 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBoNBoN Alignment for Large Language Models and the Sweetness of Best-of-n Sampling
Jun 02, 2024



This paper concerns the problem of aligning samples from large language models to human preferences using best-of-$n$ sampling, where we draw $n$ samples, rank them, and return the best one. We consider two fundamental problems. First: what is the relationship between best-of-$n$ and approaches to alignment that train LLMs to output samples with a high expected reward (e.g., RLHF or DPO)? To answer this, we embed both the best-of-$n$ distribution and the sampling distributions learned by alignment procedures in a common class of tiltings of the base LLM distribution. We then show that, within this class, best-of-$n$ is essentially optimal in terms of the trade-off between win-rate against the base model vs KL distance from the base model. That is, best-of-$n$ is the best choice of alignment distribution if the goal is to maximize win rate. However, best-of-$n$ requires drawing $n$ samples for each inference, a substantial cost. To avoid this, the second problem we consider is how to fine-tune a LLM to mimic the best-of-$n$ sampling distribution. We derive BoNBoN Alignment to achieve this by exploiting the special structure of the best-of-$n$ distribution. Experiments show that BoNBoN alignment yields substantial improvements in producing a model that is preferred to the base policy while minimally affecting off-target aspects.
Low Bit-Rate Speech Coding with VQ-VAE and a WaveNet Decoder
Oct 14, 2019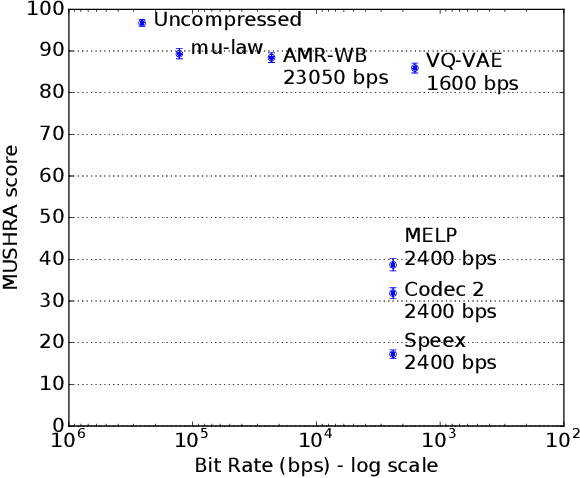
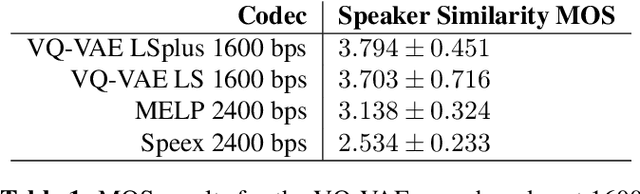
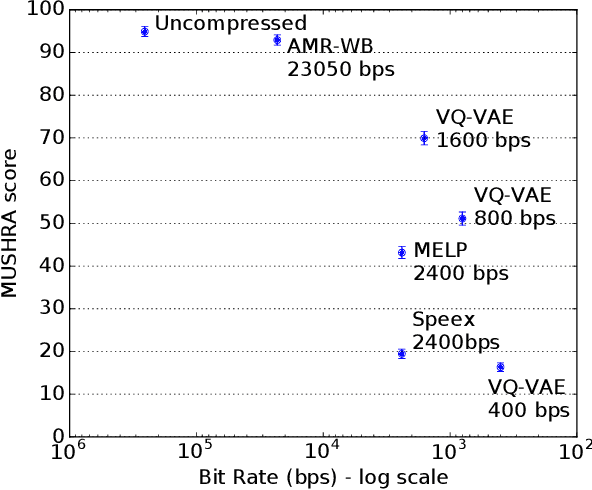
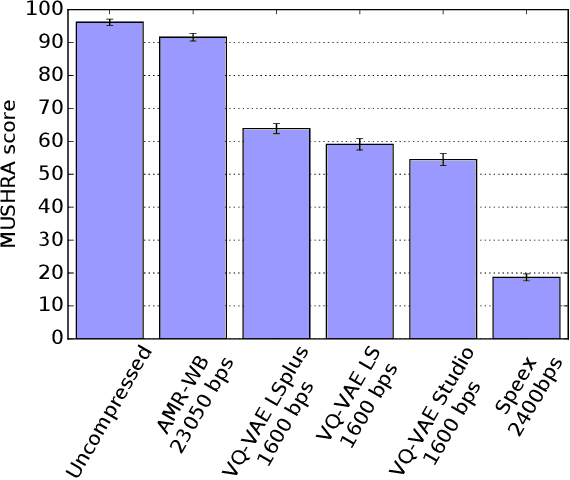
In order to efficiently transmit and store speech signals, speech codecs create a minimally redundant representation of the input signal which is then decoded at the receiver with the best possible perceptual quality. In this work we demonstrate that a neural network architecture based on VQ-VAE with a WaveNet decoder can be used to perform very low bit-rate speech coding with high reconstruction quality. A prosody-transparent and speaker-independent model trained on the LibriSpeech corpus coding audio at 1.6 kbps exhibits perceptual quality which is around halfway between the MELP codec at 2.4 kbps and AMR-WB codec at 23.05 kbps. In addition, when training on high-quality recorded speech with the test speaker included in the training set, a model coding speech at 1.6 kbps produces output of similar perceptual quality to that generated by AMR-WB at 23.05 kbps.
* ICASSP 2019