 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeThe Llama 4 Herd: Architecture, Training, Evaluation, and Deployment Notes
Jan 15, 2026This document consolidates publicly reported technical details about Metas Llama 4 model family. It summarizes (i) released variants (Scout and Maverick) and the broader herd context including the previewed Behemoth teacher model, (ii) architectural characteristics beyond a high-level MoE description covering routed/shared-expert structure, early-fusion multimodality, and long-context design elements reported for Scout (iRoPE and length generalization strategies), (iii) training disclosures spanning pre-training, mid-training for long-context extension, and post-training methodology (lightweight SFT, online RL, and lightweight DPO) as described in release materials, (iv) developer-reported benchmark results for both base and instruction-tuned checkpoints, and (v) practical deployment constraints observed across major serving environments, including provider-specific context limits and quantization packaging. The manuscript also summarizes licensing obligations relevant to redistribution and derivative naming, and reviews publicly described safeguards and evaluation practices. The goal is to provide a compact technical reference for researchers and practitioners who need precise, source-backed facts about Llama 4.
Asymmetrical Reciprocity-based Federated Learning for Resolving Disparities in Medical Diagnosis
Dec 27, 2024



Geographic health disparities pose a pressing global challenge, particularly in underserved regions of low- and middle-income nations. Addressing this issue requires a collaborative approach to enhance healthcare quality, leveraging support from medically more developed areas. Federated learning emerges as a promising tool for this purpose. However, the scarcity of medical data and limited computation resources in underserved regions make collaborative training of powerful machine learning models challenging. Furthermore, there exists an asymmetrical reciprocity between underserved and developed regions. To overcome these challenges, we propose a novel cross-silo federated learning framework, named FedHelp, aimed at alleviating geographic health disparities and fortifying the diagnostic capabilities of underserved regions. Specifically, FedHelp leverages foundational model knowledge via one-time API access to guide the learning process of underserved small clients, addressing the challenge of insufficient data. Additionally, we introduce a novel asymmetric dual knowledge distillation module to manage the issue of asymmetric reciprocity, facilitating the exchange of necessary knowledge between developed large clients and underserved small clients. We validate the effectiveness and utility of FedHelp through extensive experiments on both medical image classification and segmentation tasks. The experimental results demonstrate significant performance improvement compared to state-of-the-art baselines, particularly benefiting clients in underserved regions.
DreamClear: High-Capacity Real-World Image Restoration with Privacy-Safe Dataset Curation
Oct 24, 2024



Image restoration (IR) in real-world scenarios presents significant challenges due to the lack of high-capacity models and comprehensive datasets. To tackle these issues, we present a dual strategy: GenIR, an innovative data curation pipeline, and DreamClear, a cutting-edge Diffusion Transformer (DiT)-based image restoration model. GenIR, our pioneering contribution, is a dual-prompt learning pipeline that overcomes the limitations of existing datasets, which typically comprise only a few thousand images and thus offer limited generalizability for larger models. GenIR streamlines the process into three stages: image-text pair construction, dual-prompt based fine-tuning, and data generation & filtering. This approach circumvents the laborious data crawling process, ensuring copyright compliance and providing a cost-effective, privacy-safe solution for IR dataset construction. The result is a large-scale dataset of one million high-quality images. Our second contribution, DreamClear, is a DiT-based image restoration model. It utilizes the generative priors of text-to-image (T2I) diffusion models and the robust perceptual capabilities of multi-modal large language models (MLLMs) to achieve photorealistic restoration. To boost the model's adaptability to diverse real-world degradations, we introduce the Mixture of Adaptive Modulator (MoAM). It employs token-wise degradation priors to dynamically integrate various restoration experts, thereby expanding the range of degradations the model can address. Our exhaustive experiments confirm DreamClear's superior performance, underlining the efficacy of our dual strategy for real-world image restoration. Code and pre-trained models will be available at: https://github.com/shallowdream204/DreamClear.
BabelBench: An Omni Benchmark for Code-Driven Analysis of Multimodal and Multistructured Data
Oct 01, 2024



Large language models (LLMs) have become increasingly pivotal across various domains, especially in handling complex data types. This includes structured data processing, as exemplified by ChartQA and ChatGPT-Ada, and multimodal unstructured data processing as seen in Visual Question Answering (VQA). These areas have attracted significant attention from both industry and academia. Despite this, there remains a lack of unified evaluation methodologies for these diverse data handling scenarios. In response, we introduce BabelBench, an innovative benchmark framework that evaluates the proficiency of LLMs in managing multimodal multistructured data with code execution. BabelBench incorporates a dataset comprising 247 meticulously curated problems that challenge the models with tasks in perception, commonsense reasoning, logical reasoning, and so on. Besides the basic capabilities of multimodal understanding, structured data processing as well as code generation, these tasks demand advanced capabilities in exploration, planning, reasoning and debugging. Our experimental findings on BabelBench indicate that even cutting-edge models like ChatGPT 4 exhibit substantial room for improvement. The insights derived from our comprehensive analysis offer valuable guidance for future research within the community. The benchmark data can be found at https://github.com/FFD8FFE/babelbench.
Law of Vision Representation in MLLMs
Aug 29, 2024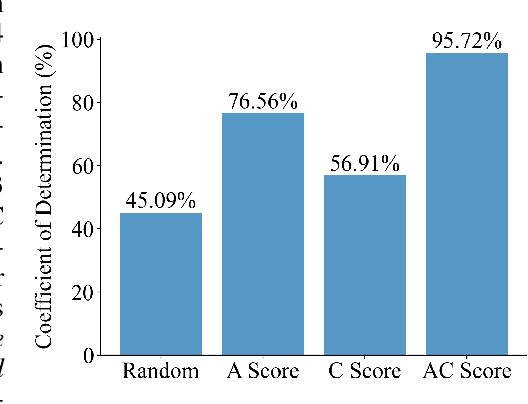
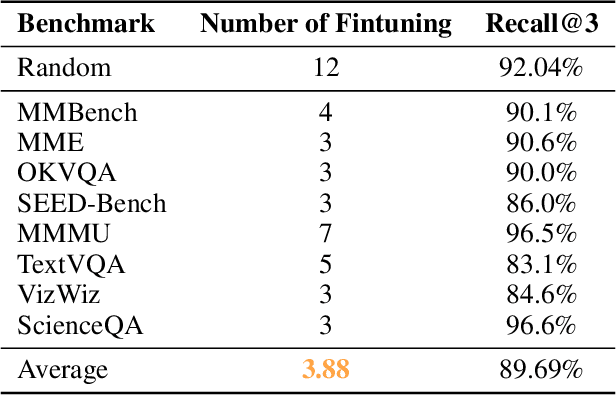
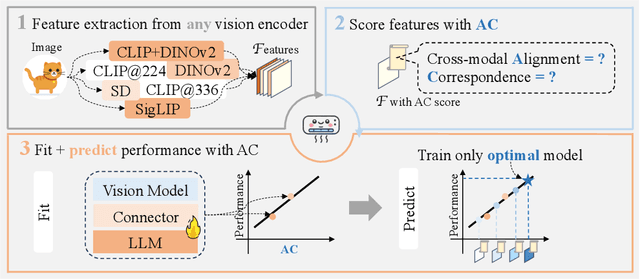

We present the "Law of Vision Representation" in multimodal large language models (MLLMs). It reveals a strong correlation between the combination of cross-modal alignment, correspondence in vision representation, and MLLM performance. We quantify the two factors using the cross-modal Alignment and Correspondence score (AC score). Through extensive experiments involving thirteen different vision representation settings and evaluations across eight benchmarks, we find that the AC score is linearly correlated to model performance. By leveraging this relationship, we are able to identify and train the optimal vision representation only, which does not require finetuning the language model every time, resulting in a 99.7% reduction in computational cost.
Visual Anchors Are Strong Information Aggregators For Multimodal Large Language Model
May 28, 2024



In the realm of Multimodal Large Language Models (MLLMs), vision-language connector plays a crucial role to link the pre-trained vision encoders with Large Language Models (LLMs). Despite its importance, the vision-language connector has been relatively less explored. In this study, we aim to propose a strong vision-language connector that enables MLLMs to achieve high accuracy while maintain low computation cost. We first reveal the existence of the visual anchors in Vision Transformer and propose a cost-effective search algorithm to extract them. Building on these findings, we introduce the Anchor Former (AcFormer), a novel vision-language connector designed to leverage the rich prior knowledge obtained from these visual anchors during pretraining, guiding the aggregation of information. Through extensive experimentation, we demonstrate that the proposed method significantly reduces computational costs by nearly two-thirds compared with baseline, while simultaneously outperforming baseline methods. This highlights the effectiveness and efficiency of AcFormer.
ViTAR: Vision Transformer with Any Resolution
Mar 28, 2024



This paper tackles a significant challenge faced by Vision Transformers (ViTs): their constrained scalability across different image resolutions. Typically, ViTs experience a performance decline when processing resolutions different from those seen during training. Our work introduces two key innovations to address this issue. Firstly, we propose a novel module for dynamic resolution adjustment, designed with a single Transformer block, specifically to achieve highly efficient incremental token integration. Secondly, we introduce fuzzy positional encoding in the Vision Transformer to provide consistent positional awareness across multiple resolutions, thereby preventing overfitting to any single training resolution. Our resulting model, ViTAR (Vision Transformer with Any Resolution), demonstrates impressive adaptability, achieving 83.3\% top-1 accuracy at a 1120x1120 resolution and 80.4\% accuracy at a 4032x4032 resolution, all while reducing computational costs. ViTAR also shows strong performance in downstream tasks such as instance and semantic segmentation and can easily combined with self-supervised learning techniques like Masked AutoEncoder. Our work provides a cost-effective solution for enhancing the resolution scalability of ViTs, paving the way for more versatile and efficient high-resolution image processing.
InfiMM-HD: A Leap Forward in High-Resolution Multimodal Understanding
Mar 03, 2024Multimodal Large Language Models (MLLMs) have experienced significant advancements recently. Nevertheless, challenges persist in the accurate recognition and comprehension of intricate details within high-resolution images. Despite being indispensable for the development of robust MLLMs, this area remains underinvestigated. To tackle this challenge, our work introduces InfiMM-HD, a novel architecture specifically designed for processing images of different resolutions with low computational overhead. This innovation facilitates the enlargement of MLLMs to higher-resolution capabilities. InfiMM-HD incorporates a cross-attention module and visual windows to reduce computation costs. By integrating this architectural design with a four-stage training pipeline, our model attains improved visual perception efficiently and cost-effectively. Empirical study underscores the robustness and effectiveness of InfiMM-HD, opening new avenues for exploration in related areas. Codes and models can be found at https://huggingface.co/Infi-MM/infimm-hd
Exploring the Reasoning Abilities of Multimodal Large Language Models (MLLMs): A Comprehensive Survey on Emerging Trends in Multimodal Reasoning
Jan 18, 2024



Strong Artificial Intelligence (Strong AI) or Artificial General Intelligence (AGI) with abstract reasoning ability is the goal of next-generation AI. Recent advancements in Large Language Models (LLMs), along with the emerging field of Multimodal Large Language Models (MLLMs), have demonstrated impressive capabilities across a wide range of multimodal tasks and applications. Particularly, various MLLMs, each with distinct model architectures, training data, and training stages, have been evaluated across a broad range of MLLM benchmarks. These studies have, to varying degrees, revealed different aspects of the current capabilities of MLLMs. However, the reasoning abilities of MLLMs have not been systematically investigated. In this survey, we comprehensively review the existing evaluation protocols of multimodal reasoning, categorize and illustrate the frontiers of MLLMs, introduce recent trends in applications of MLLMs on reasoning-intensive tasks, and finally discuss current practices and future directions. We believe our survey establishes a solid base and sheds light on this important topic, multimodal reasoning.
COCO is "ALL'' You Need for Visual Instruction Fine-tuning
Jan 17, 2024Multi-modal Large Language Models (MLLMs) are increasingly prominent in the field of artificial intelligence. Visual instruction fine-tuning (IFT) is a vital process for aligning MLLMs' output with user's intentions. High-quality and diversified instruction following data is the key to this fine-tuning process. Recent studies propose to construct visual IFT datasets through a multifaceted approach: transforming existing datasets with rule-based templates, employing GPT-4 for rewriting annotations, and utilizing GPT-4V for visual dataset pseudo-labeling. LLaVA-1.5 adopted similar approach and construct LLaVA-mix-665k, which is one of the simplest, most widely used, yet most effective IFT datasets today. Notably, when properly fine-tuned with this dataset, MLLMs can achieve state-of-the-art performance on several benchmarks. However, we noticed that models trained with this dataset often struggle to follow user instructions properly in multi-round dialog. In addition, tradition caption and VQA evaluation benchmarks, with their closed-form evaluation structure, are not fully equipped to assess the capabilities of modern open-ended generative MLLMs. This problem is not unique to the LLaVA-mix-665k dataset, but may be a potential issue in all IFT datasets constructed from image captioning or VQA sources, though the extent of this issue may vary. We argue that datasets with diverse and high-quality detailed instruction following annotations are essential and adequate for MLLMs IFT. In this work, we establish a new IFT dataset, with images sourced from the COCO dataset along with more diverse instructions. Our experiments show that when fine-tuned with out proposed dataset, MLLMs achieve better performance on open-ended evaluation benchmarks in both single-round and multi-round dialog setting.