 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAsymmetrical Reciprocity-based Federated Learning for Resolving Disparities in Medical Diagnosis
Dec 27, 2024



Geographic health disparities pose a pressing global challenge, particularly in underserved regions of low- and middle-income nations. Addressing this issue requires a collaborative approach to enhance healthcare quality, leveraging support from medically more developed areas. Federated learning emerges as a promising tool for this purpose. However, the scarcity of medical data and limited computation resources in underserved regions make collaborative training of powerful machine learning models challenging. Furthermore, there exists an asymmetrical reciprocity between underserved and developed regions. To overcome these challenges, we propose a novel cross-silo federated learning framework, named FedHelp, aimed at alleviating geographic health disparities and fortifying the diagnostic capabilities of underserved regions. Specifically, FedHelp leverages foundational model knowledge via one-time API access to guide the learning process of underserved small clients, addressing the challenge of insufficient data. Additionally, we introduce a novel asymmetric dual knowledge distillation module to manage the issue of asymmetric reciprocity, facilitating the exchange of necessary knowledge between developed large clients and underserved small clients. We validate the effectiveness and utility of FedHelp through extensive experiments on both medical image classification and segmentation tasks. The experimental results demonstrate significant performance improvement compared to state-of-the-art baselines, particularly benefiting clients in underserved regions.
An uncertainty-aware Digital Shadow for underground multimodal CO2 storage monitoring
Oct 02, 2024Geological Carbon Storage GCS is arguably the only scalable net-negative CO2 emission technology available While promising subsurface complexities and heterogeneity of reservoir properties demand a systematic approach to quantify uncertainty when optimizing production and mitigating storage risks which include assurances of Containment and Conformance of injected supercritical CO2 As a first step towards the design and implementation of a Digital Twin for monitoring underground storage operations a machine learning based data-assimilation framework is introduced and validated on carefully designed realistic numerical simulations As our implementation is based on Bayesian inference but does not yet support control and decision-making we coin our approach an uncertainty-aware Digital Shadow To characterize the posterior distribution for the state of CO2 plumes conditioned on multi-modal time-lapse data the envisioned Shadow combines techniques from Simulation-Based Inference SBI and Ensemble Bayesian Filtering to establish probabilistic baselines and assimilate multi-modal data for GCS problems that are challenged by large degrees of freedom nonlinear multi-physics non-Gaussianity and computationally expensive to evaluate fluid flow and seismic simulations To enable SBI for dynamic systems a recursive scheme is proposed where the Digital Shadows neural networks are trained on simulated ensembles for their state and observed data well and/or seismic Once training is completed the systems state is inferred when time-lapse field data becomes available In this computational study we observe that a lack of knowledge on the permeability field can be factored into the Digital Shadows uncertainty quantification To our knowledge this work represents the first proof of concept of an uncertainty-aware in-principle scalable Digital Shadow.
Personalized Steering of Large Language Models: Versatile Steering Vectors Through Bi-directional Preference Optimization
May 28, 2024



Researchers have been studying approaches to steer the behavior of Large Language Models (LLMs) and build personalized LLMs tailored for various applications. While fine-tuning seems to be a direct solution, it requires substantial computational resources and may significantly affect the utility of the original LLM. Recent endeavors have introduced more lightweight strategies, focusing on extracting "steering vectors" to guide the model's output toward desired behaviors by adjusting activations within specific layers of the LLM's transformer architecture. However, such steering vectors are directly extracted from the activations of human preference data and thus often lead to suboptimal results and occasional failures, especially in alignment-related scenarios. This work proposes an innovative approach that could produce more effective steering vectors through bi-directional preference optimization. Our method is designed to allow steering vectors to directly influence the generation probability of contrastive human preference data pairs, thereby offering a more precise representation of the target behavior. By carefully adjusting the direction and magnitude of the steering vector, we enabled personalized control over the desired behavior across a spectrum of intensities. Extensive experimentation across various open-ended generation tasks, particularly focusing on steering AI personas, has validated the efficacy of our approach. Moreover, we comprehensively investigate critical alignment-concerning scenarios, such as managing truthfulness, mitigating hallucination, and addressing jailbreaking attacks. Remarkably, our method can still demonstrate outstanding steering effectiveness across these scenarios. Furthermore, we showcase the transferability of our steering vectors across different models/LoRAs and highlight the synergistic benefits of applying multiple vectors simultaneously.
VQAttack: Transferable Adversarial Attacks on Visual Question Answering via Pre-trained Models
Feb 16, 2024
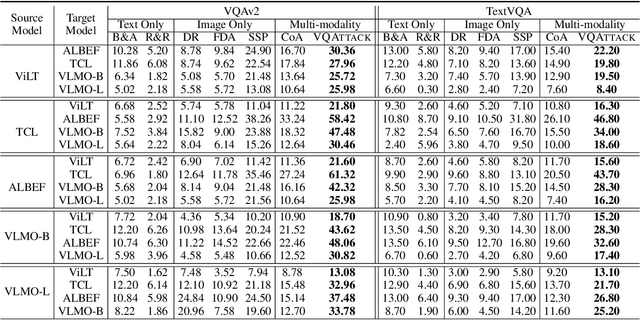
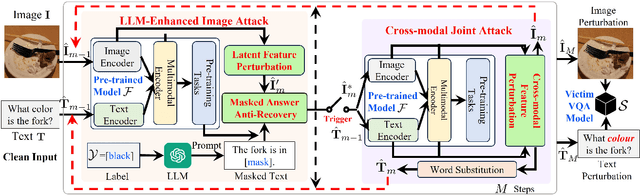
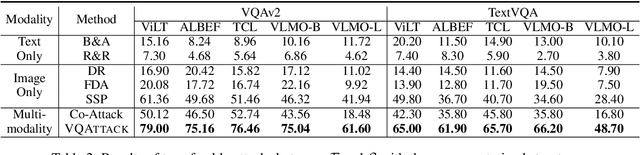
Visual Question Answering (VQA) is a fundamental task in computer vision and natural language process fields. Although the ``pre-training & finetuning'' learning paradigm significantly improves the VQA performance, the adversarial robustness of such a learning paradigm has not been explored. In this paper, we delve into a new problem: using a pre-trained multimodal source model to create adversarial image-text pairs and then transferring them to attack the target VQA models. Correspondingly, we propose a novel VQAttack model, which can iteratively generate both image and text perturbations with the designed modules: the large language model (LLM)-enhanced image attack and the cross-modal joint attack module. At each iteration, the LLM-enhanced image attack module first optimizes the latent representation-based loss to generate feature-level image perturbations. Then it incorporates an LLM to further enhance the image perturbations by optimizing the designed masked answer anti-recovery loss. The cross-modal joint attack module will be triggered at a specific iteration, which updates the image and text perturbations sequentially. Notably, the text perturbation updates are based on both the learned gradients in the word embedding space and word synonym-based substitution. Experimental results on two VQA datasets with five validated models demonstrate the effectiveness of the proposed VQAttack in the transferable attack setting, compared with state-of-the-art baselines. This work reveals a significant blind spot in the ``pre-training & fine-tuning'' paradigm on VQA tasks. Source codes will be released.
Recent Advances in Predictive Modeling with Electronic Health Records
Feb 02, 2024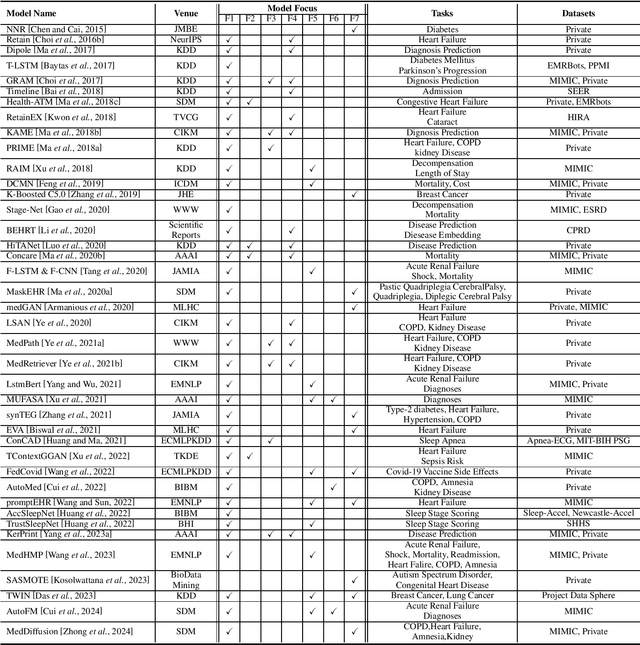
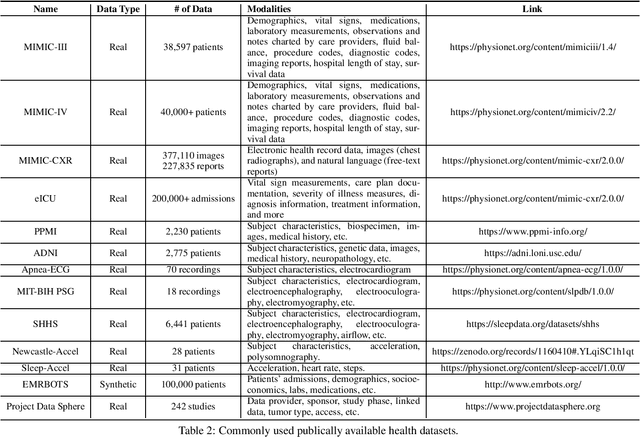
The development of electronic health records (EHR) systems has enabled the collection of a vast amount of digitized patient data. However, utilizing EHR data for predictive modeling presents several challenges due to its unique characteristics. With the advancements in machine learning techniques, deep learning has demonstrated its superiority in various applications, including healthcare. This survey systematically reviews recent advances in deep learning-based predictive models using EHR data. Specifically, we begin by introducing the background of EHR data and providing a mathematical definition of the predictive modeling task. We then categorize and summarize predictive deep models from multiple perspectives. Furthermore, we present benchmarks and toolkits relevant to predictive modeling in healthcare. Finally, we conclude this survey by discussing open challenges and suggesting promising directions for future research.
Inference of CO2 flow patterns -- a feasibility study
Nov 01, 2023As the global deployment of carbon capture and sequestration (CCS) technology intensifies in the fight against climate change, it becomes increasingly imperative to establish robust monitoring and detection mechanisms for potential underground CO2 leakage, particularly through pre-existing or induced faults in the storage reservoir's seals. While techniques such as history matching and time-lapse seismic monitoring of CO2 storage have been used successfully in tracking the evolution of CO2 plumes in the subsurface, these methods lack principled approaches to characterize uncertainties related to the CO2 plumes' behavior. Inclusion of systematic assessment of uncertainties is essential for risk mitigation for the following reasons: (i) CO2 plume-induced changes are small and seismic data is noisy; (ii) changes between regular and irregular (e.g., caused by leakage) flow patterns are small; and (iii) the reservoir properties that control the flow are strongly heterogeneous and typically only available as distributions. To arrive at a formulation capable of inferring flow patterns for regular and irregular flow from well and seismic data, the performance of conditional normalizing flow will be analyzed on a series of carefully designed numerical experiments. While the inferences presented are preliminary in the context of an early CO2 leakage detection system, the results do indicate that inferences with conditional normalizing flows can produce high-fidelity estimates for CO2 plumes with or without leakage. We are also confident that the inferred uncertainty is reasonable because it correlates well with the observed errors. This uncertainty stems from noise in the seismic data and from the lack of precise knowledge of the reservoir's fluid flow properties.
Hierarchical Pretraining on Multimodal Electronic Health Records
Oct 20, 2023Pretraining has proven to be a powerful technique in natural language processing (NLP), exhibiting remarkable success in various NLP downstream tasks. However, in the medical domain, existing pretrained models on electronic health records (EHR) fail to capture the hierarchical nature of EHR data, limiting their generalization capability across diverse downstream tasks using a single pretrained model. To tackle this challenge, this paper introduces a novel, general, and unified pretraining framework called MEDHMP, specifically designed for hierarchically multimodal EHR data. The effectiveness of the proposed MEDHMP is demonstrated through experimental results on eight downstream tasks spanning three levels. Comparisons against eighteen baselines further highlight the efficacy of our approach.
VLAttack: Multimodal Adversarial Attacks on Vision-Language Tasks via Pre-trained Models
Oct 07, 2023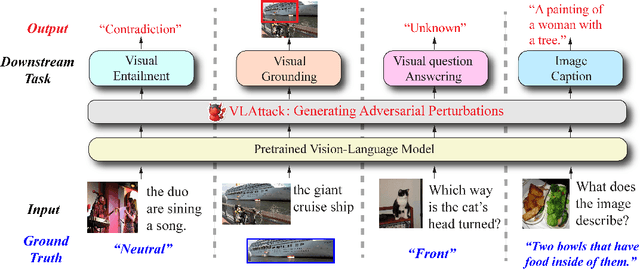
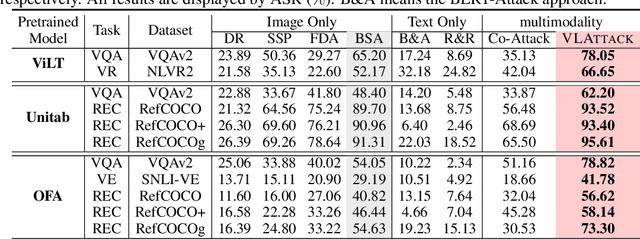
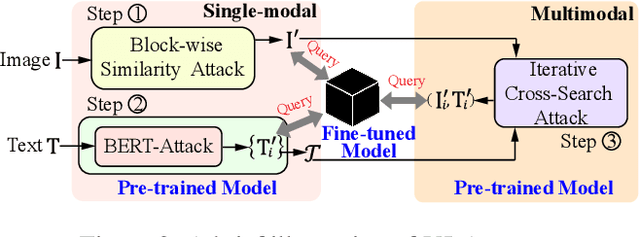
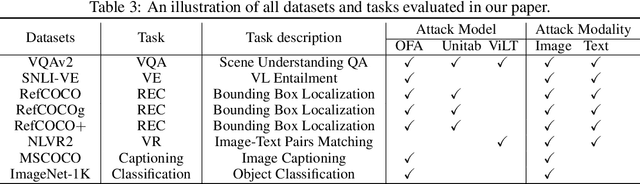
Vision-Language (VL) pre-trained models have shown their superiority on many multimodal tasks. However, the adversarial robustness of such models has not been fully explored. Existing approaches mainly focus on exploring the adversarial robustness under the white-box setting, which is unrealistic. In this paper, we aim to investigate a new yet practical task to craft image and text perturbations using pre-trained VL models to attack black-box fine-tuned models on different downstream tasks. Towards this end, we propose VLAttack to generate adversarial samples by fusing perturbations of images and texts from both single-modal and multimodal levels. At the single-modal level, we propose a new block-wise similarity attack (BSA) strategy to learn image perturbations for disrupting universal representations. Besides, we adopt an existing text attack strategy to generate text perturbations independent of the image-modal attack. At the multimodal level, we design a novel iterative cross-search attack (ICSA) method to update adversarial image-text pairs periodically, starting with the outputs from the single-modal level. We conduct extensive experiments to attack three widely-used VL pretrained models for six tasks on eight datasets. Experimental results show that the proposed VLAttack framework achieves the highest attack success rates on all tasks compared with state-of-the-art baselines, which reveals a significant blind spot in the deployment of pre-trained VL models. Codes will be released soon.
MedDiffusion: Boosting Health Risk Prediction via Diffusion-based Data Augmentation
Oct 05, 2023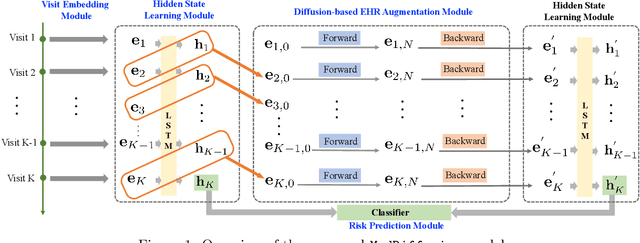
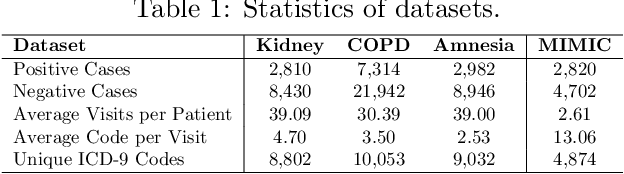
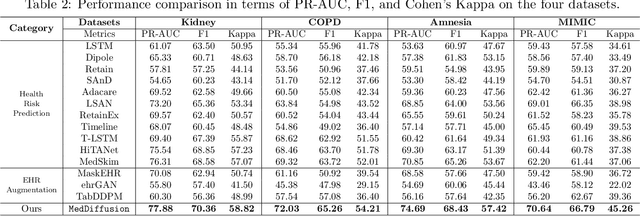
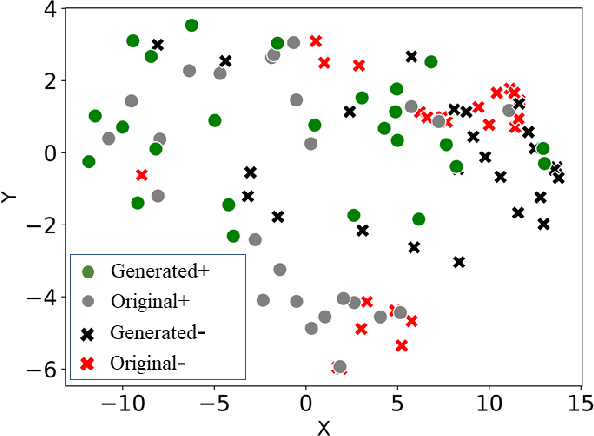
Health risk prediction is one of the fundamental tasks under predictive modeling in the medical domain, which aims to forecast the potential health risks that patients may face in the future using their historical Electronic Health Records (EHR). Researchers have developed several risk prediction models to handle the unique challenges of EHR data, such as its sequential nature, high dimensionality, and inherent noise. These models have yielded impressive results. Nonetheless, a key issue undermining their effectiveness is data insufficiency. A variety of data generation and augmentation methods have been introduced to mitigate this issue by expanding the size of the training data set through the learning of underlying data distributions. However, the performance of these methods is often limited due to their task-unrelated design. To address these shortcomings, this paper introduces a novel, end-to-end diffusion-based risk prediction model, named MedDiffusion. It enhances risk prediction performance by creating synthetic patient data during training to enlarge sample space. Furthermore, MedDiffusion discerns hidden relationships between patient visits using a step-wise attention mechanism, enabling the model to automatically retain the most vital information for generating high-quality data. Experimental evaluation on four real-world medical datasets demonstrates that MedDiffusion outperforms 14 cutting-edge baselines in terms of PR-AUC, F1, and Cohen's Kappa. We also conduct ablation studies and benchmark our model against GAN-based alternatives to further validate the rationality and adaptability of our model design. Additionally, we analyze generated data to offer fresh insights into the model's interpretability.
Solving multiphysics-based inverse problems with learned surrogates and constraints
Jul 18, 2023Solving multiphysics-based inverse problems for geological carbon storage monitoring can be challenging when multimodal time-lapse data are expensive to collect and costly to simulate numerically. We overcome these challenges by combining computationally cheap learned surrogates with learned constraints. Not only does this combination lead to vastly improved inversions for the important fluid-flow property, permeability, it also provides a natural platform for inverting multimodal data including well measurements and active-source time-lapse seismic data. By adding a learned constraint, we arrive at a computationally feasible inversion approach that remains accurate. This is accomplished by including a trained deep neural network, known as a normalizing flow, which forces the model iterates to remain in-distribution, thereby safeguarding the accuracy of trained Fourier neural operators that act as surrogates for the computationally expensive multiphase flow simulations involving partial differential equation solves. By means of carefully selected experiments, centered around the problem of geological carbon storage, we demonstrate the efficacy of the proposed constrained optimization method on two different data modalities, namely time-lapse well and time-lapse seismic data. While permeability inversions from both these two modalities have their pluses and minuses, their joint inversion benefits from either, yielding valuable superior permeability inversions and CO2 plume predictions near, and far away, from the monitoring wells.