 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Unveiling Vulnerabilities of Large Reasoning Models in Machine Unlearning
Apr 05, 2026Large language models (LLMs) possess strong semantic understanding, driving significant progress in data mining applications. This is further enhanced by large reasoning models (LRMs), which provide explicit multi-step reasoning traces. On the other hand, the growing need for the right to be forgotten has driven the development of machine unlearning techniques, which aim to eliminate the influence of specific data from trained models without full retraining. However, unlearning may also introduce new security vulnerabilities by exposing additional interaction surfaces. Although many studies have investigated unlearning attacks, there is no prior work on LRMs. To bridge the gap, we first in this paper propose LRM unlearning attack that forces incorrect final answers while generating convincing but misleading reasoning traces. This objective is challenging due to non-differentiable logical constraints, weak optimization effect over long rationales, and discrete forget set selection. To overcome these challenges, we introduce a bi-level exact unlearning attack that incorporates a differentiable objective function, influential token alignment, and a relaxed indicator strategy. To demonstrate the effectiveness and generalizability of our attack, we also design novel optimization frameworks and conduct comprehensive experiments in both white-box and black-box settings, aiming to raise awareness of the emerging threats to LRM unlearning pipelines.
Selective Forgetting for Large Reasoning Models
Apr 04, 2026Large Reasoning Models (LRMs) generate structured chains of thought (CoTs) before producing final answers, making them especially vulnerable to knowledge leakage through intermediate reasoning steps. Yet, the memorization of sensitive information in the training data such as copyrighted and private content has led to ethical and legal concerns. To address these issues, selective forgetting (also known as machine unlearning) has emerged as a potential remedy for LRMs. However, existing unlearning methods primarily target final answers and may degrade the overall reasoning ability of LRMs after forgetting. Additionally, directly applying unlearning on the entire CoTs could degrade the general reasoning capabilities. The key challenge for LRM unlearning lies in achieving precise unlearning of targeted knowledge while preserving the integrity of general reasoning capabilities. To bridge this gap, we in this paper propose a novel LRM unlearning framework that selectively removes sensitive reasoning components while preserving general reasoning capabilities. Our approach leverages multiple LLMs with retrieval-augmented generation (RAG) to analyze CoT traces, identify forget-relevant segments, and replace them with benign placeholders that maintain logical structure. We also introduce a new feature replacement unlearning loss for LRMs, which can simultaneously suppress the probability of generating forgotten content while reinforcing structurally valid replacements. Extensive experiments on both synthetic and medical datasets verify the desired properties of our proposed method.
Towards Benchmarking Privacy Vulnerabilities in Selective Forgetting with Large Language Models
Dec 19, 2025The rapid advancements in artificial intelligence (AI) have primarily focused on the process of learning from data to acquire knowledgeable learning systems. As these systems are increasingly deployed in critical areas, ensuring their privacy and alignment with human values is paramount. Recently, selective forgetting (also known as machine unlearning) has shown promise for privacy and data removal tasks, and has emerged as a transformative paradigm shift in the field of AI. It refers to the ability of a model to selectively erase the influence of previously seen data, which is especially important for compliance with modern data protection regulations and for aligning models with human values. Despite its promise, selective forgetting raises significant privacy concerns, especially when the data involved come from sensitive domains. While new unlearning-induced privacy attacks are continuously proposed, each is shown to outperform its predecessors using different experimental settings, which can lead to overly optimistic and potentially unfair assessments that may disproportionately favor one particular attack over the others. In this work, we present the first comprehensive benchmark for evaluating privacy vulnerabilities in selective forgetting. We extensively investigate privacy vulnerabilities of machine unlearning techniques and benchmark privacy leakage across a wide range of victim data, state-of-the-art unlearning privacy attacks, unlearning methods, and model architectures. We systematically evaluate and identify critical factors related to unlearning-induced privacy leakage. With our novel insights, we aim to provide a standardized tool for practitioners seeking to deploy customized unlearning applications with faithful privacy assessments.
Towards Unveiling Predictive Uncertainty Vulnerabilities in the Context of the Right to Be Forgotten
Aug 10, 2025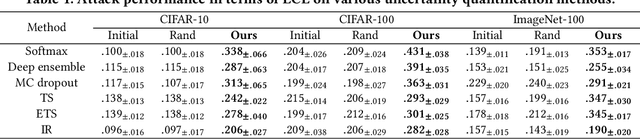
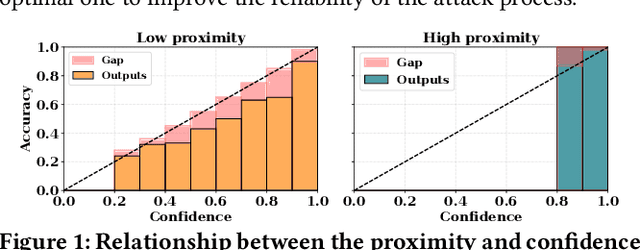
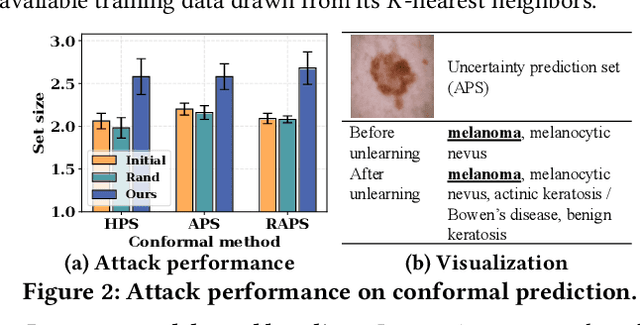
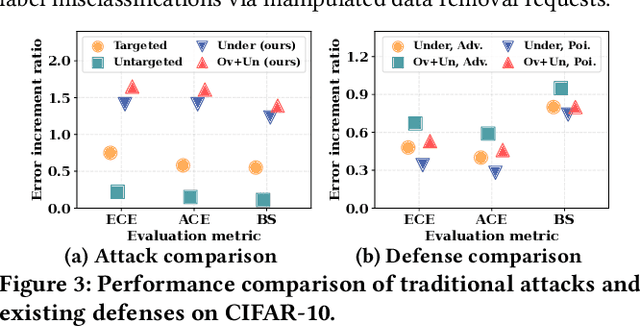
Currently, various uncertainty quantification methods have been proposed to provide certainty and probability estimates for deep learning models' label predictions. Meanwhile, with the growing demand for the right to be forgotten, machine unlearning has been extensively studied as a means to remove the impact of requested sensitive data from a pre-trained model without retraining the model from scratch. However, the vulnerabilities of such generated predictive uncertainties with regard to dedicated malicious unlearning attacks remain unexplored. To bridge this gap, for the first time, we propose a new class of malicious unlearning attacks against predictive uncertainties, where the adversary aims to cause the desired manipulations of specific predictive uncertainty results. We also design novel optimization frameworks for our attacks and conduct extensive experiments, including black-box scenarios. Notably, our extensive experiments show that our attacks are more effective in manipulating predictive uncertainties than traditional attacks that focus on label misclassifications, and existing defenses against conventional attacks are ineffective against our attacks.
Membership Inference Attacks with False Discovery Rate Control
Aug 09, 2025



Recent studies have shown that deep learning models are vulnerable to membership inference attacks (MIAs), which aim to infer whether a data record was used to train a target model or not. To analyze and study these vulnerabilities, various MIA methods have been proposed. Despite the significance and popularity of MIAs, existing works on MIAs are limited in providing guarantees on the false discovery rate (FDR), which refers to the expected proportion of false discoveries among the identified positive discoveries. However, it is very challenging to ensure the false discovery rate guarantees, because the underlying distribution is usually unknown, and the estimated non-member probabilities often exhibit interdependence. To tackle the above challenges, in this paper, we design a novel membership inference attack method, which can provide the guarantees on the false discovery rate. Additionally, we show that our method can also provide the marginal probability guarantee on labeling true non-member data as member data. Notably, our method can work as a wrapper that can be seamlessly integrated with existing MIA methods in a post-hoc manner, while also providing the FDR control. We perform the theoretical analysis for our method. Extensive experiments in various settings (e.g., the black-box setting and the lifelong learning setting) are also conducted to verify the desirable performance of our method.
Synthesizing Multimodal Electronic Health Records via Predictive Diffusion Models
Jun 20, 2024



Synthesizing electronic health records (EHR) data has become a preferred strategy to address data scarcity, improve data quality, and model fairness in healthcare. However, existing approaches for EHR data generation predominantly rely on state-of-the-art generative techniques like generative adversarial networks, variational autoencoders, and language models. These methods typically replicate input visits, resulting in inadequate modeling of temporal dependencies between visits and overlooking the generation of time information, a crucial element in EHR data. Moreover, their ability to learn visit representations is limited due to simple linear mapping functions, thus compromising generation quality. To address these limitations, we propose a novel EHR data generation model called EHRPD. It is a diffusion-based model designed to predict the next visit based on the current one while also incorporating time interval estimation. To enhance generation quality and diversity, we introduce a novel time-aware visit embedding module and a pioneering predictive denoising diffusion probabilistic model (PDDPM). Additionally, we devise a predictive U-Net (PU-Net) to optimize P-DDPM.We conduct experiments on two public datasets and evaluate EHRPD from fidelity, privacy, and utility perspectives. The experimental results demonstrate the efficacy and utility of the proposed EHRPD in addressing the aforementioned limitations and advancing EHR data generation.
Exploring Fairness in Educational Data Mining in the Context of the Right to be Forgotten
May 29, 2024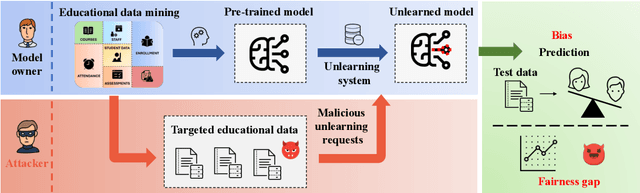



In education data mining (EDM) communities, machine learning has achieved remarkable success in discovering patterns and structures to tackle educational challenges. Notably, fairness and algorithmic bias have gained attention in learning analytics of EDM. With the increasing demand for the right to be forgotten, there is a growing need for machine learning models to forget sensitive data and its impact, particularly within the realm of EDM. The paradigm of selective forgetting, also known as machine unlearning, has been extensively studied to address this need by eliminating the influence of specific data from a pre-trained model without complete retraining. However, existing research assumes that interactive data removal operations are conducted in secure and reliable environments, neglecting potential malicious unlearning requests to undermine the fairness of machine learning systems. In this paper, we introduce a novel class of selective forgetting attacks designed to compromise the fairness of learning models while maintaining their predictive accuracy, thereby preventing the model owner from detecting the degradation in model performance. Additionally, we propose an innovative optimization framework for selective forgetting attacks, capable of generating malicious unlearning requests across various attack scenarios. We validate the effectiveness of our proposed selective forgetting attacks on fairness through extensive experiments using diverse EDM datasets.
Towards Modeling Uncertainties of Self-explaining Neural Networks via Conformal Prediction
Jan 03, 2024



Despite the recent progress in deep neural networks (DNNs), it remains challenging to explain the predictions made by DNNs. Existing explanation methods for DNNs mainly focus on post-hoc explanations where another explanatory model is employed to provide explanations. The fact that post-hoc methods can fail to reveal the actual original reasoning process of DNNs raises the need to build DNNs with built-in interpretability. Motivated by this, many self-explaining neural networks have been proposed to generate not only accurate predictions but also clear and intuitive insights into why a particular decision was made. However, existing self-explaining networks are limited in providing distribution-free uncertainty quantification for the two simultaneously generated prediction outcomes (i.e., a sample's final prediction and its corresponding explanations for interpreting that prediction). Importantly, they also fail to establish a connection between the confidence values assigned to the generated explanations in the interpretation layer and those allocated to the final predictions in the ultimate prediction layer. To tackle the aforementioned challenges, in this paper, we design a novel uncertainty modeling framework for self-explaining networks, which not only demonstrates strong distribution-free uncertainty modeling performance for the generated explanations in the interpretation layer but also excels in producing efficient and effective prediction sets for the final predictions based on the informative high-level basis explanations. We perform the theoretical analysis for the proposed framework. Extensive experimental evaluation demonstrates the effectiveness of the proposed uncertainty framework.
AdvST: Revisiting Data Augmentations for Single Domain Generalization
Dec 20, 2023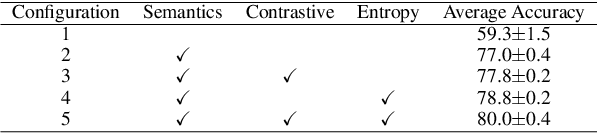
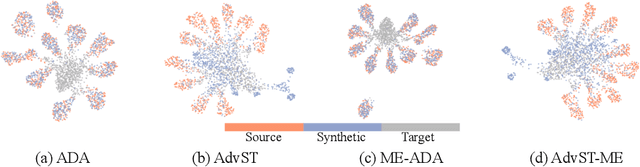
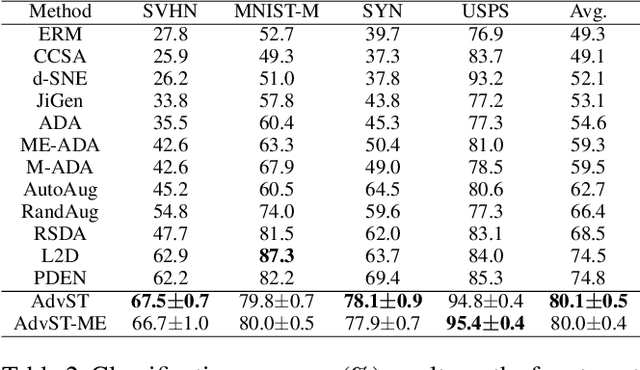
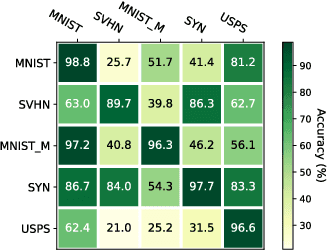
Single domain generalization (SDG) aims to train a robust model against unknown target domain shifts using data from a single source domain. Data augmentation has been proven an effective approach to SDG. However, the utility of standard augmentations, such as translate, or invert, has not been fully exploited in SDG; practically, these augmentations are used as a part of a data preprocessing procedure. Although it is intuitive to use many such augmentations to boost the robustness of a model to out-of-distribution domain shifts, we lack a principled approach to harvest the benefit brought from multiple these augmentations. Here, we conceptualize standard data augmentations with learnable parameters as semantics transformations that can manipulate certain semantics of a sample, such as the geometry or color of an image. Then, we propose Adversarial learning with Semantics Transformations (AdvST) that augments the source domain data with semantics transformations and learns a robust model with the augmented data. We theoretically show that AdvST essentially optimizes a distributionally robust optimization objective defined on a set of semantics distributions induced by the parameters of semantics transformations. We demonstrate that AdvST can produce samples that expand the coverage on target domain data. Compared with the state-of-the-art methods, AdvST, despite being a simple method, is surprisingly competitive and achieves the best average SDG performance on the Digits, PACS, and DomainNet datasets. Our code is available at https://github.com/gtzheng/AdvST.
Improving Faithfulness for Vision Transformers
Nov 29, 2023



Vision Transformers (ViTs) have achieved state-of-the-art performance for various vision tasks. One reason behind the success lies in their ability to provide plausible innate explanations for the behavior of neural architectures. However, ViTs suffer from issues with explanation faithfulness, as their focal points are fragile to adversarial attacks and can be easily changed with even slight perturbations on the input image. In this paper, we propose a rigorous approach to mitigate these issues by introducing Faithful ViTs (FViTs). Briefly speaking, an FViT should have the following two properties: (1) The top-$k$ indices of its self-attention vector should remain mostly unchanged under input perturbation, indicating stable explanations; (2) The prediction distribution should be robust to perturbations. To achieve this, we propose a new method called Denoised Diffusion Smoothing (DDS), which adopts randomized smoothing and diffusion-based denoising. We theoretically prove that processing ViTs directly with DDS can turn them into FViTs. We also show that Gaussian noise is nearly optimal for both $\ell_2$ and $\ell_\infty$-norm cases. Finally, we demonstrate the effectiveness of our approach through comprehensive experiments and evaluations. Specifically, we compare our FViTs with other baselines through visual interpretation and robustness accuracy under adversarial attacks. Results show that FViTs are more robust against adversarial attacks while maintaining the explainability of attention, indicating higher faithfulness.