 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparse Training from Random Initialization: Aligning Lottery Ticket Masks using Weight Symmetry
May 08, 2025The Lottery Ticket Hypothesis (LTH) suggests there exists a sparse LTH mask and weights that achieve the same generalization performance as the dense model while using significantly fewer parameters. However, finding a LTH solution is computationally expensive, and a LTH sparsity mask does not generalize to other random weight initializations. Recent work has suggested that neural networks trained from random initialization find solutions within the same basin modulo permutation, and proposes a method to align trained models within the same loss basin. We hypothesize that misalignment of basins is the reason why LTH masks do not generalize to new random initializations and propose permuting the LTH mask to align with the new optimization basin when performing sparse training from a different random init. We empirically show a significant increase in generalization when sparse training from random initialization with the permuted mask as compared to using the non-permuted LTH mask, on multiple datasets (CIFAR-10, CIFAR-100 and ImageNet) and models (VGG11, ResNet20 and ResNet50).
The Non-Local Model Merging Problem: Permutation Symmetries and Variance Collapse
Oct 16, 2024Model merging aims to efficiently combine the weights of multiple expert models, each trained on a specific task, into a single multi-task model, with strong performance across all tasks. When applied to all but the last layer of weights, existing methods -- such as Task Arithmetic, TIES-merging, and TALL mask merging -- work well to combine expert models obtained by fine-tuning a common foundation model, operating within a "local" neighborhood of the foundation model. This work explores the more challenging scenario of "non-local" merging, which we find arises when an expert model changes significantly during pretraining or where the expert models do not even share a common foundation model. We observe that standard merging techniques often fail to generalize effectively in this non-local setting, even when accounting for permutation symmetries using standard techniques. We identify that this failure is, in part, due to "variance collapse", a phenomenon identified also in the setting of linear mode connectivity by Jordan et al. (2023). To address this, we propose a multi-task technique to re-scale and shift the output activations of the merged model for each task, aligning its output statistics with those of the corresponding task-specific expert models. Our experiments demonstrate that this correction significantly improves the performance of various model merging approaches in non-local settings, providing a strong baseline for future research on this problem.
Simultaneous linear connectivity of neural networks modulo permutation
Apr 09, 2024Neural networks typically exhibit permutation symmetries which contribute to the non-convexity of the networks' loss landscapes, since linearly interpolating between two permuted versions of a trained network tends to encounter a high loss barrier. Recent work has argued that permutation symmetries are the only sources of non-convexity, meaning there are essentially no such barriers between trained networks if they are permuted appropriately. In this work, we refine these arguments into three distinct claims of increasing strength. We show that existing evidence only supports "weak linear connectivity"-that for each pair of networks belonging to a set of SGD solutions, there exist (multiple) permutations that linearly connect it with the other networks. In contrast, the claim "strong linear connectivity"-that for each network, there exists one permutation that simultaneously connects it with the other networks-is both intuitively and practically more desirable. This stronger claim would imply that the loss landscape is convex after accounting for permutation, and enable linear interpolation between three or more independently trained models without increased loss. In this work, we introduce an intermediate claim-that for certain sequences of networks, there exists one permutation that simultaneously aligns matching pairs of networks from these sequences. Specifically, we discover that a single permutation aligns sequences of iteratively trained as well as iteratively pruned networks, meaning that two networks exhibit low loss barriers at each step of their optimization and sparsification trajectories respectively. Finally, we provide the first evidence that strong linear connectivity may be possible under certain conditions, by showing that barriers decrease with increasing network width when interpolating among three networks.
Adaptive Compliant Robot Control with Failure Recovery for Object Press-Fitting
Jul 17, 2023Loading of shipping containers for dairy products often includes a press-fit task, which involves manually stacking milk cartons in a container without using pallets or packaging. Automating this task with a mobile manipulator can reduce worker strain, and also enhance the efficiency and safety of the container loading process. This paper proposes an approach called Adaptive Compliant Control with Integrated Failure Recovery (ACCIFR), which enables a mobile manipulator to reliably perform the press-fit task. We base the approach on a demonstration learning-based compliant control framework, such that we integrate a monitoring and failure recovery mechanism for successful task execution. Concretely, we monitor the execution through distance and force feedback, detect collisions while the robot is performing the press-fit task, and use wrench measurements to classify the direction of collision; this information informs the subsequent recovery process. We evaluate the method on a miniature container setup, considering variations in the (i) starting position of the end effector, (ii) goal configuration, and (iii) object grasping position. The results demonstrate that the proposed approach outperforms the baseline demonstration-based learning framework regarding adaptability to environmental variations and the ability to recover from collision failures, making it a promising solution for practical press-fit applications.
Exchangeable modelling of relational data: checking sparsity, train-test splitting, and sparse exchangeable Poisson matrix factorization
Dec 06, 2017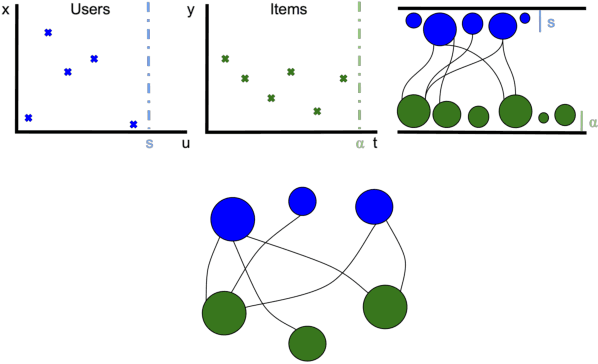
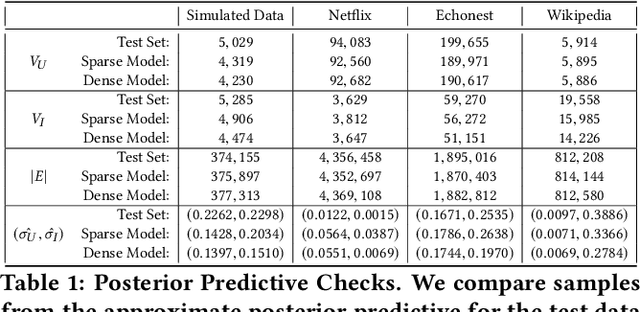
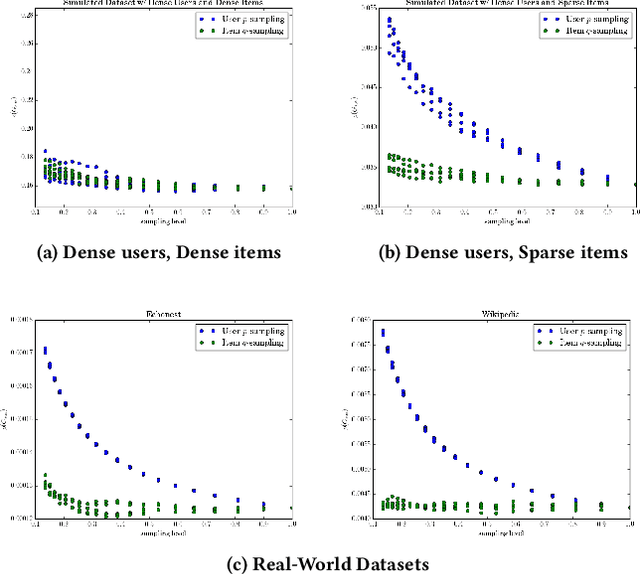
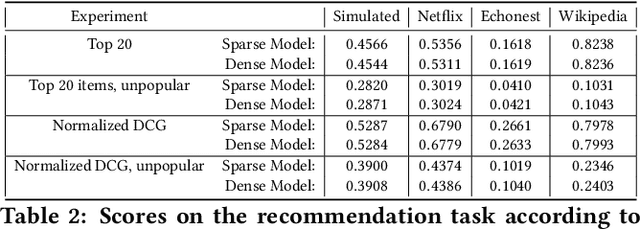
A variety of machine learning tasks---e.g., matrix factorization, topic modelling, and feature allocation---can be viewed as learning the parameters of a probability distribution over bipartite graphs. Recently, a new class of models for networks, the sparse exchangeable graphs, have been introduced to resolve some important pathologies of traditional approaches to statistical network modelling; most notably, the inability to model sparsity (in the asymptotic sense). The present paper explains some practical insights arising from this work. We first show how to check if sparsity is relevant for modelling a given (fixed size) dataset by using network subsampling to identify a simple signature of sparsity. We discuss the implications of the (sparse) exchangeable subsampling theory for test-train dataset splitting; we argue common approaches can lead to biased results, and we propose a principled alternative. Finally, we study sparse exchangeable Poisson matrix factorization as a worked example. In particular, we show how to adapt mean field variational inference to the sparse exchangeable setting, allowing us to scale inference to huge datasets.
Modeling trajectories of mental health: challenges and opportunities
Dec 04, 2016

More than two thirds of mental health problems have their onset during childhood or adolescence. Identifying children at risk for mental illness later in life and predicting the type of illness is not easy. We set out to develop a platform to define subtypes of childhood social-emotional development using longitudinal, multifactorial trait-based measures. Subtypes discovered through this study could ultimately advance psychiatric knowledge of the early behavioural signs of mental illness. To this extent we have examined two types of models: latent class mixture models and GP-based models. Our findings indicate that while GP models come close in accuracy of predicting future trajectories, LCMMs predict the trajectories as well in a fraction of the time. Unfortunately, neither of the models are currently accurate enough to lead to immediate clinical impact. The available data related to the development of childhood mental health is often sparse with only a few time points measured and require novel methods with improved efficiency and accuracy.