 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUniPrefill: Universal Long-Context Prefill Acceleration via Block-wise Dynamic Sparsification
May 07, 2026As large language models (LLMs) continue to advance rapidly, they are becoming increasingly capable while simultaneously demanding ever-longer context lengths. To improve the inference efficiency of long-context processing, several novel low-complexity hybrid architectures have recently been proposed, effectively alleviating the computational burden of long-context inference. However, existing research on long-context prefill acceleration remains predominantly focused on sparse attention mechanisms, which achieve their maximum speedup only on full-attention models. When transferred to emerging architectures--such as linear/full attention hybrids or sliding window/full attention hybrids--these prefill acceleration approaches suffer significant performance degradation. Furthermore, such methods are generally incompatible with continuous batching, making them difficult to integrate into modern inference engines such as vLLM. To this end, we propose UniPrefill, a prefill acceleration framework applicable to virtually any model architecture, which directly accelerates the model's computation at the token level. We further implement UniPrefill as a continuous batching operator and extend vLLM's scheduling strategy to natively support prefill-decode co-processing and tensor parallel for UniPrefill, enabling its seamless integration into vLLM. UniPrefill achieves up to 2.1x speedup in Time-To-First-Token (TTFT), with the acceleration becoming increasingly pronounced as the number of concurrent requests grows.
Advancing Vision Transformer with Enhanced Spatial Priors
Apr 20, 2026In recent years, the Vision Transformer (ViT) has garnered significant attention within the computer vision community. However, the core component of ViT, Self-Attention, lacks explicit spatial priors and suffers from quadratic computational complexity, limiting its applicability. To address these issues, we have proposed RMT, a robust vision backbone with explicit spatial priors for general purposes. RMT utilizes Manhattan distance decay to introduce spatial information and employs a horizontal and vertical decomposition attention method to model global information. Building on the strengths of RMT, Euclidean enhanced Vision Transformer (EVT) is an expanded version that incorporates several key improvements. Firstly, EVT uses a more reasonable Euclidean distance decay to enhance the modeling of spatial information, allowing for a more accurate representation of spatial relationships compared to the Manhattan distance used in RMT. Secondly, EVT abandons the decomposed attention mechanism featured in RMT and instead adopts a simpler spatially-independent grouping approach, providing the model with greater flexibility in controlling the number of tokens within each group. By addressing these modifications, EVT offers a more sophisticated and adaptable approach to incorporating spatial priors into the Self-Attention mechanism, thus overcoming some of the limitations associated with RMT and further enhancing its applicability in various computer vision tasks. Extensive experiments on Image Classification, Object Detection, Instance Segmentation, and Semantic Segmentation demonstrate that EVT exhibits exceptional performance. Without additional training data, EVT achieves 86.6% top1-acc on ImageNet-1k.
Random Wins All: Rethinking Grouping Strategies for Vision Tokens
Feb 28, 2026Since Transformers are introduced into vision architectures, their quadratic complexity has always been a significant issue that many research efforts aim to address. A representative approach involves grouping tokens, performing self-attention calculations within each group, or pooling the tokens within each group into a single token. To this end, various carefully designed grouping strategies have been proposed to enhance the performance of Vision Transformers. Here, we pose the following questions: \textbf{Are these carefully designed grouping methods truly necessary? Is there a simpler and more unified token grouping method that can replace these diverse methods?} Therefore, we propose the random grouping strategy, which involves a simple and fast random grouping strategy for vision tokens. We validate this approach on multiple baselines, and experiments show that random grouping almost outperforms all other grouping methods. When transferred to downstream tasks, such as object detection, random grouping demonstrates even more pronounced advantages. In response to this phenomenon, we conduct a detailed analysis of the advantages of random grouping from multiple perspectives and identify several crucial elements for the design of grouping strategies: positional information, head feature diversity, global receptive field, and fixed grouping pattern. We demonstrate that as long as these four conditions are met, vision tokens require only an extremely simple grouping strategy to efficiently and effectively handle various visual tasks. We also validate the effectiveness of our proposed random method across multiple modalities, including visual tasks, point cloud processing, and vision-language models. Code will be available at https://github.com/qhfan/random.
Expand and Prune: Maximizing Trajectory Diversity for Effective GRPO in Generative Models
Dec 17, 2025Group Relative Policy Optimization (GRPO) is a powerful technique for aligning generative models, but its effectiveness is bottlenecked by the conflict between large group sizes and prohibitive computational costs. In this work, we investigate the trade-off through empirical studies, yielding two key observations. First, we discover the reward clustering phenomenon in which many trajectories collapse toward the group-mean reward, offering limited optimization value. Second, we design a heuristic strategy named Optimal Variance Filtering (OVF), and verify that a high-variance subset of trajectories, selected by OVF can outperform the larger, unfiltered group. However, this static, post-sampling OVF approach still necessitates critical computational overhead, as it performs unnecessary sampling for trajectories that are ultimately discarded. To resolve this, we propose Pro-GRPO (Proactive GRPO), a novel dynamic framework that integrates latent feature-based trajectory pruning into the sampling process. Through the early termination of reward-clustered trajectories, Pro-GRPO reduces computational overhead. Leveraging its efficiency, Pro-GRPO employs an "Expand-and-Prune" strategy. This strategy first expands the size of initial sampling group to maximize trajectory diversity, then it applies multi-step OVF to the latents, avoiding prohibitive computational costs. Extensive experiments on both diffusion-based and flow-based models demonstrate the generality and effectiveness of our Pro-GRPO framework.
Breaking Complexity Barriers: High-Resolution Image Restoration with Rank Enhanced Linear Attention
May 22, 2025Transformer-based models have made remarkable progress in image restoration (IR) tasks. However, the quadratic complexity of self-attention in Transformer hinders its applicability to high-resolution images. Existing methods mitigate this issue with sparse or window-based attention, yet inherently limit global context modeling. Linear attention, a variant of softmax attention, demonstrates promise in global context modeling while maintaining linear complexity, offering a potential solution to the above challenge. Despite its efficiency benefits, vanilla linear attention suffers from a significant performance drop in IR, largely due to the low-rank nature of its attention map. To counter this, we propose Rank Enhanced Linear Attention (RELA), a simple yet effective method that enriches feature representations by integrating a lightweight depthwise convolution. Building upon RELA, we propose an efficient and effective image restoration Transformer, named LAformer. LAformer achieves effective global perception by integrating linear attention and channel attention, while also enhancing local fitting capabilities through a convolutional gated feed-forward network. Notably, LAformer eliminates hardware-inefficient operations such as softmax and window shifting, enabling efficient processing of high-resolution images. Extensive experiments across 7 IR tasks and 21 benchmarks demonstrate that LAformer outperforms SOTA methods and offers significant computational advantages.
DiCo: Revitalizing ConvNets for Scalable and Efficient Diffusion Modeling
May 16, 2025Diffusion Transformer (DiT), a promising diffusion model for visual generation, demonstrates impressive performance but incurs significant computational overhead. Intriguingly, analysis of pre-trained DiT models reveals that global self-attention is often redundant, predominantly capturing local patterns-highlighting the potential for more efficient alternatives. In this paper, we revisit convolution as an alternative building block for constructing efficient and expressive diffusion models. However, naively replacing self-attention with convolution typically results in degraded performance. Our investigations attribute this performance gap to the higher channel redundancy in ConvNets compared to Transformers. To resolve this, we introduce a compact channel attention mechanism that promotes the activation of more diverse channels, thereby enhancing feature diversity. This leads to Diffusion ConvNet (DiCo), a family of diffusion models built entirely from standard ConvNet modules, offering strong generative performance with significant efficiency gains. On class-conditional ImageNet benchmarks, DiCo outperforms previous diffusion models in both image quality and generation speed. Notably, DiCo-XL achieves an FID of 2.05 at 256x256 resolution and 2.53 at 512x512, with a 2.7x and 3.1x speedup over DiT-XL/2, respectively. Furthermore, our largest model, DiCo-H, scaled to 1B parameters, reaches an FID of 1.90 on ImageNet 256x256-without any additional supervision during training. Code: https://github.com/shallowdream204/DiCo.
Breaking the Low-Rank Dilemma of Linear Attention
Nov 14, 2024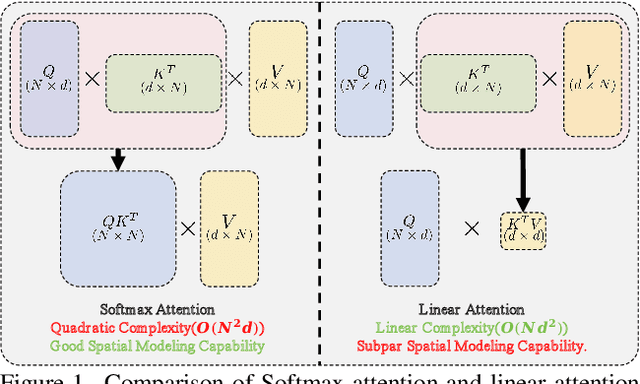

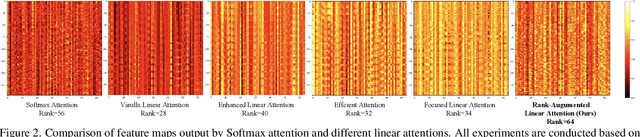

The Softmax attention mechanism in Transformer models is notoriously computationally expensive, particularly due to its quadratic complexity, posing significant challenges in vision applications. In contrast, linear attention provides a far more efficient solution by reducing the complexity to linear levels. However, compared to Softmax attention, linear attention often experiences significant performance degradation. Our experiments indicate that this performance drop is due to the low-rank nature of linear attention's feature map, which hinders its ability to adequately model complex spatial information. In this paper, to break the low-rank dilemma of linear attention, we conduct rank analysis from two perspectives: the KV buffer and the output features. Consequently, we introduce Rank-Augmented Linear Attention (RALA), which rivals the performance of Softmax attention while maintaining linear complexity and high efficiency. Based on RALA, we construct the Rank-Augmented Vision Linear Transformer (RAVLT). Extensive experiments demonstrate that RAVLT achieves excellent performance across various vision tasks. Specifically, without using any additional labels, data, or supervision during training, RAVLT achieves an 84.4% Top-1 accuracy on ImageNet-1k with only 26M parameters and 4.6G FLOPs. This result significantly surpasses previous linear attention mechanisms, fully illustrating the potential of RALA. Code will be available at https://github.com/qhfan/RALA.
Vision Transformer with Sparse Scan Prior
May 22, 2024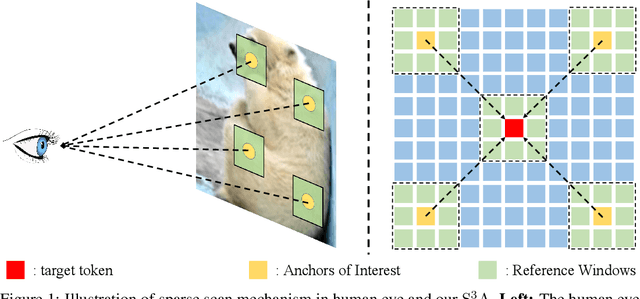
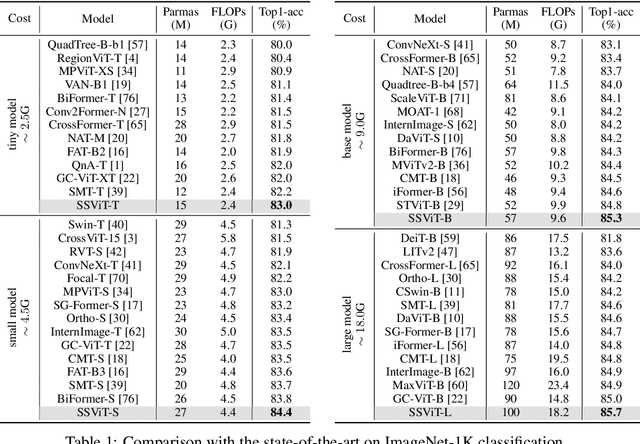
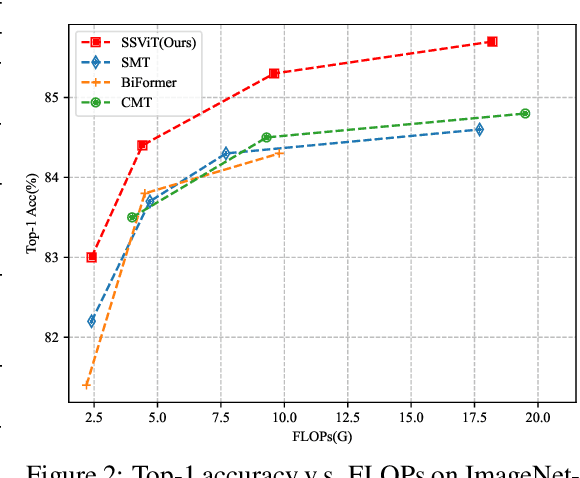

In recent years, Transformers have achieved remarkable progress in computer vision tasks. However, their global modeling often comes with substantial computational overhead, in stark contrast to the human eye's efficient information processing. Inspired by the human eye's sparse scanning mechanism, we propose a \textbf{S}parse \textbf{S}can \textbf{S}elf-\textbf{A}ttention mechanism ($\rm{S}^3\rm{A}$). This mechanism predefines a series of Anchors of Interest for each token and employs local attention to efficiently model the spatial information around these anchors, avoiding redundant global modeling and excessive focus on local information. This approach mirrors the human eye's functionality and significantly reduces the computational load of vision models. Building on $\rm{S}^3\rm{A}$, we introduce the \textbf{S}parse \textbf{S}can \textbf{Vi}sion \textbf{T}ransformer (SSViT). Extensive experiments demonstrate the outstanding performance of SSViT across a variety of tasks. Specifically, on ImageNet classification, without additional supervision or training data, SSViT achieves top-1 accuracies of \textbf{84.4\%/85.7\%} with \textbf{4.4G/18.2G} FLOPs. SSViT also excels in downstream tasks such as object detection, instance segmentation, and semantic segmentation. Its robustness is further validated across diverse datasets. Code will be available at \url{https://github.com/qhfan/SSViT}.
Semantic Equitable Clustering: A Simple, Fast and Effective Strategy for Vision Transformer
May 22, 2024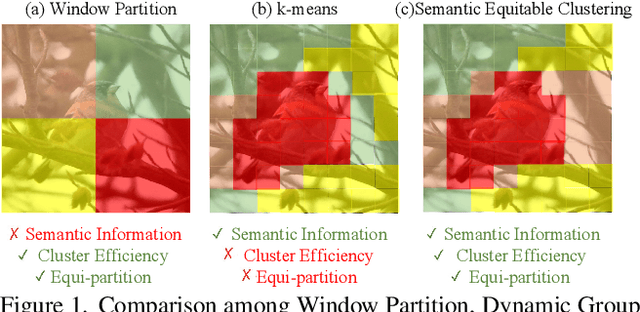
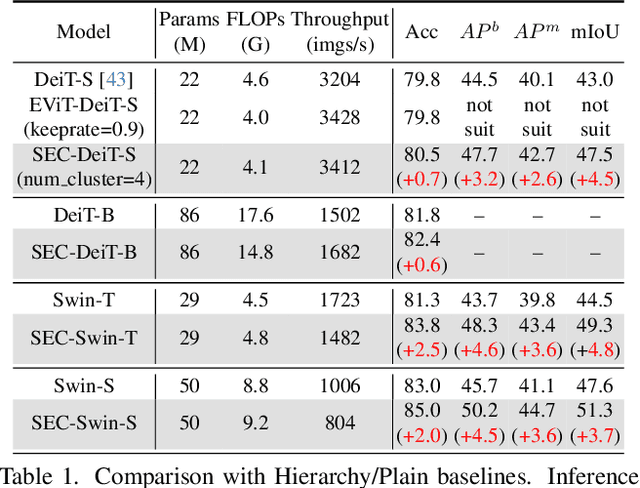
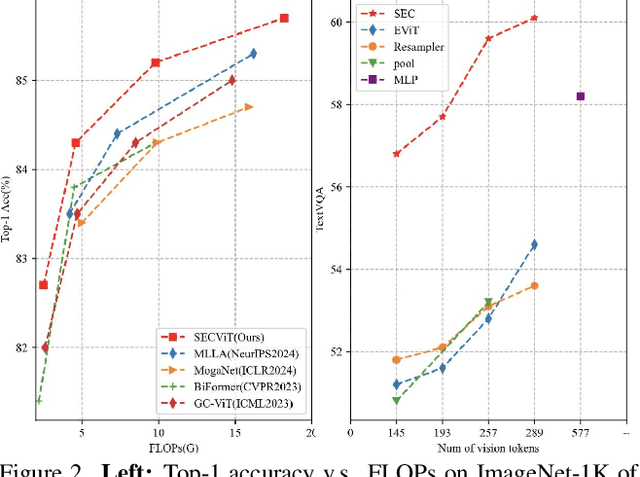
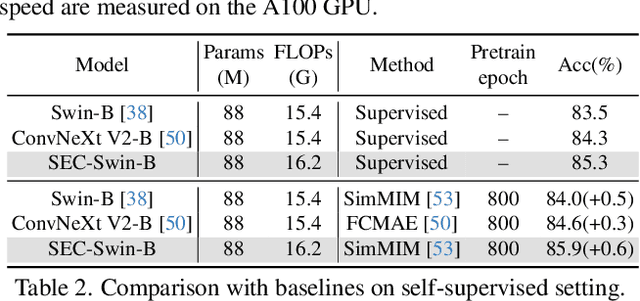
The Vision Transformer (ViT) has gained prominence for its superior relational modeling prowess. However, its global attention mechanism's quadratic complexity poses substantial computational burdens. A common remedy spatially groups tokens for self-attention, reducing computational requirements. Nonetheless, this strategy neglects semantic information in tokens, possibly scattering semantically-linked tokens across distinct groups, thus compromising the efficacy of self-attention intended for modeling inter-token dependencies. Motivated by these insights, we introduce a fast and balanced clustering method, named \textbf{S}emantic \textbf{E}quitable \textbf{C}lustering (SEC). SEC clusters tokens based on their global semantic relevance in an efficient, straightforward manner. In contrast to traditional clustering methods requiring multiple iterations, our method achieves token clustering in a single pass. Additionally, SEC regulates the number of tokens per cluster, ensuring a balanced distribution for effective parallel processing on current computational platforms without necessitating further optimization. Capitalizing on SEC, we propose a versatile vision backbone, SecViT. Comprehensive experiments in image classification, object detection, instance segmentation, and semantic segmentation validate to the effectiveness of SecViT. Remarkably, SecViT attains an impressive \textbf{84.2\%} image classification accuracy with only \textbf{27M} parameters and \textbf{4.4G} FLOPs, without the need for for additional supervision or data. Code will be available at \url{https://github.com/qhfan/SecViT}.
Band-Attention Modulated RetNet for Face Forgery Detection
Apr 09, 2024



The transformer networks are extensively utilized in face forgery detection due to their scalability across large datasets.Despite their success, transformers face challenges in balancing the capture of global context, which is crucial for unveiling forgery clues, with computational complexity.To mitigate this issue, we introduce Band-Attention modulated RetNet (BAR-Net), a lightweight network designed to efficiently process extensive visual contexts while avoiding catastrophic forgetting.Our approach empowers the target token to perceive global information by assigning differential attention levels to tokens at varying distances. We implement self-attention along both spatial axes, thereby maintaining spatial priors and easing the computational burden.Moreover, we present the adaptive frequency Band-Attention Modulation mechanism, which treats the entire Discrete Cosine Transform spectrogram as a series of frequency bands with learnable weights.Together, BAR-Net achieves favorable performance on several face forgery datasets, outperforming current state-of-the-art methods.