 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Benchmarking Privacy Vulnerabilities in Selective Forgetting with Large Language Models
Dec 19, 2025The rapid advancements in artificial intelligence (AI) have primarily focused on the process of learning from data to acquire knowledgeable learning systems. As these systems are increasingly deployed in critical areas, ensuring their privacy and alignment with human values is paramount. Recently, selective forgetting (also known as machine unlearning) has shown promise for privacy and data removal tasks, and has emerged as a transformative paradigm shift in the field of AI. It refers to the ability of a model to selectively erase the influence of previously seen data, which is especially important for compliance with modern data protection regulations and for aligning models with human values. Despite its promise, selective forgetting raises significant privacy concerns, especially when the data involved come from sensitive domains. While new unlearning-induced privacy attacks are continuously proposed, each is shown to outperform its predecessors using different experimental settings, which can lead to overly optimistic and potentially unfair assessments that may disproportionately favor one particular attack over the others. In this work, we present the first comprehensive benchmark for evaluating privacy vulnerabilities in selective forgetting. We extensively investigate privacy vulnerabilities of machine unlearning techniques and benchmark privacy leakage across a wide range of victim data, state-of-the-art unlearning privacy attacks, unlearning methods, and model architectures. We systematically evaluate and identify critical factors related to unlearning-induced privacy leakage. With our novel insights, we aim to provide a standardized tool for practitioners seeking to deploy customized unlearning applications with faithful privacy assessments.
Towards Unveiling Predictive Uncertainty Vulnerabilities in the Context of the Right to Be Forgotten
Aug 10, 2025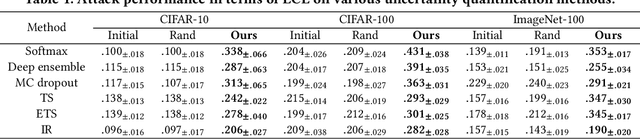
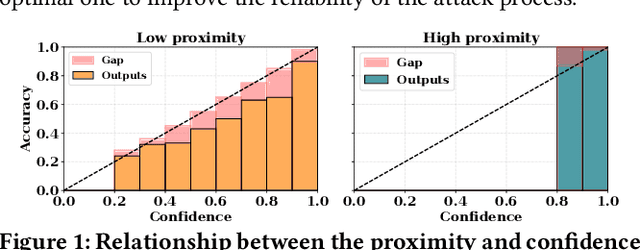
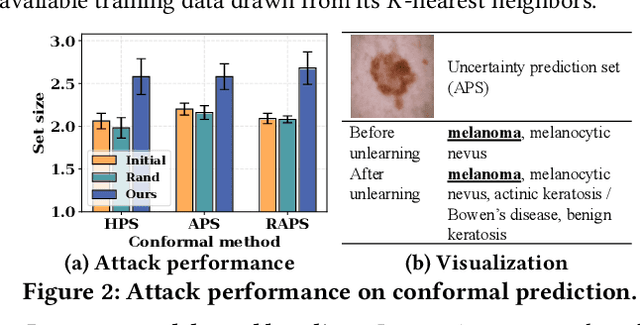
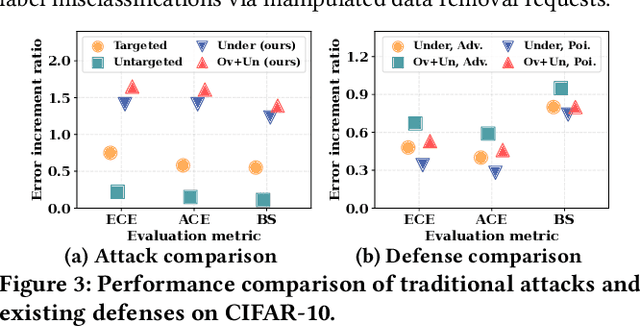
Currently, various uncertainty quantification methods have been proposed to provide certainty and probability estimates for deep learning models' label predictions. Meanwhile, with the growing demand for the right to be forgotten, machine unlearning has been extensively studied as a means to remove the impact of requested sensitive data from a pre-trained model without retraining the model from scratch. However, the vulnerabilities of such generated predictive uncertainties with regard to dedicated malicious unlearning attacks remain unexplored. To bridge this gap, for the first time, we propose a new class of malicious unlearning attacks against predictive uncertainties, where the adversary aims to cause the desired manipulations of specific predictive uncertainty results. We also design novel optimization frameworks for our attacks and conduct extensive experiments, including black-box scenarios. Notably, our extensive experiments show that our attacks are more effective in manipulating predictive uncertainties than traditional attacks that focus on label misclassifications, and existing defenses against conventional attacks are ineffective against our attacks.
Exploring Fairness in Educational Data Mining in the Context of the Right to be Forgotten
May 29, 2024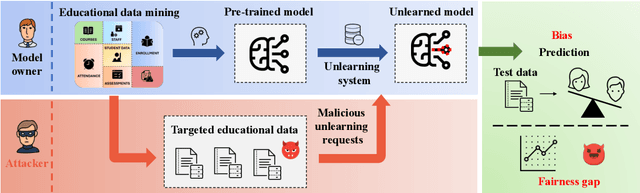



In education data mining (EDM) communities, machine learning has achieved remarkable success in discovering patterns and structures to tackle educational challenges. Notably, fairness and algorithmic bias have gained attention in learning analytics of EDM. With the increasing demand for the right to be forgotten, there is a growing need for machine learning models to forget sensitive data and its impact, particularly within the realm of EDM. The paradigm of selective forgetting, also known as machine unlearning, has been extensively studied to address this need by eliminating the influence of specific data from a pre-trained model without complete retraining. However, existing research assumes that interactive data removal operations are conducted in secure and reliable environments, neglecting potential malicious unlearning requests to undermine the fairness of machine learning systems. In this paper, we introduce a novel class of selective forgetting attacks designed to compromise the fairness of learning models while maintaining their predictive accuracy, thereby preventing the model owner from detecting the degradation in model performance. Additionally, we propose an innovative optimization framework for selective forgetting attacks, capable of generating malicious unlearning requests across various attack scenarios. We validate the effectiveness of our proposed selective forgetting attacks on fairness through extensive experiments using diverse EDM datasets.
Towards Modeling Uncertainties of Self-explaining Neural Networks via Conformal Prediction
Jan 03, 2024



Despite the recent progress in deep neural networks (DNNs), it remains challenging to explain the predictions made by DNNs. Existing explanation methods for DNNs mainly focus on post-hoc explanations where another explanatory model is employed to provide explanations. The fact that post-hoc methods can fail to reveal the actual original reasoning process of DNNs raises the need to build DNNs with built-in interpretability. Motivated by this, many self-explaining neural networks have been proposed to generate not only accurate predictions but also clear and intuitive insights into why a particular decision was made. However, existing self-explaining networks are limited in providing distribution-free uncertainty quantification for the two simultaneously generated prediction outcomes (i.e., a sample's final prediction and its corresponding explanations for interpreting that prediction). Importantly, they also fail to establish a connection between the confidence values assigned to the generated explanations in the interpretation layer and those allocated to the final predictions in the ultimate prediction layer. To tackle the aforementioned challenges, in this paper, we design a novel uncertainty modeling framework for self-explaining networks, which not only demonstrates strong distribution-free uncertainty modeling performance for the generated explanations in the interpretation layer but also excels in producing efficient and effective prediction sets for the final predictions based on the informative high-level basis explanations. We perform the theoretical analysis for the proposed framework. Extensive experimental evaluation demonstrates the effectiveness of the proposed uncertainty framework.