 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHave We Really Understood Collaborative Information? An Empirical Investigation
Nov 10, 2025Collaborative information serves as the cornerstone of recommender systems which typically focus on capturing it from user-item interactions to deliver personalized services. However, current understanding of this crucial resource remains limited. Specifically, a quantitative definition of collaborative information is missing, its manifestation within user-item interactions remains unclear, and its impact on recommendation performance is largely unknown. To bridge this gap, this work conducts a systematic investigation of collaborative information. We begin by clarifying collaborative information in terms of item co-occurrence patterns, identifying its main characteristics, and presenting a quantitative definition. We then estimate the distribution of collaborative information from several aspects, shedding light on how collaborative information is structured in practice. Furthermore, we evaluate the impact of collaborative information on the performance of various recommendation algorithms. Finally, we highlight challenges in effectively capturing collaborative information and outlook promising directions for future research. By establishing an empirical framework, we uncover many insightful observations that advance our understanding of collaborative information and offer valuable guidelines for developing more effective recommender systems.
Rethinking Contrastive Learning in Session-based Recommendation
Jun 05, 2025



Session-based recommendation aims to predict intents of anonymous users based on limited behaviors. With the ability in alleviating data sparsity, contrastive learning is prevailing in the task. However, we spot that existing contrastive learning based methods still suffer from three obstacles: (1) they overlook item-level sparsity and primarily focus on session-level sparsity; (2) they typically augment sessions using item IDs like crop, mask and reorder, failing to ensure the semantic consistency of augmented views; (3) they treat all positive-negative signals equally, without considering their varying utility. To this end, we propose a novel multi-modal adaptive contrastive learning framework called MACL for session-based recommendation. In MACL, a multi-modal augmentation is devised to generate semantically consistent views at both item and session levels by leveraging item multi-modal features. Besides, we present an adaptive contrastive loss that distinguishes varying contributions of positive-negative signals to improve self-supervised learning. Extensive experiments on three real-world datasets demonstrate the superiority of MACL over state-of-the-art methods.
Shapley Value-driven Data Pruning for Recommender Systems
May 28, 2025Recommender systems often suffer from noisy interactions like accidental clicks or popularity bias. Existing denoising methods typically identify users' intent in their interactions, and filter out noisy interactions that deviate from the assumed intent. However, they ignore that interactions deemed noisy could still aid model training, while some ``clean'' interactions offer little learning value. To bridge this gap, we propose Shapley Value-driven Valuation (SVV), a framework that evaluates interactions based on their objective impact on model training rather than subjective intent assumptions. In SVV, a real-time Shapley value estimation method is devised to quantify each interaction's value based on its contribution to reducing training loss. Afterward, SVV highlights the interactions with high values while downplaying low ones to achieve effective data pruning for recommender systems. In addition, we develop a simulated noise protocol to examine the performance of various denoising approaches systematically. Experiments on four real-world datasets show that SVV outperforms existing denoising methods in both accuracy and robustness. Further analysis also demonstrates that our SVV can preserve training-critical interactions and offer interpretable noise assessment. This work shifts denoising from heuristic filtering to principled, model-driven interaction valuation.
Counterfactual Multi-player Bandits for Explainable Recommendation Diversification
May 27, 2025Existing recommender systems tend to prioritize items closely aligned with users' historical interactions, inevitably trapping users in the dilemma of ``filter bubble''. Recent efforts are dedicated to improving the diversity of recommendations. However, they mainly suffer from two major issues: 1) a lack of explainability, making it difficult for the system designers to understand how diverse recommendations are generated, and 2) limitations to specific metrics, with difficulty in enhancing non-differentiable diversity metrics. To this end, we propose a \textbf{C}ounterfactual \textbf{M}ulti-player \textbf{B}andits (CMB) method to deliver explainable recommendation diversification across a wide range of diversity metrics. Leveraging a counterfactual framework, our method identifies the factors influencing diversity outcomes. Meanwhile, we adopt the multi-player bandits to optimize the counterfactual optimization objective, making it adaptable to both differentiable and non-differentiable diversity metrics. Extensive experiments conducted on three real-world datasets demonstrate the applicability, effectiveness, and explainability of the proposed CMB.
A Survey on Side Information-driven Session-based Recommendation: From a Data-centric Perspective
May 18, 2025Session-based recommendation is gaining increasing attention due to its practical value in predicting the intents of anonymous users based on limited behaviors. Emerging efforts incorporate various side information to alleviate inherent data scarcity issues in this task, leading to impressive performance improvements. The core of side information-driven session-based recommendation is the discovery and utilization of diverse data. In this survey, we provide a comprehensive review of this task from a data-centric perspective. Specifically, this survey commences with a clear formulation of the task. This is followed by a detailed exploration of various benchmarks rich in side information that are pivotal for advancing research in this field. Afterwards, we delve into how different types of side information enhance the task, underscoring data characteristics and utility. Moreover, we discuss the usage of various side information, including data encoding, data injection, and involved techniques. A systematic review of research progress is then presented, with the taxonomy by the types of side information. Finally, we summarize the current limitations and present the future prospects of this vibrant topic.
Semantic Retrieval Augmented Contrastive Learning for Sequential Recommendation
Mar 06, 2025Sequential recommendation aims to model user preferences based on historical behavior sequences, which is crucial for various online platforms. Data sparsity remains a significant challenge in this area as most users have limited interactions and many items receive little attention. To mitigate this issue, contrastive learning has been widely adopted. By constructing positive sample pairs from the data itself and maximizing their agreement in the embedding space,it can leverage available data more effectively. Constructing reasonable positive sample pairs is crucial for the success of contrastive learning. However, current approaches struggle to generate reliable positive pairs as they either rely on representations learned from inherently sparse collaborative signals or use random perturbations which introduce significant uncertainty. To address these limitations, we propose a novel approach named Semantic Retrieval Augmented Contrastive Learning (SRA-CL), which leverages semantic information to improve the reliability of contrastive samples. SRA-CL comprises two main components: (1) Cross-Sequence Contrastive Learning via User Semantic Retrieval, which utilizes large language models (LLMs) to understand diverse user preferences and retrieve semantically similar users to form reliable positive samples through a learnable sample synthesis method; and (2) Intra-Sequence Contrastive Learning via Item Semantic Retrieval, which employs LLMs to comprehend items and retrieve similar items to perform semantic-based item substitution, thereby creating semantically consistent augmented views for contrastive learning. SRA-CL is plug-and-play and can be integrated into standard sequential recommendation models. Extensive experiments on four public datasets demonstrate the effectiveness and generalizability of the proposed approach.
PASER: Post-Training Data Selection for Efficient Pruned Large Language Model Recovery
Feb 18, 2025Model pruning is an effective approach for compressing large language models. However, this process often leads to significant degradation of model capabilities. While post-training techniques such as instruction tuning are commonly employed to recover model performance, existing methods often overlook the uneven deterioration of model capabilities and incur high computational costs. Moreover, some instruction data irrelevant to model capability recovery may introduce negative effects. To address these challenges, we propose the \textbf{P}ost-training d\textbf{A}ta \textbf{S}election method for \textbf{E}fficient pruned large language model \textbf{R}ecovery (\textbf{PASER}). PASER aims to identify instructions where model capabilities are most severely compromised within a certain recovery data budget. Our approach first applies manifold learning and spectral clustering to group recovery data in the semantic space, revealing capability-specific instruction sets. We then adaptively allocate the data budget to different clusters based on the degrees of model capability degradation. In each cluster, we prioritize data samples where model performance has declined dramatically. To mitigate potential negative transfer, we also detect and filter out conflicting or irrelevant recovery data. Extensive experiments demonstrate that PASER significantly outperforms conventional baselines, effectively recovering the general capabilities of pruned LLMs while utilizing merely 4\%-20\% of the original post-training data.
Beyond Models! Explainable Data Valuation and Metric Adaption for Recommendation
Feb 12, 2025User behavior records serve as the foundation for recommender systems. While the behavior data exhibits ease of acquisition, it often suffers from varying quality. Current methods employ data valuation to discern high-quality data from low-quality data. However, they tend to employ black-box design, lacking transparency and interpretability. Besides, they are typically tailored to specific evaluation metrics, leading to limited generality across various tasks. To overcome these issues, we propose an explainable and versatile framework DVR which can enhance the efficiency of data utilization tailored to any requirements of the model architectures and evaluation metrics. For explainable data valuation, a data valuator is presented to evaluate the data quality via calculating its Shapley value from the game-theoretic perspective, ensuring robust mathematical properties and reliability. In order to accommodate various evaluation metrics, including differentiable and non-differentiable ones, a metric adapter is devised based on reinforcement learning, where a metric is treated as the reinforcement reward that guides model optimization. Extensive experiments conducted on various benchmarks verify that our framework can improve the performance of current recommendation algorithms on various metrics including ranking accuracy, diversity, and fairness. Specifically, our framework achieves up to 34.7\% improvements over existing methods in terms of representative NDCG metric. The code is available at https://github.com/renqii/DVR.
Commonality and Individuality! Integrating Humor Commonality with Speaker Individuality for Humor Recognition
Feb 07, 2025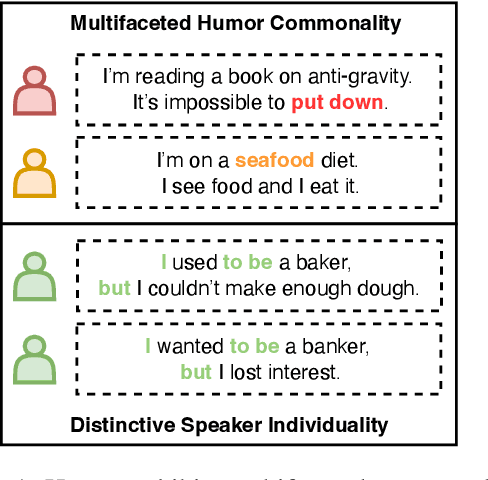

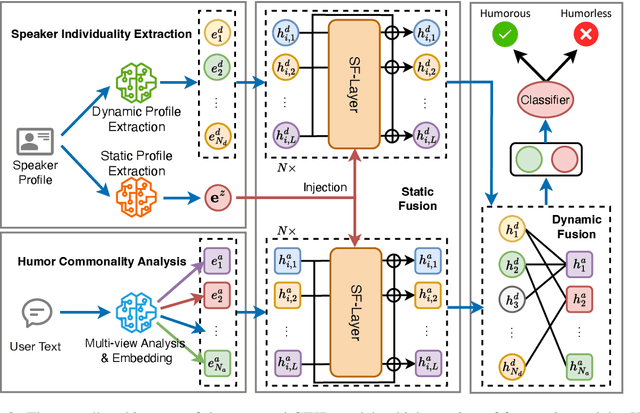

Humor recognition aims to identify whether a specific speaker's text is humorous. Current methods for humor recognition mainly suffer from two limitations: (1) they solely focus on one aspect of humor commonalities, ignoring the multifaceted nature of humor; and (2) they typically overlook the critical role of speaker individuality, which is essential for a comprehensive understanding of humor expressions. To bridge these gaps, we introduce the Commonality and Individuality Incorporated Network for Humor Recognition (CIHR), a novel model designed to enhance humor recognition by integrating multifaceted humor commonalities with the distinctive individuality of speakers. The CIHR features a Humor Commonality Analysis module that explores various perspectives of multifaceted humor commonality within user texts, and a Speaker Individuality Extraction module that captures both static and dynamic aspects of a speaker's profile to accurately model their distinctive individuality. Additionally, Static and Dynamic Fusion modules are introduced to effectively incorporate the humor commonality with speaker's individuality in the humor recognition process. Extensive experiments demonstrate the effectiveness of CIHR, underscoring the importance of concurrently addressing both multifaceted humor commonality and distinctive speaker individuality in humor recognition.
Towards Comprehensive Detection of Chinese Harmful Memes
Oct 03, 2024



This paper has been accepted in the NeurIPS 2024 D & B Track. Harmful memes have proliferated on the Chinese Internet, while research on detecting Chinese harmful memes significantly lags behind due to the absence of reliable datasets and effective detectors. To this end, we focus on the comprehensive detection of Chinese harmful memes. We construct ToxiCN MM, the first Chinese harmful meme dataset, which consists of 12,000 samples with fine-grained annotations for various meme types. Additionally, we propose a baseline detector, Multimodal Knowledge Enhancement (MKE), incorporating contextual information of meme content generated by the LLM to enhance the understanding of Chinese memes. During the evaluation phase, we conduct extensive quantitative experiments and qualitative analyses on multiple baselines, including LLMs and our MKE. The experimental results indicate that detecting Chinese harmful memes is challenging for existing models while demonstrating the effectiveness of MKE. The resources for this paper are available at https://github.com/DUT-lujunyu/ToxiCN_MM.