 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOn the role of memorization in learned priors for geophysical inverse problems
Mar 20, 2026Learned priors based on deep generative models offer data-driven regularization for seismic inversion, but training them requires a dataset of representative subsurface models -- a resource that is inherently scarce in geoscience applications. Since the training objective of most generative models can be cast as maximum likelihood on a finite dataset, any such model risks converging to the empirical distribution -- effectively memorizing the training examples rather than learning the underlying geological distribution. We show that the posterior under such a memorized prior reduces to a reweighted empirical distribution -- i.e., a likelihood-weighted lookup among the stored training examples. For diffusion models specifically, memorization yields a Gaussian mixture prior in closed form, and linearizing the forward operator around each training example gives a Gaussian mixture posterior whose components have widths and shifts governed by the local Jacobian. We validate these predictions on a stylized inverse problem and demonstrate the consequences of memorization through diffusion posterior sampling for full waveform inversion.
Dual-space posterior sampling for Bayesian inference in constrained inverse problems
Feb 28, 2026Inverse problems constrained by partial differential equations are often ill-conditioned due to noisy and incomplete data or inherent non-uniqueness. A prominent example is full waveform inversion, which estimates Earth's subsurface properties by fitting seismic measurements subject to the wave equation, where ill-conditioning is inherent to noisy, band-limited, finite-aperture data and shadow zones. Casting the inverse problem into a Bayesian framework allows for a more comprehensive description of its solution, where instead of a single estimate, the posterior distribution characterizes non-uniqueness and can be sampled to quantify uncertainty. However, no clear procedure exists for translating hard physical constraints, such as the wave equation, into prior distributions amenable to existing sampling techniques. To address this, we perform posterior sampling in the dual space using an augmented Lagrangian formulation, which translates hard constraints into penalties amenable to sampling algorithms while ensuring their exact satisfaction. We achieve this by seamlessly integrating the alternating direction method of multipliers (ADMM) with Stein variational gradient descent (SVGD) -- a particle-based sampler -- where the constraint is relaxed at each iteration and multiplier updates progressively enforce satisfaction. This enables constrained posterior sampling while inheriting the favorable conditioning properties of dual-space solvers, where partial constraint relaxation allows productive updates even when the current model is far from the true solution. We validate the method on a stylized Rosenbrock conditional inference problem and on frequency-domain full waveform inversion for a Gaussian anomaly model and the Marmousi~II benchmark, demonstrating well-calibrated uncertainty estimates and posterior contraction with increasing data coverage.
Hypernetwork-based approach for grid-independent functional data clustering
Feb 26, 2026Functional data clustering is concerned with grouping functions that share similar structure, yet most existing methods implicitly operate on sampled grids, causing cluster assignments to depend on resolution, sampling density, or preprocessing choices rather than on the underlying functions themselves. To address this limitation, we introduce a framework that maps discretized function observations -- at arbitrary resolution and on arbitrary grids -- into a fixed-dimensional vector space via an auto-encoding architecture. The encoder is a hypernetwork that maps coordinate-value pairs to the weight space of an implicit neural representation (INR), which serves as the decoder. Because INRs represent functions with very few parameters, this design yields compact representations that are decoupled from the sampling grid, while the hypernetwork amortizes weight prediction across the dataset. Clustering is then performed in this weight space using standard algorithms, making the approach agnostic to both the discretization and the choice of clustering method. By means of synthetic and real-world experiments in high-dimensional settings, we demonstrate competitive clustering performance that is robust to changes in sampling resolution -- including generalization to resolutions not seen during training.
Conditional neural control variates for variance reduction in Bayesian inverse problems
Feb 24, 2026Bayesian inference for inverse problems involves computing expectations under posterior distributions -- e.g., posterior means, variances, or predictive quantities -- typically via Monte Carlo (MC) estimation. When the quantity of interest varies significantly under the posterior, accurate estimates demand many samples -- a cost often prohibitive for partial differential equation-constrained problems. To address this challenge, we introduce conditional neural control variates, a modular method that learns amortized control variates from joint model-data samples to reduce the variance of MC estimators. To scale to high-dimensional problems, we leverage Stein's identity to design an architecture based on an ensemble of hierarchical coupling layers with tractable Jacobian trace computation. Training requires: (i) samples from the joint distribution of unknown parameters and observed data; and (ii) the posterior score function, which can be computed from physics-based likelihood evaluations, neural operator surrogates, or learned generative models such as conditional normalizing flows. Once trained, the control variates generalize across observations without retraining. We validate our approach on stylized and partial differential equation-constrained Darcy flow inverse problems, demonstrating substantial variance reduction, even when the analytical score is replaced by a learned surrogate.
Taming Score-Based Diffusion Priors for Infinite-Dimensional Nonlinear Inverse Problems
May 24, 2024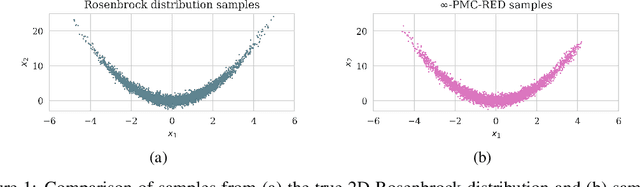
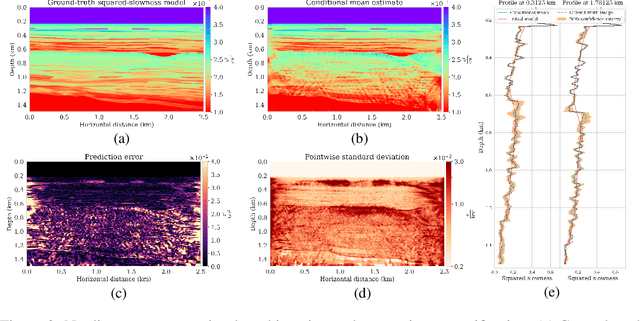
This work introduces a sampling method capable of solving Bayesian inverse problems in function space. It does not assume the log-concavity of the likelihood, meaning that it is compatible with nonlinear inverse problems. The method leverages the recently defined infinite-dimensional score-based diffusion models as a learning-based prior, while enabling provable posterior sampling through a Langevin-type MCMC algorithm defined on function spaces. A novel convergence analysis is conducted, inspired by the fixed-point methods established for traditional regularization-by-denoising algorithms and compatible with weighted annealing. The obtained convergence bound explicitly depends on the approximation error of the score; a well-approximated score is essential to obtain a well-approximated posterior. Stylized and PDE-based examples are provided, demonstrating the validity of our convergence analysis. We conclude by presenting a discussion of the method's challenges related to learning the score and computational complexity.
Removing Bias from Maximum Likelihood Estimation with Model Autophagy
May 22, 2024We propose autophagy penalized likelihood estimation (PLE), an unbiased alternative to maximum likelihood estimation (MLE) which is more fair and less susceptible to model autophagy disorder (madness). Model autophagy refers to models trained on their own output; PLE ensures the statistics of these outputs coincide with the data statistics. This enables PLE to be statistically unbiased in certain scenarios where MLE is biased. When biased, MLE unfairly penalizes minority classes in unbalanced datasets and exacerbates the recently discovered issue of self-consuming generative modeling. Theoretical and empirical results show that 1) PLE is more fair to minority classes and 2) PLE is more stable in a self-consumed setting. Furthermore, we provide a scalable and portable implementation of PLE with a hypernetwork framework, allowing existing deep learning architectures to be easily trained with PLE. Finally, we show PLE can bridge the gap between Bayesian and frequentist paradigms in statistics.
ASPIRE: Iterative Amortized Posterior Inference for Bayesian Inverse Problems
May 08, 2024Due to their uncertainty quantification, Bayesian solutions to inverse problems are the framework of choice in applications that are risk averse. These benefits come at the cost of computations that are in general, intractable. New advances in machine learning and variational inference (VI) have lowered the computational barrier by learning from examples. Two VI paradigms have emerged that represent different tradeoffs: amortized and non-amortized. Amortized VI can produce fast results but due to generalizing to many observed datasets it produces suboptimal inference results. Non-amortized VI is slower at inference but finds better posterior approximations since it is specialized towards a single observed dataset. Current amortized VI techniques run into a sub-optimality wall that can not be improved without more expressive neural networks or extra training data. We present a solution that enables iterative improvement of amortized posteriors that uses the same networks architectures and training data. The benefits of our method requires extra computations but these remain frugal since they are based on physics-hybrid methods and summary statistics. Importantly, these computations remain mostly offline thus our method maintains cheap and reusable online evaluation while bridging the approximation gap these two paradigms. We denote our proposed method ASPIRE - Amortized posteriors with Summaries that are Physics-based and Iteratively REfined. We first validate our method on a stylized problem with a known posterior then demonstrate its practical use on a high-dimensional and nonlinear transcranial medical imaging problem with ultrasound. Compared with the baseline and previous methods from the literature our method stands out as an computationally efficient and high-fidelity method for posterior inference.
InvertibleNetworks.jl: A Julia package for scalable normalizing flows
Dec 20, 2023InvertibleNetworks.jl is a Julia package designed for the scalable implementation of normalizing flows, a method for density estimation and sampling in high-dimensional distributions. This package excels in memory efficiency by leveraging the inherent invertibility of normalizing flows, which significantly reduces memory requirements during backpropagation compared to existing normalizing flow packages that rely on automatic differentiation frameworks. InvertibleNetworks.jl has been adapted for diverse applications, including seismic imaging, medical imaging, and CO2 monitoring, demonstrating its effectiveness in learning high-dimensional distributions.
Self-Consuming Generative Models Go MAD
Jul 04, 2023

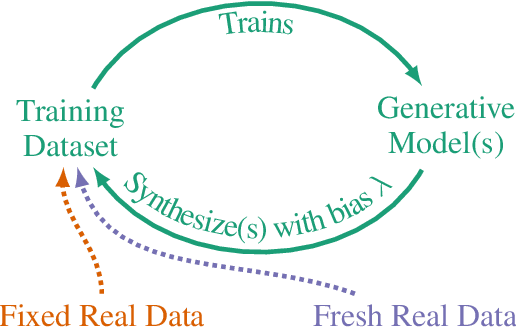
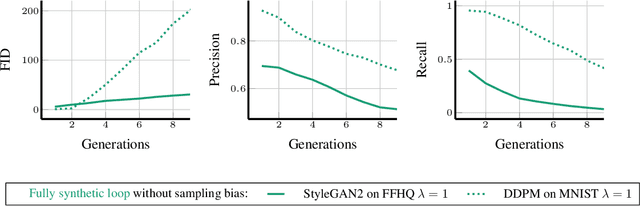
Seismic advances in generative AI algorithms for imagery, text, and other data types has led to the temptation to use synthetic data to train next-generation models. Repeating this process creates an autophagous (self-consuming) loop whose properties are poorly understood. We conduct a thorough analytical and empirical analysis using state-of-the-art generative image models of three families of autophagous loops that differ in how fixed or fresh real training data is available through the generations of training and in whether the samples from previous generation models have been biased to trade off data quality versus diversity. Our primary conclusion across all scenarios is that without enough fresh real data in each generation of an autophagous loop, future generative models are doomed to have their quality (precision) or diversity (recall) progressively decrease. We term this condition Model Autophagy Disorder (MAD), making analogy to mad cow disease.
Conditional score-based diffusion models for Bayesian inference in infinite dimensions
May 28, 2023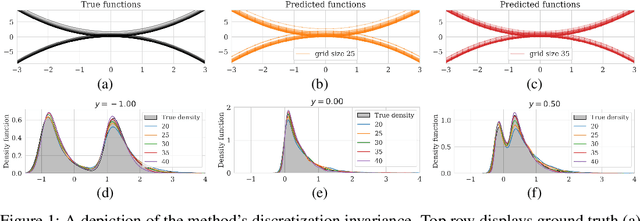
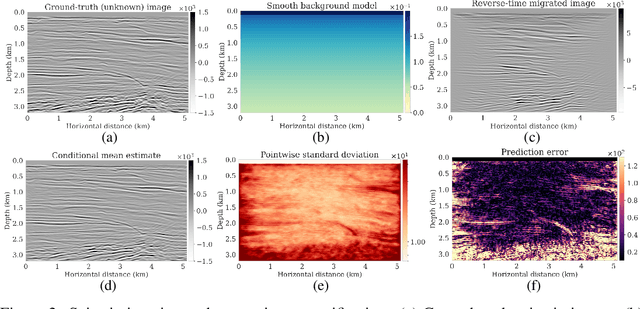


Since their first introduction, score-based diffusion models (SDMs) have been successfully applied to solve a variety of linear inverse problems in finite-dimensional vector spaces due to their ability to efficiently approximate the posterior distribution. However, using SDMs for inverse problems in infinite-dimensional function spaces has only been addressed recently and by learning the unconditional score. While this approach has some advantages, depending on the specific inverse problem at hand, in order to sample from the conditional distribution it needs to incorporate the information from the observed data with a proximal optimization step, solving an optimization problem numerous times. This may not be feasible in inverse problems with computationally costly forward operators. To address these limitations, in this work we propose a method to learn the posterior distribution in infinite-dimensional Bayesian linear inverse problems using amortized conditional SDMs. In particular, we prove that the conditional denoising estimator is a consistent estimator of the conditional score in infinite dimensions. We show that the extension of SDMs to the conditional setting requires some care because the conditional score typically blows up for small times contrarily to the unconditional score. We also discuss the robustness of the learned distribution against perturbations of the observations. We conclude by presenting numerical examples that validate our approach and provide additional insights.