 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSEAT: Stable and Explainable Attention
Paper and Code
Nov 23, 2022


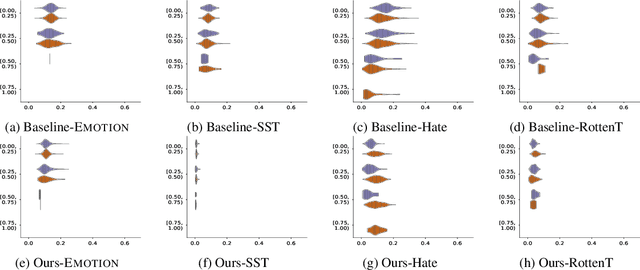
Currently, attention mechanism becomes a standard fixture in most state-of-the-art natural language processing (NLP) models, not only due to outstanding performance it could gain, but also due to plausible innate explanation for the behaviors of neural architectures it provides, which is notoriously difficult to analyze. However, recent studies show that attention is unstable against randomness and perturbations during training or testing, such as random seeds and slight perturbation of embedding vectors, which impedes it from becoming a faithful explanation tool. Thus, a natural question is whether we can find some substitute of the current attention which is more stable and could keep the most important characteristics on explanation and prediction of attention. In this paper, to resolve the problem, we provide a first rigorous definition of such alternate namely SEAT (Stable and Explainable Attention). Specifically, a SEAT should has the following three properties: (1) Its prediction distribution is enforced to be close to the distribution based on the vanilla attention; (2) Its top-k indices have large overlaps with those of the vanilla attention; (3) It is robust w.r.t perturbations, i.e., any slight perturbation on SEAT will not change the prediction distribution too much, which implicitly indicates that it is stable to randomness and perturbations. Finally, through intensive experiments on various datasets, we compare our SEAT with other baseline methods using RNN, BiLSTM and BERT architectures via six different evaluation metrics for model interpretation, stability and accuracy. Results show that SEAT is more stable against different perturbations and randomness while also keeps the explainability of attention, which indicates it is a more faithful explanation. Moreover, compared with vanilla attention, there is almost no utility (accuracy) degradation for SEAT.