 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDecoupling Skeleton and Flesh: Efficient Multimodal Table Reasoning with Disentangled Alignment and Structure-aware Guidance
Feb 03, 2026Reasoning over table images remains challenging for Large Vision-Language Models (LVLMs) due to complex layouts and tightly coupled structure-content information. Existing solutions often depend on expensive supervised training, reinforcement learning, or external tools, limiting efficiency and scalability. This work addresses a key question: how to adapt LVLMs to table reasoning with minimal annotation and no external tools? Specifically, we first introduce DiSCo, a Disentangled Structure-Content alignment framework that explicitly separates structural abstraction from semantic grounding during multimodal alignment, efficiently adapting LVLMs to tables structures. Building on DiSCo, we further present Table-GLS, a Global-to-Local Structure-guided reasoning framework that performs table reasoning via structured exploration and evidence-grounded inference. Extensive experiments across diverse benchmarks demonstrate that our framework efficiently enhances LVLM's table understanding and reasoning capabilities, particularly generalizing to unseen table structures.
TT-DF: A Large-Scale Diffusion-Based Dataset and Benchmark for Human Body Forgery Detection
May 13, 2025The emergence and popularity of facial deepfake methods spur the vigorous development of deepfake datasets and facial forgery detection, which to some extent alleviates the security concerns about facial-related artificial intelligence technologies. However, when it comes to human body forgery, there has been a persistent lack of datasets and detection methods, due to the later inception and complexity of human body generation methods. To mitigate this issue, we introduce TikTok-DeepFake (TT-DF), a novel large-scale diffusion-based dataset containing 6,120 forged videos with 1,378,857 synthetic frames, specifically tailored for body forgery detection. TT-DF offers a wide variety of forgery methods, involving multiple advanced human image animation models utilized for manipulation, two generative configurations based on the disentanglement of identity and pose information, as well as different compressed versions. The aim is to simulate any potential unseen forged data in the wild as comprehensively as possible, and we also furnish a benchmark on TT-DF. Additionally, we propose an adapted body forgery detection model, Temporal Optical Flow Network (TOF-Net), which exploits the spatiotemporal inconsistencies and optical flow distribution differences between natural data and forged data. Our experiments demonstrate that TOF-Net achieves favorable performance on TT-DF, outperforming current state-of-the-art extendable facial forgery detection models. For our TT-DF dataset, please refer to https://github.com/HashTAG00002/TT-DF.
DreamClear: High-Capacity Real-World Image Restoration with Privacy-Safe Dataset Curation
Oct 24, 2024



Image restoration (IR) in real-world scenarios presents significant challenges due to the lack of high-capacity models and comprehensive datasets. To tackle these issues, we present a dual strategy: GenIR, an innovative data curation pipeline, and DreamClear, a cutting-edge Diffusion Transformer (DiT)-based image restoration model. GenIR, our pioneering contribution, is a dual-prompt learning pipeline that overcomes the limitations of existing datasets, which typically comprise only a few thousand images and thus offer limited generalizability for larger models. GenIR streamlines the process into three stages: image-text pair construction, dual-prompt based fine-tuning, and data generation & filtering. This approach circumvents the laborious data crawling process, ensuring copyright compliance and providing a cost-effective, privacy-safe solution for IR dataset construction. The result is a large-scale dataset of one million high-quality images. Our second contribution, DreamClear, is a DiT-based image restoration model. It utilizes the generative priors of text-to-image (T2I) diffusion models and the robust perceptual capabilities of multi-modal large language models (MLLMs) to achieve photorealistic restoration. To boost the model's adaptability to diverse real-world degradations, we introduce the Mixture of Adaptive Modulator (MoAM). It employs token-wise degradation priors to dynamically integrate various restoration experts, thereby expanding the range of degradations the model can address. Our exhaustive experiments confirm DreamClear's superior performance, underlining the efficacy of our dual strategy for real-world image restoration. Code and pre-trained models will be available at: https://github.com/shallowdream204/DreamClear.
UniAnimate: Taming Unified Video Diffusion Models for Consistent Human Image Animation
Jun 03, 2024



Recent diffusion-based human image animation techniques have demonstrated impressive success in synthesizing videos that faithfully follow a given reference identity and a sequence of desired movement poses. Despite this, there are still two limitations: i) an extra reference model is required to align the identity image with the main video branch, which significantly increases the optimization burden and model parameters; ii) the generated video is usually short in time (e.g., 24 frames), hampering practical applications. To address these shortcomings, we present a UniAnimate framework to enable efficient and long-term human video generation. First, to reduce the optimization difficulty and ensure temporal coherence, we map the reference image along with the posture guidance and noise video into a common feature space by incorporating a unified video diffusion model. Second, we propose a unified noise input that supports random noised input as well as first frame conditioned input, which enhances the ability to generate long-term video. Finally, to further efficiently handle long sequences, we explore an alternative temporal modeling architecture based on state space model to replace the original computation-consuming temporal Transformer. Extensive experimental results indicate that UniAnimate achieves superior synthesis results over existing state-of-the-art counterparts in both quantitative and qualitative evaluations. Notably, UniAnimate can even generate highly consistent one-minute videos by iteratively employing the first frame conditioning strategy. Code and models will be publicly available. Project page: https://unianimate.github.io/.
Multimodal Prompt Perceiver: Empower Adaptiveness, Generalizability and Fidelity for All-in-One Image Restoration
Dec 05, 2023Despite substantial progress, all-in-one image restoration (IR) grapples with persistent challenges in handling intricate real-world degradations. This paper introduces MPerceiver: a novel multimodal prompt learning approach that harnesses Stable Diffusion (SD) priors to enhance adaptiveness, generalizability and fidelity for all-in-one image restoration. Specifically, we develop a dual-branch module to master two types of SD prompts: textual for holistic representation and visual for multiscale detail representation. Both prompts are dynamically adjusted by degradation predictions from the CLIP image encoder, enabling adaptive responses to diverse unknown degradations. Moreover, a plug-in detail refinement module improves restoration fidelity via direct encoder-to-decoder information transformation. To assess our method, MPerceiver is trained on 9 tasks for all-in-one IR and outperforms state-of-the-art task-specific methods across most tasks. Post multitask pre-training, MPerceiver attains a generalized representation in low-level vision, exhibiting remarkable zero-shot and few-shot capabilities in unseen tasks. Extensive experiments on 16 IR tasks and 26 benchmarks underscore the superiority of MPerceiver in terms of adaptiveness, generalizability and fidelity.
Lightweight Vision Transformer with Bidirectional Interaction
Jun 01, 2023



Recent advancements in vision backbones have significantly improved their performance by simultaneously modeling images' local and global contexts. However, the bidirectional interaction between these two contexts has not been well explored and exploited, which is important in the human visual system. This paper proposes a Fully Adaptive Self-Attention (FASA) mechanism for vision transformer to model the local and global information as well as the bidirectional interaction between them in context-aware ways. Specifically, FASA employs self-modulated convolutions to adaptively extract local representation while utilizing self-attention in down-sampled space to extract global representation. Subsequently, it conducts a bidirectional adaptation process between local and global representation to model their interaction. In addition, we introduce a fine-grained downsampling strategy to enhance the down-sampled self-attention mechanism for finer-grained global perception capability. Based on FASA, we develop a family of lightweight vision backbones, Fully Adaptive Transformer (FAT) family. Extensive experiments on multiple vision tasks demonstrate that FAT achieves impressive performance. Notably, FAT accomplishes a 77.6% accuracy on ImageNet-1K using only 4.5M parameters and 0.7G FLOPs, which surpasses the most advanced ConvNets and Transformers with similar model size and computational costs. Moreover, our model exhibits faster speed on modern GPU compared to other models. Code will be available at https://github.com/qhfan/FAT.
SOSR: Source-Free Image Super-Resolution with Wavelet Augmentation Transformer
Mar 31, 2023



Real-world images taken by different cameras with different degradation kernels often result in a cross-device domain gap in image super-resolution. A prevalent attempt to this issue is unsupervised domain adaptation (UDA) that needs to access source data. Considering privacy policies or transmission restrictions of data in many practical applications, we propose a SOurce-free image Super-Resolution framework (SOSR) to address this issue, i.e., adapt a model pre-trained on labeled source data to a target domain with only unlabeled target data. SOSR leverages the source model to generate refined pseudo-labels for teacher-student learning. To better utilize the pseudo-labels, this paper proposes a novel wavelet-based augmentation method, named Wavelet Augmentation Transformer (WAT), which can be flexibly incorporated with existing networks, to implicitly produce useful augmented data. WAT learns low-frequency information of varying levels across diverse samples, which is aggregated efficiently via deformable attention. Furthermore, an uncertainty-aware self-training mechanism is proposed to improve the accuracy of pseudo-labels, with inaccurate predictions being rectified by uncertainty estimation. To acquire better SR results and avoid overfitting pseudo-labels, several regularization losses are proposed to constrain the frequency information between target LR and SR images. Experiments show that without accessing source data, SOSR achieves superior results to the state-of-the-art UDA methods.
Vision Transformer with Super Token Sampling
Nov 21, 2022Vision transformer has achieved impressive performance for many vision tasks. However, it may suffer from high redundancy in capturing local features for shallow layers. Local self-attention or early-stage convolutions are thus utilized, which sacrifice the capacity to capture long-range dependency. A challenge then arises: can we access efficient and effective global context modeling at the early stages of a neural network? To address this issue, we draw inspiration from the design of superpixels, which reduces the number of image primitives in subsequent processing, and introduce super tokens into vision transformer. Super tokens attempt to provide a semantically meaningful tessellation of visual content, thus reducing the token number in self-attention as well as preserving global modeling. Specifically, we propose a simple yet strong super token attention (STA) mechanism with three steps: the first samples super tokens from visual tokens via sparse association learning, the second performs self-attention on super tokens, and the last maps them back to the original token space. STA decomposes vanilla global attention into multiplications of a sparse association map and a low-dimensional attention, leading to high efficiency in capturing global dependencies. Based on STA, we develop a hierarchical vision transformer. Extensive experiments demonstrate its strong performance on various vision tasks. In particular, without any extra training data or label, it achieves 86.4% top-1 accuracy on ImageNet-1K with less than 100M parameters. It also achieves 53.9 box AP and 46.8 mask AP on the COCO detection task, and 51.9 mIOU on the ADE20K semantic segmentation task. Code will be released at https://github.com/hhb072/SViT.
Contrastive Attention Network with Dense Field Estimation for Face Completion
Dec 20, 2021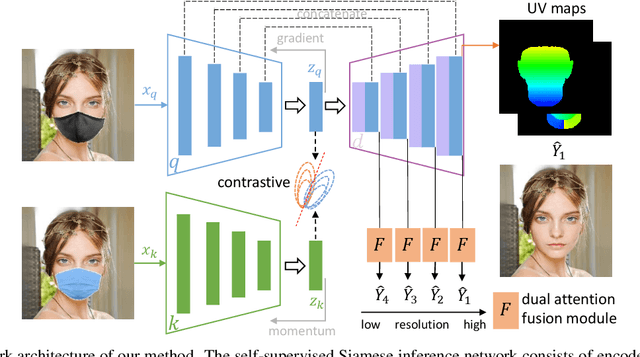
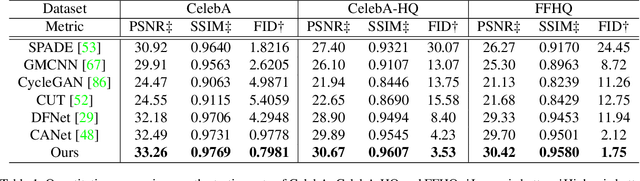
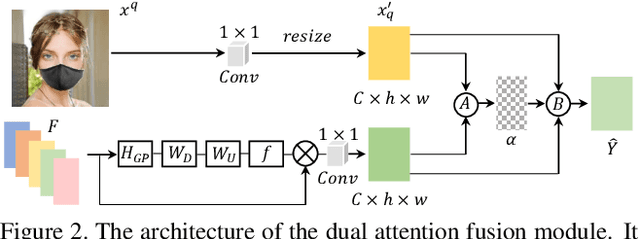

Most modern face completion approaches adopt an autoencoder or its variants to restore missing regions in face images. Encoders are often utilized to learn powerful representations that play an important role in meeting the challenges of sophisticated learning tasks. Specifically, various kinds of masks are often presented in face images in the wild, forming complex patterns, especially in this hard period of COVID-19. It's difficult for encoders to capture such powerful representations under this complex situation. To address this challenge, we propose a self-supervised Siamese inference network to improve the generalization and robustness of encoders. It can encode contextual semantics from full-resolution images and obtain more discriminative representations. To deal with geometric variations of face images, a dense correspondence field is integrated into the network. We further propose a multi-scale decoder with a novel dual attention fusion module (DAF), which can combine the restored and known regions in an adaptive manner. This multi-scale architecture is beneficial for the decoder to utilize discriminative representations learned from encoders into images. Extensive experiments clearly demonstrate that the proposed approach not only achieves more appealing results compared with state-of-the-art methods but also improves the performance of masked face recognition dramatically.
Free-Form Image Inpainting via Contrastive Attention Network
Oct 29, 2020
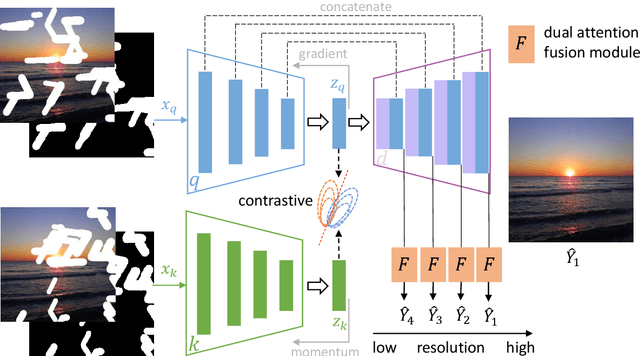
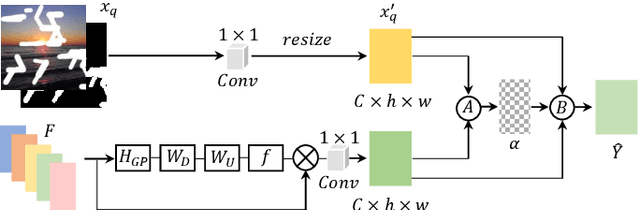

Most deep learning based image inpainting approaches adopt autoencoder or its variants to fill missing regions in images. Encoders are usually utilized to learn powerful representational spaces, which are important for dealing with sophisticated learning tasks. Specifically, in image inpainting tasks, masks with any shapes can appear anywhere in images (i.e., free-form masks) which form complex patterns. It is difficult for encoders to capture such powerful representations under this complex situation. To tackle this problem, we propose a self-supervised Siamese inference network to improve the robustness and generalization. It can encode contextual semantics from full resolution images and obtain more discriminative representations. we further propose a multi-scale decoder with a novel dual attention fusion module (DAF), which can combine both the restored and known regions in a smooth way. This multi-scale architecture is beneficial for decoding discriminative representations learned by encoders into images layer by layer. In this way, unknown regions will be filled naturally from outside to inside. Qualitative and quantitative experiments on multiple datasets, including facial and natural datasets (i.e., Celeb-HQ, Pairs Street View, Places2 and ImageNet), demonstrate that our proposed method outperforms state-of-the-art methods in generating high-quality inpainting results.