 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlossomRec: Block-level Fused Sparse Attention Mechanism for Sequential Recommendations
Dec 15, 2025Transformer structures have been widely used in sequential recommender systems (SRS). However, as user interaction histories increase, computational time and memory requirements also grow. This is mainly caused by the standard attention mechanism. Although there exist many methods employing efficient attention and SSM-based models, these approaches struggle to effectively model long sequences and may exhibit unstable performance on short sequences. To address these challenges, we design a sparse attention mechanism, BlossomRec, which models both long-term and short-term user interests through attention computation to achieve stable performance across sequences of varying lengths. Specifically, we categorize user interests in recommendation systems into long-term and short-term interests, and compute them using two distinct sparse attention patterns, with the results combined through a learnable gated output. Theoretically, it significantly reduces the number of interactions participating in attention computation. Extensive experiments on four public datasets demonstrate that BlossomRec, when integrated with state-of-the-art Transformer-based models, achieves comparable or even superior performance while significantly reducing memory usage, providing strong evidence of BlossomRec's efficiency and effectiveness.The code is available at https://github.com/ronineume/BlossomRec.
Timing is important: Risk-aware Fund Allocation based on Time-Series Forecasting
May 30, 2025Fund allocation has been an increasingly important problem in the financial domain. In reality, we aim to allocate the funds to buy certain assets within a certain future period. Naive solutions such as prediction-only or Predict-then-Optimize approaches suffer from goal mismatch. Additionally, the introduction of the SOTA time series forecasting model inevitably introduces additional uncertainty in the predicted result. To solve both problems mentioned above, we introduce a Risk-aware Time-Series Predict-and-Allocate (RTS-PnO) framework, which holds no prior assumption on the forecasting models. Such a framework contains three features: (i) end-to-end training with objective alignment measurement, (ii) adaptive forecasting uncertainty calibration, and (iii) agnostic towards forecasting models. The evaluation of RTS-PnO is conducted over both online and offline experiments. For offline experiments, eight datasets from three categories of financial applications are used: Currency, Stock, and Cryptos. RTS-PnO consistently outperforms other competitive baselines. The online experiment is conducted on the Cross-Border Payment business at FiT, Tencent, and an 8.4\% decrease in regret is witnessed when compared with the product-line approach. The code for the offline experiment is available at https://github.com/fuyuanlyu/RTS-PnO.
Semantic Retrieval Augmented Contrastive Learning for Sequential Recommendation
Mar 06, 2025Sequential recommendation aims to model user preferences based on historical behavior sequences, which is crucial for various online platforms. Data sparsity remains a significant challenge in this area as most users have limited interactions and many items receive little attention. To mitigate this issue, contrastive learning has been widely adopted. By constructing positive sample pairs from the data itself and maximizing their agreement in the embedding space,it can leverage available data more effectively. Constructing reasonable positive sample pairs is crucial for the success of contrastive learning. However, current approaches struggle to generate reliable positive pairs as they either rely on representations learned from inherently sparse collaborative signals or use random perturbations which introduce significant uncertainty. To address these limitations, we propose a novel approach named Semantic Retrieval Augmented Contrastive Learning (SRA-CL), which leverages semantic information to improve the reliability of contrastive samples. SRA-CL comprises two main components: (1) Cross-Sequence Contrastive Learning via User Semantic Retrieval, which utilizes large language models (LLMs) to understand diverse user preferences and retrieve semantically similar users to form reliable positive samples through a learnable sample synthesis method; and (2) Intra-Sequence Contrastive Learning via Item Semantic Retrieval, which employs LLMs to comprehend items and retrieve similar items to perform semantic-based item substitution, thereby creating semantically consistent augmented views for contrastive learning. SRA-CL is plug-and-play and can be integrated into standard sequential recommendation models. Extensive experiments on four public datasets demonstrate the effectiveness and generalizability of the proposed approach.
A Predict-Then-Optimize Customer Allocation Framework for Online Fund Recommendation
Mar 05, 2025With the rapid growth of online investment platforms, funds can be distributed to individual customers online. The central issue is to match funds with potential customers under constraints. Most mainstream platforms adopt the recommendation formulation to tackle the problem. However, the traditional recommendation regime has its inherent drawbacks when applying the fund-matching problem with multiple constraints. In this paper, we model the fund matching under the allocation formulation. We design PTOFA, a Predict-Then-Optimize Fund Allocation framework. This data-driven framework consists of two stages, i.e., prediction and optimization, which aim to predict expected revenue based on customer behavior and optimize the impression allocation to achieve the maximum revenue under the necessary constraints, respectively. Extensive experiments on real-world datasets from an industrial online investment platform validate the effectiveness and efficiency of our solution. Additionally, the online A/B tests demonstrate PTOFA's effectiveness in the real-world fund recommendation scenario.
Comprehending Knowledge Graphs with Large Language Models for Recommender Systems
Oct 16, 2024Recently, the introduction of knowledge graphs (KGs) has significantly advanced recommender systems by facilitating the discovery of potential associations between items. However, existing methods still face several limitations. First, most KGs suffer from missing facts or limited scopes. This can lead to biased knowledge representations, thereby constraining the model's performance. Second, existing methods typically convert textual information into IDs, resulting in the loss of natural semantic connections between different items. Third, existing methods struggle to capture high-order relationships in global KGs due to their inefficient layer-by-layer information propagation mechanisms, which are prone to introducing significant noise. To address these limitations, we propose a novel method called CoLaKG, which leverages large language models (LLMs) for knowledge-aware recommendation. The extensive world knowledge and remarkable reasoning capabilities of LLMs enable them to supplement KGs. Additionally, the strong text comprehension abilities of LLMs allow for a better understanding of semantic information. Based on this, we first extract subgraphs centered on each item from the KG and convert them into textual inputs for the LLM. The LLM then outputs its comprehension of these item-centered subgraphs, which are subsequently transformed into semantic embeddings. Furthermore, to utilize the global information of the KG, we construct an item-item graph using these semantic embeddings, which can directly capture higher-order associations between items. Both the semantic embeddings and the structural information from the item-item graph are effectively integrated into the recommendation model through our designed representation alignment and neighbor augmentation modules. Extensive experiments on four real-world datasets demonstrate the superiority of our method.
End-to-End Cost-Effective Incentive Recommendation under Budget Constraint with Uplift Modeling
Aug 21, 2024



In modern online platforms, incentives are essential factors that enhance user engagement and increase platform revenue. Over recent years, uplift modeling has been introduced as a strategic approach to assign incentives to individual customers. Especially in many real-world applications, online platforms can only incentivize customers with specific budget constraints. This problem can be reformulated as the multi-choice knapsack problem. This optimization aims to select the optimal incentive for each customer to maximize the return on investment. Recent works in this field frequently tackle the budget allocation problem using a two-stage approach. However, this solution is confronted with the following challenges: (1) The causal inference methods often ignore the domain knowledge in online marketing, where the expected response curve of a customer should be monotonic and smooth as the incentive increases. (2) An optimality gap between the two stages results in inferior sub-optimal allocation performance due to the loss of the incentive recommendation information for the uplift prediction under the limited budget constraint. To address these challenges, we propose a novel End-to-End Cost-Effective Incentive Recommendation (E3IR) model under budget constraints. Specifically, our methods consist of two modules, i.e., the uplift prediction module and the differentiable allocation module. In the uplift prediction module, we construct prediction heads to capture the incremental improvement between adjacent treatments with the marketing domain constraints (i.e., monotonic and smooth). We incorporate integer linear programming (ILP) as a differentiable layer input in the allocation module. Furthermore, we conduct extensive experiments on public and real product datasets, demonstrating that our E3IR improves allocation performance compared to existing two-stage approaches.
OptDist: Learning Optimal Distribution for Customer Lifetime Value Prediction
Aug 16, 2024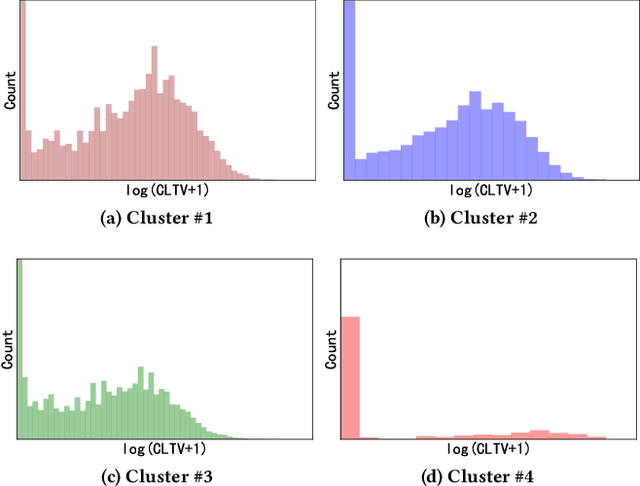
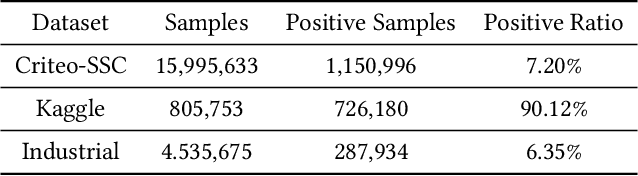
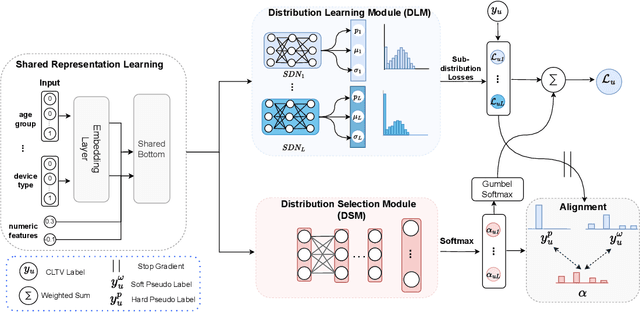
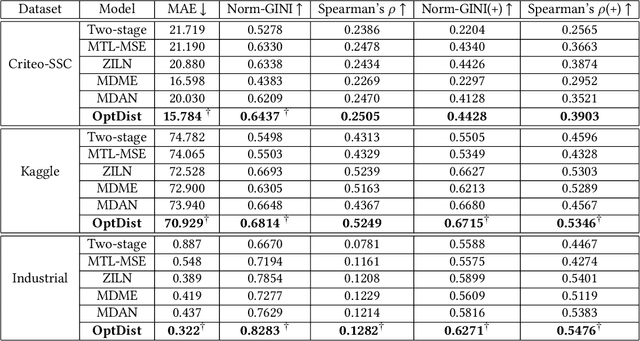
Customer Lifetime Value (CLTV) prediction is a critical task in business applications. Accurately predicting CLTV is challenging in real-world business scenarios, as the distribution of CLTV is complex and mutable. Firstly, there is a large number of users without any consumption consisting of a long-tailed part that is too complex to fit. Secondly, the small set of high-value users spent orders of magnitude more than a typical user leading to a wide range of the CLTV distribution which is hard to capture in a single distribution. Existing approaches for CLTV estimation either assume a prior probability distribution and fit a single group of distribution-related parameters for all samples, or directly learn from the posterior distribution with manually predefined buckets in a heuristic manner. However, all these methods fail to handle complex and mutable distributions. In this paper, we propose a novel optimal distribution selection model OptDist for CLTV prediction, which utilizes an adaptive optimal sub-distribution selection mechanism to improve the accuracy of complex distribution modeling. Specifically, OptDist trains several candidate sub-distribution networks in the distribution learning module (DLM) for modeling the probability distribution of CLTV. Then, a distribution selection module (DSM) is proposed to select the sub-distribution for each sample, thus making the selection automatically and adaptively. Besides, we design an alignment mechanism that connects both modules, which effectively guides the optimization. We conduct extensive experiments on both two public and one private dataset to verify that OptDist outperforms state-of-the-art baselines. Furthermore, OptDist has been deployed on a large-scale financial platform for customer acquisition marketing campaigns and the online experiments also demonstrate the effectiveness of OptDist.
Rankability-enhanced Revenue Uplift Modeling Framework for Online Marketing
May 24, 2024



Uplift modeling has been widely employed in online marketing by predicting the response difference between the treatment and control groups, so as to identify the sensitive individuals toward interventions like coupons or discounts. Compared with traditional \textit{conversion uplift modeling}, \textit{revenue uplift modeling} exhibits higher potential due to its direct connection with the corporate income. However, previous works can hardly handle the continuous long-tail response distribution in revenue uplift modeling. Moreover, they have neglected to optimize the uplift ranking among different individuals, which is actually the core of uplift modeling. To address such issues, in this paper, we first utilize the zero-inflated lognormal (ZILN) loss to regress the responses and customize the corresponding modeling network, which can be adapted to different existing uplift models. Then, we study the ranking-related uplift modeling error from the theoretical perspective and propose two tighter error bounds as the additional loss terms to the conventional response regression loss. Finally, we directly model the uplift ranking error for the entire population with a listwise uplift ranking loss. The experiment results on offline public and industrial datasets validate the effectiveness of our method for revenue uplift modeling. Furthermore, we conduct large-scale experiments on a prominent online fintech marketing platform, Tencent FiT, which further demonstrates the superiority of our method in practical applications.
Expected Transaction Value Optimization for Precise Marketing in FinTech Platforms
Jan 03, 2024FinTech platforms facilitated by digital payments are watching growth rapidly, which enable the distribution of mutual funds personalized to individual investors via mobile Apps. As the important intermediation of financial products investment, these platforms distribute thousands of mutual funds obtaining impressions under guaranteed delivery (GD) strategy required by fund companies. Driven by the profit from fund purchases of users, the platform aims to maximize each transaction amount of customers by promoting mutual funds to these investors who will be interested in. Different from the conversions in traditional advertising or e-commerce recommendations, the investment amount in each purchase varies greatly even for the same financial product, which provides a significant challenge for the promotion recommendation of mutual funds. In addition to predicting the click-through rate (CTR) or the conversion rate (CVR) as in traditional recommendations, it is essential for FinTech platforms to estimate the customers' purchase amount for each delivered fund and achieve an effective allocation of impressions based on the predicted results to optimize the total expected transaction value (ETV). In this paper, we propose an ETV optimized customer allocation framework (EOCA) that aims to maximize the total ETV of recommended funds, under the constraints of GD dealt with fund companies. To the best of our knowledge, it's the first attempt to solve the GD problem for financial product promotions based on customer purchase amount prediction. We conduct extensive experiments on large scale real-world datasets and online tests based on LiCaiTong, Tencent wealth management platform, to demonstrate the effectiveness of our proposed EOCA framework.
Curriculum Modeling the Dependence among Targets with Multi-task Learning for Financial Marketing
Apr 25, 2023Multi-task learning for various real-world applications usually involves tasks with logical sequential dependence. For example, in online marketing, the cascade behavior pattern of $impression \rightarrow click \rightarrow conversion$ is usually modeled as multiple tasks in a multi-task manner, where the sequential dependence between tasks is simply connected with an explicitly defined function or implicitly transferred information in current works. These methods alleviate the data sparsity problem for long-path sequential tasks as the positive feedback becomes sparser along with the task sequence. However, the error accumulation and negative transfer will be a severe problem for downstream tasks. Especially, at the beginning stage of training, the optimization for parameters of former tasks is not converged yet, and thus the information transferred to downstream tasks is negative. In this paper, we propose a prior information merged model (\textbf{PIMM}), which explicitly models the logical dependence among tasks with a novel prior information merged (\textbf{PIM}) module for multiple sequential dependence task learning in a curriculum manner. Specifically, the PIM randomly selects the true label information or the prior task prediction with a soft sampling strategy to transfer to the downstream task during the training. Following an easy-to-difficult curriculum paradigm, we dynamically adjust the sampling probability to ensure that the downstream task will get the effective information along with the training. The offline experimental results on both public and product datasets verify that PIMM outperforms state-of-the-art baselines. Moreover, we deploy the PIMM in a large-scale FinTech platform, and the online experiments also demonstrate the effectiveness of PIMM.