 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePerch 2.0: The Bittern Lesson for Bioacoustics
Aug 06, 2025



Perch is a performant pre-trained model for bioacoustics. It was trained in supervised fashion, providing both off-the-shelf classification scores for thousands of vocalizing species as well as strong embeddings for transfer learning. In this new release, Perch 2.0, we expand from training exclusively on avian species to a large multi-taxa dataset. The model is trained with self-distillation using a prototype-learning classifier as well as a new source-prediction training criterion. Perch 2.0 obtains state-of-the-art performance on the BirdSet and BEANS benchmarks. It also outperforms specialized marine models on marine transfer learning tasks, despite having almost no marine training data. We present hypotheses as to why fine-grained species classification is a particularly robust pre-training task for bioacoustics.
The Search for Squawk: Agile Modeling in Bioacoustics
May 07, 2025Passive acoustic monitoring (PAM) has shown great promise in helping ecologists understand the health of animal populations and ecosystems. However, extracting insights from millions of hours of audio recordings requires the development of specialized recognizers. This is typically a challenging task, necessitating large amounts of training data and machine learning expertise. In this work, we introduce a general, scalable and data-efficient system for developing recognizers for novel bioacoustic problems in under an hour. Our system consists of several key components that tackle problems in previous bioacoustic workflows: 1) highly generalizable acoustic embeddings pre-trained for birdsong classification minimize data hunger; 2) indexed audio search allows the efficient creation of classifier training datasets, and 3) precomputation of embeddings enables an efficient active learning loop, improving classifier quality iteratively with minimal wait time. Ecologists employed our system in three novel case studies: analyzing coral reef health through unidentified sounds; identifying juvenile Hawaiian bird calls to quantify breeding success and improve endangered species monitoring; and Christmas Island bird occupancy modeling. We augment the case studies with simulated experiments which explore the range of design decisions in a structured way and help establish best practices. Altogether these experiments showcase our system's scalability, efficiency, and generalizability, enabling scientists to quickly address new bioacoustic challenges.
Leveraging tropical reef, bird and unrelated sounds for superior transfer learning in marine bioacoustics
Apr 25, 2024



Machine learning has the potential to revolutionize passive acoustic monitoring (PAM) for ecological assessments. However, high annotation and compute costs limit the field's efficacy. Generalizable pretrained networks can overcome these costs, but high-quality pretraining requires vast annotated libraries, limiting its current applicability primarily to bird taxa. Here, we identify the optimum pretraining strategy for a data-deficient domain using coral reef bioacoustics. We assemble ReefSet, a large annotated library of reef sounds, though modest compared to bird libraries at 2% of the sample count. Through testing few-shot transfer learning performance, we observe that pretraining on bird audio provides notably superior generalizability compared to pretraining on ReefSet or unrelated audio alone. However, our key findings show that cross-domain mixing which leverages bird, reef and unrelated audio during pretraining maximizes reef generalizability. SurfPerch, our pretrained network, provides a strong foundation for automated analysis of marine PAM data with minimal annotation and compute costs.
Simultaneous linear connectivity of neural networks modulo permutation
Apr 09, 2024Neural networks typically exhibit permutation symmetries which contribute to the non-convexity of the networks' loss landscapes, since linearly interpolating between two permuted versions of a trained network tends to encounter a high loss barrier. Recent work has argued that permutation symmetries are the only sources of non-convexity, meaning there are essentially no such barriers between trained networks if they are permuted appropriately. In this work, we refine these arguments into three distinct claims of increasing strength. We show that existing evidence only supports "weak linear connectivity"-that for each pair of networks belonging to a set of SGD solutions, there exist (multiple) permutations that linearly connect it with the other networks. In contrast, the claim "strong linear connectivity"-that for each network, there exists one permutation that simultaneously connects it with the other networks-is both intuitively and practically more desirable. This stronger claim would imply that the loss landscape is convex after accounting for permutation, and enable linear interpolation between three or more independently trained models without increased loss. In this work, we introduce an intermediate claim-that for certain sequences of networks, there exists one permutation that simultaneously aligns matching pairs of networks from these sequences. Specifically, we discover that a single permutation aligns sequences of iteratively trained as well as iteratively pruned networks, meaning that two networks exhibit low loss barriers at each step of their optimization and sparsification trajectories respectively. Finally, we provide the first evidence that strong linear connectivity may be possible under certain conditions, by showing that barriers decrease with increasing network width when interpolating among three networks.
All Thresholds Barred: Direct Estimation of Call Density in Bioacoustic Data
Feb 23, 2024Passive acoustic monitoring (PAM) studies generate thousands of hours of audio, which may be used to monitor specific animal populations, conduct broad biodiversity surveys, detect threats such as poachers, and more. Machine learning classifiers for species identification are increasingly being used to process the vast amount of audio generated by bioacoustic surveys, expediting analysis and increasing the utility of PAM as a management tool. In common practice, a threshold is applied to classifier output scores, and scores above the threshold are aggregated into a detection count. The choice of threshold produces biased counts of vocalizations, which are subject to false positive/negative rates that may vary across subsets of the dataset. In this work, we advocate for directly estimating call density: The proportion of detection windows containing the target vocalization, regardless of classifier score. Our approach targets a desirable ecological estimator and provides a more rigorous grounding for identifying the core problems caused by distribution shifts -- when the defining characteristics of the data distribution change -- and designing strategies to mitigate them. We propose a validation scheme for estimating call density in a body of data and obtain, through Bayesian reasoning, probability distributions of confidence scores for both the positive and negative classes. We use these distributions to predict site-level densities, which may be subject to distribution shifts. We test our proposed methods on a real-world study of Hawaiian birds and provide simulation results leveraging existing fully annotated datasets, demonstrating robustness to variations in call density and classifier model quality.
BIRB: A Generalization Benchmark for Information Retrieval in Bioacoustics
Dec 13, 2023



The ability for a machine learning model to cope with differences in training and deployment conditions--e.g. in the presence of distribution shift or the generalization to new classes altogether--is crucial for real-world use cases. However, most empirical work in this area has focused on the image domain with artificial benchmarks constructed to measure individual aspects of generalization. We present BIRB, a complex benchmark centered on the retrieval of bird vocalizations from passively-recorded datasets given focal recordings from a large citizen science corpus available for training. We propose a baseline system for this collection of tasks using representation learning and a nearest-centroid search. Our thorough empirical evaluation and analysis surfaces open research directions, suggesting that BIRB fills the need for a more realistic and complex benchmark to drive progress on robustness to distribution shifts and generalization of ML models.
Feature Embeddings from Large-Scale Acoustic Bird Classifiers Enable Few-Shot Transfer Learning
Jul 12, 2023Automated bioacoustic analysis aids understanding and protection of both marine and terrestrial animals and their habitats across extensive spatiotemporal scales, and typically involves analyzing vast collections of acoustic data. With the advent of deep learning models, classification of important signals from these datasets has markedly improved. These models power critical data analyses for research and decision-making in biodiversity monitoring, animal behaviour studies, and natural resource management. However, deep learning models are often data-hungry and require a significant amount of labeled training data to perform well. While sufficient training data is available for certain taxonomic groups (e.g., common bird species), many classes (such as rare and endangered species, many non-bird taxa, and call-type), lack enough data to train a robust model from scratch. This study investigates the utility of feature embeddings extracted from large-scale audio classification models to identify bioacoustic classes other than the ones these models were originally trained on. We evaluate models on diverse datasets, including different bird calls and dialect types, bat calls, marine mammals calls, and amphibians calls. The embeddings extracted from the models trained on bird vocalization data consistently allowed higher quality classification than the embeddings trained on general audio datasets. The results of this study indicate that high-quality feature embeddings from large-scale acoustic bird classifiers can be harnessed for few-shot transfer learning, enabling the learning of new classes from a limited quantity of training data. Our findings reveal the potential for efficient analyses of novel bioacoustic tasks, even in scenarios where available training data is limited to a few samples.
In Search for a Generalizable Method for Source Free Domain Adaptation
Feb 13, 2023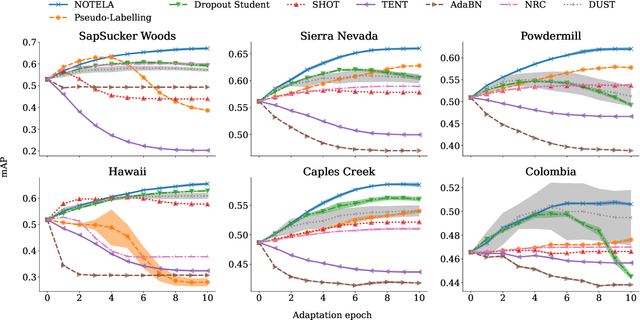
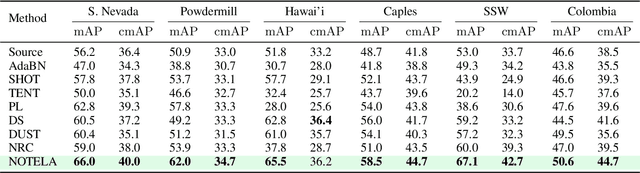
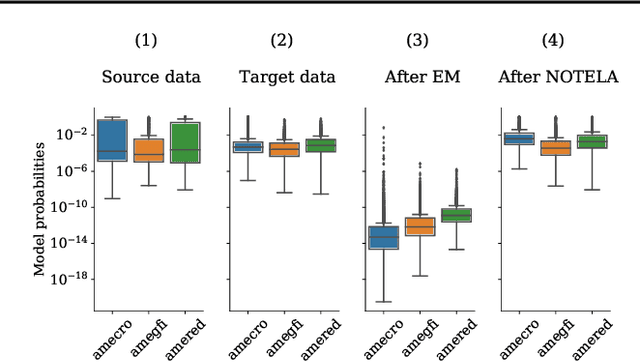
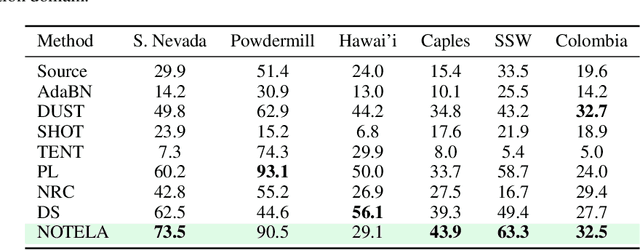
Source-free domain adaptation (SFDA) is compelling because it allows adapting an off-the-shelf model to a new domain using only unlabelled data. In this work, we apply existing SFDA techniques to a challenging set of naturally-occurring distribution shifts in bioacoustics, which are very different from the ones commonly studied in computer vision. We find existing methods perform differently relative to each other than observed in vision benchmarks, and sometimes perform worse than no adaptation at all. We propose a new simple method which outperforms the existing methods on our new shifts while exhibiting strong performance on a range of vision datasets. Our findings suggest that existing SFDA methods are not as generalizable as previously thought and that considering diverse modalities can be a useful avenue for designing more robust models.
Ultra-Low-Bitrate Speech Coding with Pretrained Transformers
Jul 05, 2022
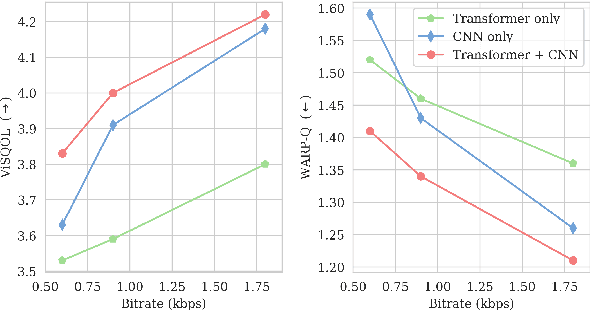
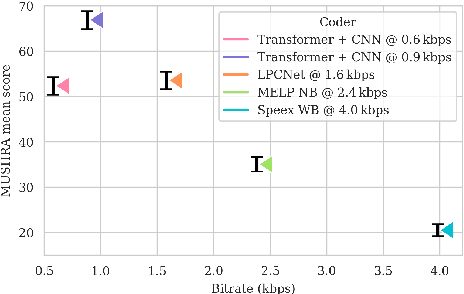
Speech coding facilitates the transmission of speech over low-bandwidth networks with minimal distortion. Neural-network based speech codecs have recently demonstrated significant improvements in quality over traditional approaches. While this new generation of codecs is capable of synthesizing high-fidelity speech, their use of recurrent or convolutional layers often restricts their effective receptive fields, which prevents them from compressing speech efficiently. We propose to further reduce the bitrate of neural speech codecs through the use of pretrained Transformers, capable of exploiting long-range dependencies in the input signal due to their inductive bias. As such, we use a pretrained Transformer in tandem with a convolutional encoder, which is trained end-to-end with a quantizer and a generative adversarial net decoder. Our numerical experiments show that supplementing the convolutional encoder of a neural speech codec with Transformer speech embeddings yields a speech codec with a bitrate of $600\,\mathrm{bps}$ that outperforms the original neural speech codec in synthesized speech quality when trained at the same bitrate. Subjective human evaluations suggest that the quality of the resulting codec is comparable or better than that of conventional codecs operating at three to four times the rate.
Improving Bird Classification with Unsupervised Sound Separation
Oct 07, 2021


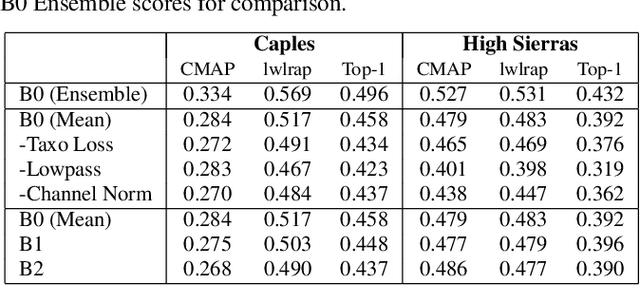
This paper addresses the problem of species classification in bird song recordings. The massive amount of available field recordings of birds presents an opportunity to use machine learning to automatically track bird populations. However, it also poses a problem: such field recordings typically contain significant environmental noise and overlapping vocalizations that interfere with classification. The widely available training datasets for species identification also typically leave background species unlabeled. This leads classifiers to ignore vocalizations with a low signal-to-noise ratio. However, recent advances in unsupervised sound separation, such as \emph{mixture invariant training} (MixIT), enable high quality separation of bird songs to be learned from such noisy recordings. In this paper, we demonstrate improved separation quality when training a MixIT model specifically for birdsong data, outperforming a general audio separation model by over 5 dB in SI-SNR improvement of reconstructed mixtures. We also demonstrate precision improvements with a downstream multi-species bird classifier across three independent datasets. The best classifier performance is achieved by taking the maximum model activations over the separated channels and original audio. Finally, we document additional classifier improvements, including taxonomic classification, augmentation by random low-pass filters, and additional channel normalization.