 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMEVER: Multi-Modal and Explainable Claim Verification with Graph-based Evidence Retrieval
Feb 10, 2026Verifying the truthfulness of claims usually requires joint multi-modal reasoning over both textual and visual evidence, such as analyzing both textual caption and chart image for claim verification. In addition, to make the reasoning process transparent, a textual explanation is necessary to justify the verification result. However, most claim verification works mainly focus on the reasoning over textual evidence only or ignore the explainability, resulting in inaccurate and unconvincing verification. To address this problem, we propose a novel model that jointly achieves evidence retrieval, multi-modal claim verification, and explanation generation. For evidence retrieval, we construct a two-layer multi-modal graph for claims and evidence, where we design image-to-text and text-to-image reasoning for multi-modal retrieval. For claim verification, we propose token- and evidence-level fusion to integrate claim and evidence embeddings for multi-modal verification. For explanation generation, we introduce multi-modal Fusion-in-Decoder for explainability. Finally, since almost all the datasets are in general domain, we create a scientific dataset, AIChartClaim, in AI domain to complement claim verification community. Experiments show the strength of our model.
Automated Multi-Task Learning for Joint Disease Prediction on Electronic Health Records
Mar 06, 2024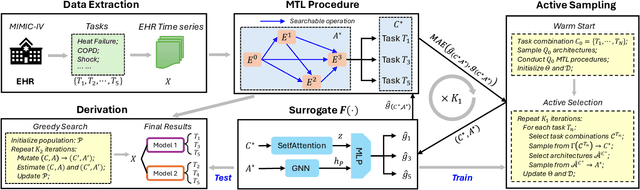

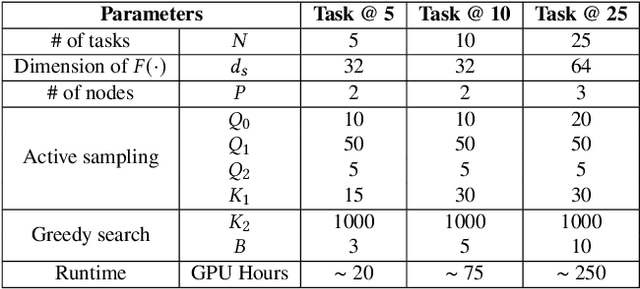

In the realm of big data and digital healthcare, Electronic Health Records (EHR) have become a rich source of information with the potential to improve patient care and medical research. In recent years, machine learning models have proliferated for analyzing EHR data to predict patients future health conditions. Among them, some studies advocate for multi-task learning (MTL) to jointly predict multiple target diseases for improving the prediction performance over single task learning. Nevertheless, current MTL frameworks for EHR data have significant limitations due to their heavy reliance on human experts to identify task groups for joint training and design model architectures. To reduce human intervention and improve the framework design, we propose an automated approach named AutoDP, which can search for the optimal configuration of task grouping and architectures simultaneously. To tackle the vast joint search space encompassing task combinations and architectures, we employ surrogate model-based optimization, enabling us to efficiently discover the optimal solution. Experimental results on real-world EHR data demonstrate the efficacy of the proposed AutoDP framework. It achieves significant performance improvements over both hand-crafted and automated state-of-the-art methods, also maintains a feasible search cost at the same time.
Automated Fusion of Multimodal Electronic Health Records for Better Medical Predictions
Jan 20, 2024The widespread adoption of Electronic Health Record (EHR) systems in healthcare institutes has generated vast amounts of medical data, offering significant opportunities for improving healthcare services through deep learning techniques. However, the complex and diverse modalities and feature structures in real-world EHR data pose great challenges for deep learning model design. To address the multi-modality challenge in EHR data, current approaches primarily rely on hand-crafted model architectures based on intuition and empirical experiences, leading to sub-optimal model architectures and limited performance. Therefore, to automate the process of model design for mining EHR data, we propose a novel neural architecture search (NAS) framework named AutoFM, which can automatically search for the optimal model architectures for encoding diverse input modalities and fusion strategies. We conduct thorough experiments on real-world multi-modal EHR data and prediction tasks, and the results demonstrate that our framework not only achieves significant performance improvement over existing state-of-the-art methods but also discovers meaningful network architectures effectively.
Hierarchical Pretraining on Multimodal Electronic Health Records
Oct 20, 2023Pretraining has proven to be a powerful technique in natural language processing (NLP), exhibiting remarkable success in various NLP downstream tasks. However, in the medical domain, existing pretrained models on electronic health records (EHR) fail to capture the hierarchical nature of EHR data, limiting their generalization capability across diverse downstream tasks using a single pretrained model. To tackle this challenge, this paper introduces a novel, general, and unified pretraining framework called MEDHMP, specifically designed for hierarchically multimodal EHR data. The effectiveness of the proposed MEDHMP is demonstrated through experimental results on eight downstream tasks spanning three levels. Comparisons against eighteen baselines further highlight the efficacy of our approach.
MedDiffusion: Boosting Health Risk Prediction via Diffusion-based Data Augmentation
Oct 05, 2023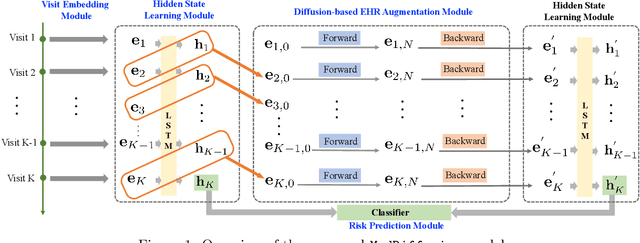
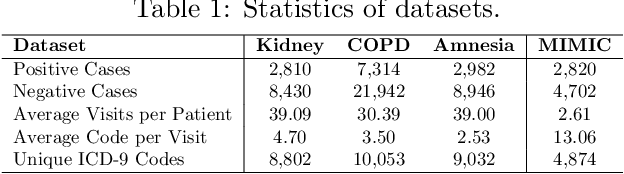
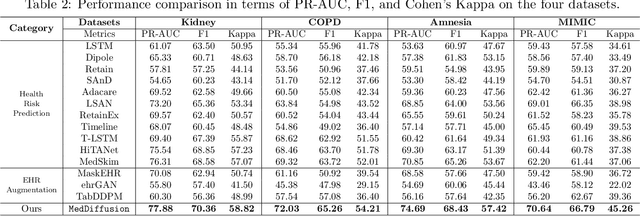
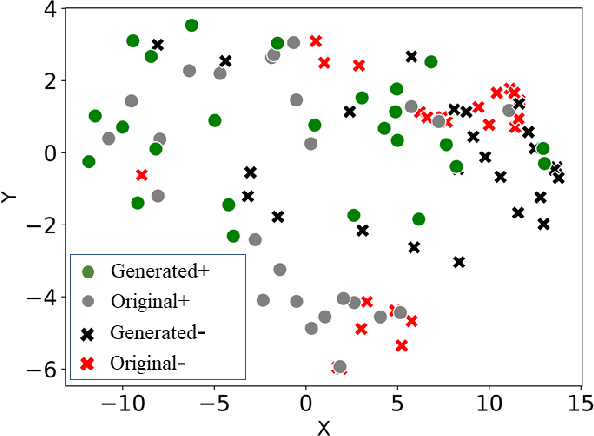
Health risk prediction is one of the fundamental tasks under predictive modeling in the medical domain, which aims to forecast the potential health risks that patients may face in the future using their historical Electronic Health Records (EHR). Researchers have developed several risk prediction models to handle the unique challenges of EHR data, such as its sequential nature, high dimensionality, and inherent noise. These models have yielded impressive results. Nonetheless, a key issue undermining their effectiveness is data insufficiency. A variety of data generation and augmentation methods have been introduced to mitigate this issue by expanding the size of the training data set through the learning of underlying data distributions. However, the performance of these methods is often limited due to their task-unrelated design. To address these shortcomings, this paper introduces a novel, end-to-end diffusion-based risk prediction model, named MedDiffusion. It enhances risk prediction performance by creating synthetic patient data during training to enlarge sample space. Furthermore, MedDiffusion discerns hidden relationships between patient visits using a step-wise attention mechanism, enabling the model to automatically retain the most vital information for generating high-quality data. Experimental evaluation on four real-world medical datasets demonstrates that MedDiffusion outperforms 14 cutting-edge baselines in terms of PR-AUC, F1, and Cohen's Kappa. We also conduct ablation studies and benchmark our model against GAN-based alternatives to further validate the rationality and adaptability of our model design. Additionally, we analyze generated data to offer fresh insights into the model's interpretability.
Towards Personalized Federated Learning via Heterogeneous Model Reassembly
Sep 06, 2023This paper focuses on addressing the practical yet challenging problem of model heterogeneity in federated learning, where clients possess models with different network structures. To track this problem, we propose a novel framework called pFedHR, which leverages heterogeneous model reassembly to achieve personalized federated learning. In particular, we approach the problem of heterogeneous model personalization as a model-matching optimization task on the server side. Moreover, pFedHR automatically and dynamically generates informative and diverse personalized candidates with minimal human intervention. Furthermore, our proposed heterogeneous model reassembly technique mitigates the adverse impact introduced by using public data with different distributions from the client data to a certain extent. Experimental results demonstrate that pFedHR outperforms baselines on three datasets under both IID and Non-IID settings. Additionally, pFedHR effectively reduces the adverse impact of using different public data and dynamically generates diverse personalized models in an automated manner.