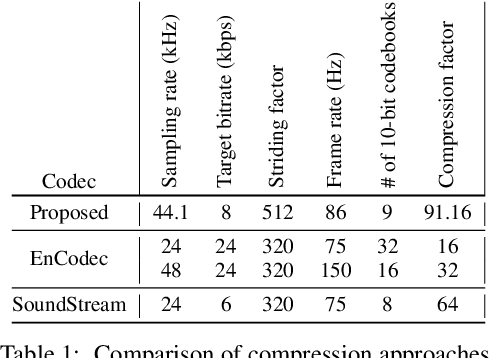
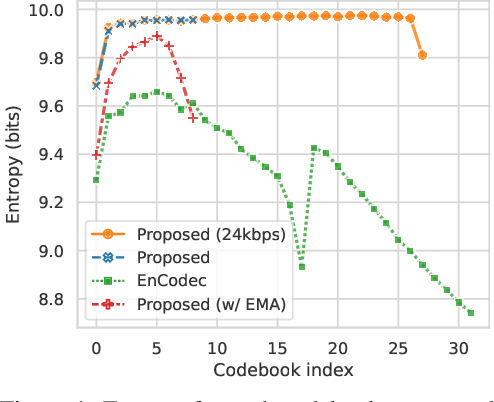
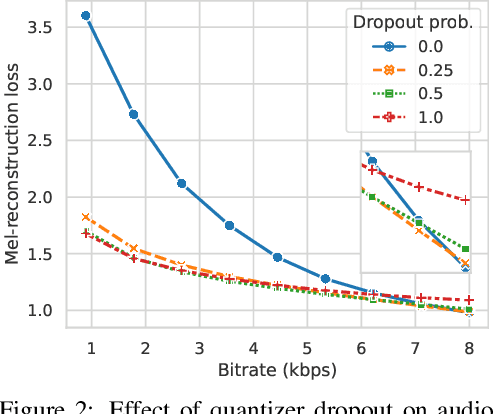
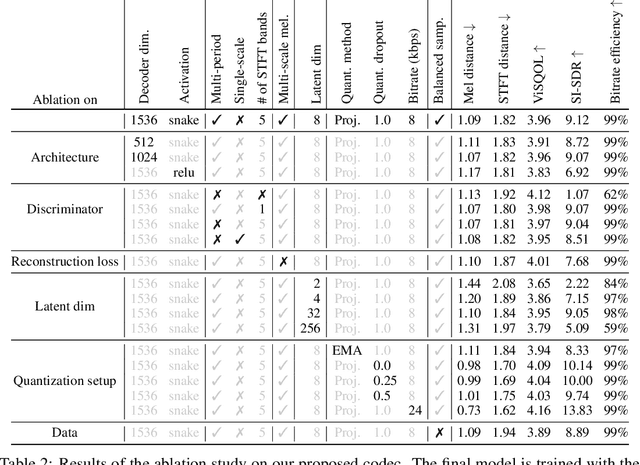
Language models have been successfully used to model natural signals, such as images, speech, and music. A key component of these models is a high quality neural compression model that can compress high-dimensional natural signals into lower dimensional discrete tokens. To that end, we introduce a high-fidelity universal neural audio compression algorithm that achieves ~90x compression of 44.1 KHz audio into tokens at just 8kbps bandwidth. We achieve this by combining advances in high-fidelity audio generation with better vector quantization techniques from the image domain, along with improved adversarial and reconstruction losses. We compress all domains (speech, environment, music, etc.) with a single universal model, making it widely applicable to generative modeling of all audio. We compare with competing audio compression algorithms, and find our method outperforms them significantly. We provide thorough ablations for every design choice, as well as open-source code and trained model weights. We hope our work can lay the foundation for the next generation of high-fidelity audio modeling.
SoundStream: An End-to-End Neural Audio Codec
Jul 07, 2021



We present SoundStream, a novel neural audio codec that can efficiently compress speech, music and general audio at bitrates normally targeted by speech-tailored codecs. SoundStream relies on a model architecture composed by a fully convolutional encoder/decoder network and a residual vector quantizer, which are trained jointly end-to-end. Training leverages recent advances in text-to-speech and speech enhancement, which combine adversarial and reconstruction losses to allow the generation of high-quality audio content from quantized embeddings. By training with structured dropout applied to quantizer layers, a single model can operate across variable bitrates from 3kbps to 18kbps, with a negligible quality loss when compared with models trained at fixed bitrates. In addition, the model is amenable to a low latency implementation, which supports streamable inference and runs in real time on a smartphone CPU. In subjective evaluations using audio at 24kHz sampling rate, SoundStream at 3kbps outperforms Opus at 12kbps and approaches EVS at 9.6kbps. Moreover, we are able to perform joint compression and enhancement either at the encoder or at the decoder side with no additional latency, which we demonstrate through background noise suppression for speech.
Handling Background Noise in Neural Speech Generation
Feb 23, 2021

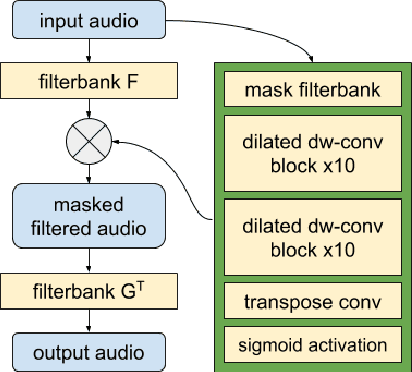

Recent advances in neural-network based generative modeling of speech has shown great potential for speech coding. However, the performance of such models drops when the input is not clean speech, e.g., in the presence of background noise, preventing its use in practical applications. In this paper we examine the reason and discuss methods to overcome this issue. Placing a denoising preprocessing stage when extracting features and target clean speech during training is shown to be the best performing strategy.
Generative Speech Coding with Predictive Variance Regularization
Feb 18, 2021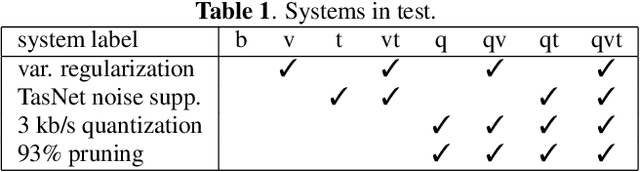
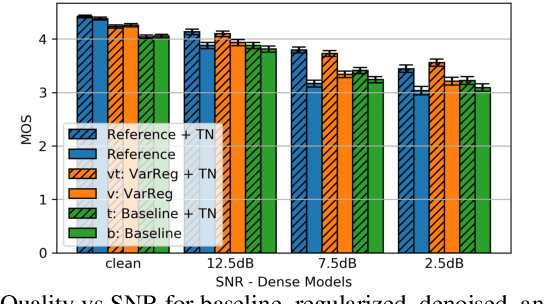
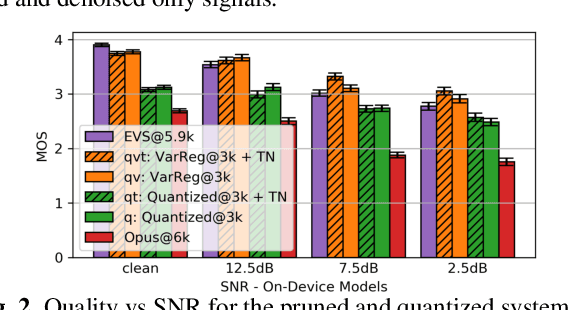
The recent emergence of machine-learning based generative models for speech suggests a significant reduction in bit rate for speech codecs is possible. However, the performance of generative models deteriorates significantly with the distortions present in real-world input signals. We argue that this deterioration is due to the sensitivity of the maximum likelihood criterion to outliers and the ineffectiveness of modeling a sum of independent signals with a single autoregressive model. We introduce predictive-variance regularization to reduce the sensitivity to outliers, resulting in a significant increase in performance. We show that noise reduction to remove unwanted signals can significantly increase performance. We provide extensive subjective performance evaluations that show that our system based on generative modeling provides state-of-the-art coding performance at 3 kb/s for real-world speech signals at reasonable computational complexity.
Low Bit-Rate Speech Coding with VQ-VAE and a WaveNet Decoder
Oct 14, 2019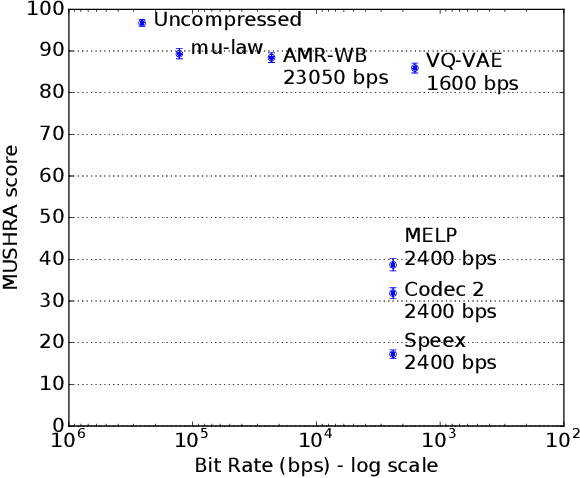
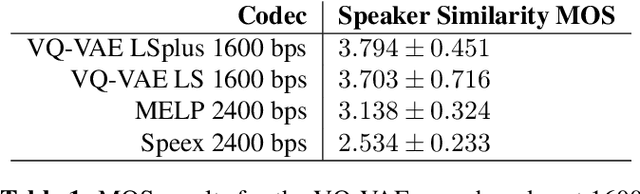
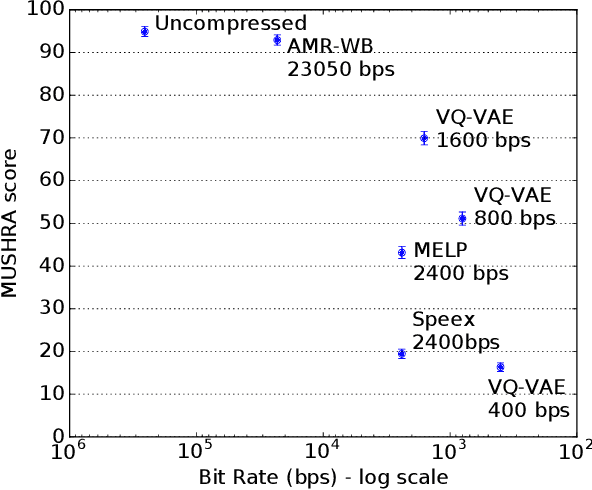
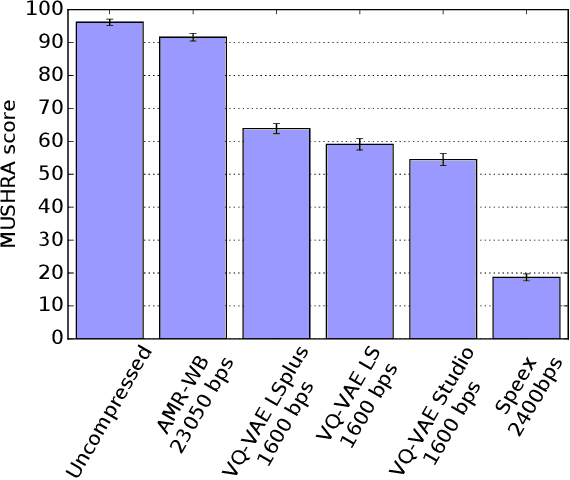
In order to efficiently transmit and store speech signals, speech codecs create a minimally redundant representation of the input signal which is then decoded at the receiver with the best possible perceptual quality. In this work we demonstrate that a neural network architecture based on VQ-VAE with a WaveNet decoder can be used to perform very low bit-rate speech coding with high reconstruction quality. A prosody-transparent and speaker-independent model trained on the LibriSpeech corpus coding audio at 1.6 kbps exhibits perceptual quality which is around halfway between the MELP codec at 2.4 kbps and AMR-WB codec at 23.05 kbps. In addition, when training on high-quality recorded speech with the test speaker included in the training set, a model coding speech at 1.6 kbps produces output of similar perceptual quality to that generated by AMR-WB at 23.05 kbps.
* ICASSP 2019