 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSemantic Equitable Clustering: A Simple, Fast and Effective Strategy for Vision Transformer
Paper and Code
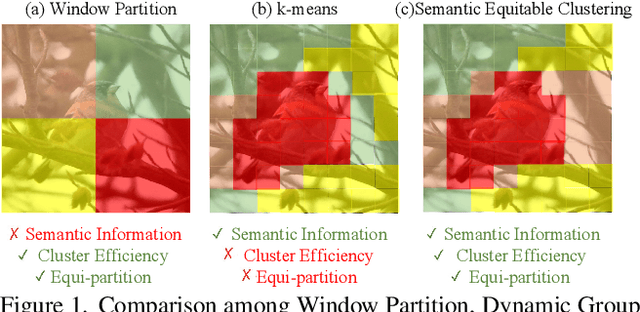
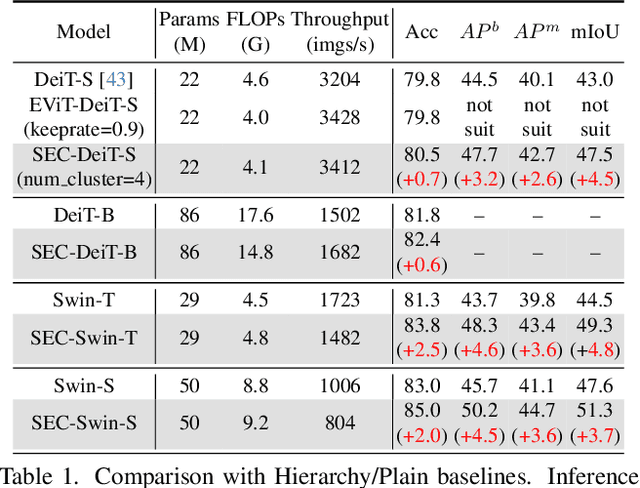
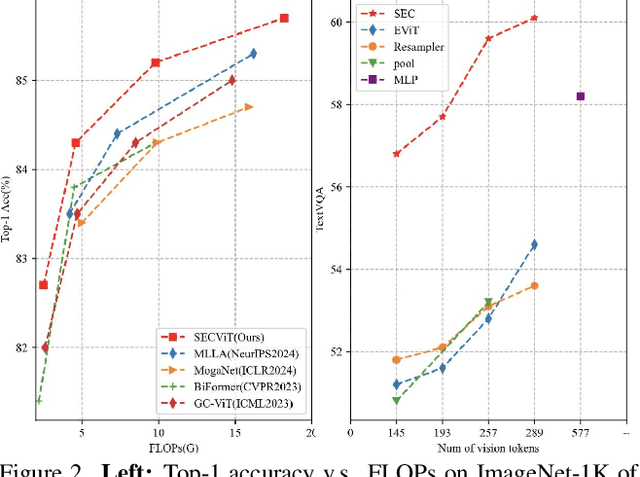
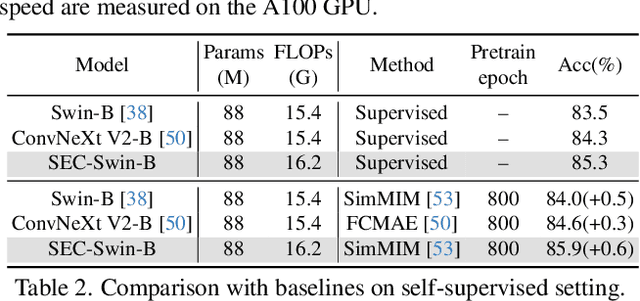
The Vision Transformer (ViT) has gained prominence for its superior relational modeling prowess. However, its global attention mechanism's quadratic complexity poses substantial computational burdens. A common remedy spatially groups tokens for self-attention, reducing computational requirements. Nonetheless, this strategy neglects semantic information in tokens, possibly scattering semantically-linked tokens across distinct groups, thus compromising the efficacy of self-attention intended for modeling inter-token dependencies. Motivated by these insights, we introduce a fast and balanced clustering method, named \textbf{S}emantic \textbf{E}quitable \textbf{C}lustering (SEC). SEC clusters tokens based on their global semantic relevance in an efficient, straightforward manner. In contrast to traditional clustering methods requiring multiple iterations, our method achieves token clustering in a single pass. Additionally, SEC regulates the number of tokens per cluster, ensuring a balanced distribution for effective parallel processing on current computational platforms without necessitating further optimization. Capitalizing on SEC, we propose a versatile vision backbone, SecViT. Comprehensive experiments in image classification, object detection, instance segmentation, and semantic segmentation validate to the effectiveness of SecViT. Remarkably, SecViT attains an impressive \textbf{84.2\%} image classification accuracy with only \textbf{27M} parameters and \textbf{4.4G} FLOPs, without the need for for additional supervision or data. Code will be available at \url{https://github.com/qhfan/SecViT}.