 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLow Bit-Rate Speech Coding with VQ-VAE and a WaveNet Decoder
Oct 14, 2019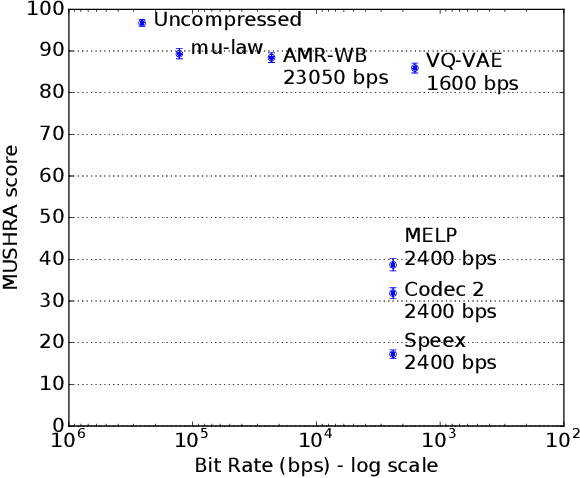
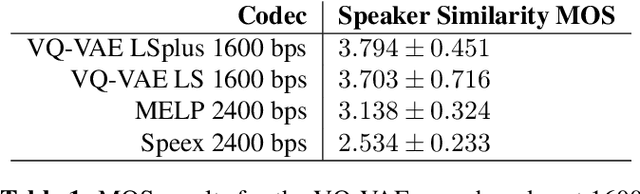
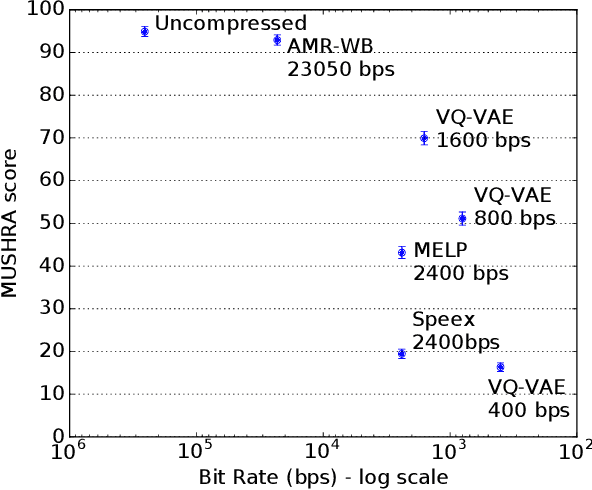
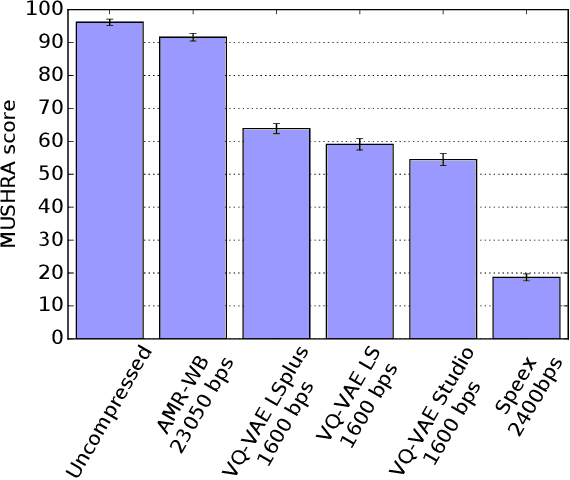
In order to efficiently transmit and store speech signals, speech codecs create a minimally redundant representation of the input signal which is then decoded at the receiver with the best possible perceptual quality. In this work we demonstrate that a neural network architecture based on VQ-VAE with a WaveNet decoder can be used to perform very low bit-rate speech coding with high reconstruction quality. A prosody-transparent and speaker-independent model trained on the LibriSpeech corpus coding audio at 1.6 kbps exhibits perceptual quality which is around halfway between the MELP codec at 2.4 kbps and AMR-WB codec at 23.05 kbps. In addition, when training on high-quality recorded speech with the test speaker included in the training set, a model coding speech at 1.6 kbps produces output of similar perceptual quality to that generated by AMR-WB at 23.05 kbps.
* ICASSP 2019