 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeToward Polymorphic Backdoor against Semantic Communication via Intensity-Based Poisoning
Apr 25, 2026Semantic Communication (SC) backdoor attacks aim to utilize triggers to manipulate the system into producing predetermined outputs via backdoored shared knowledge. Current SC backdoors adopt monomorphic paradigms with single attack target, which suffers from limited attack diversity, efficiency, and flexibility in heterogeneous downstream scenarios. To overcome the limitations, we propose SemBugger, a polymorphic SC backdoor. By dynamically adjusting the trigger intensity, SemBugger finely-grained controls over the SC knowledge to generate diverse malicious results from the system. Specifically, SemBugger is realized through a multi-effect poisoning-training framework. It introduces graded-intensity triggers to poison training data and optimizes SC systems with hierarchical malicious loss. The trained system's knowledge dynamically adapts to trigger intensity in inputs to yield target outputs, all while preserving transmission fidelity for benign samples. Moreover, to augment SC security, we propose a provable robustness defense that resists SemBugger's homogeneous attacks through a controlled noise mechanism. It operates via strategically adding noise in SC inputs, and we formally provide a theoretical lower bound on the defense efficacy. Experiments across diverse SC models and benchmark datasets indicate that SemBugger attains high attack efficacy while maintaining the regular functionality of SC systems. Meanwhile, the designed defense effectively neutralizes SemBugger attacks.
Instance-level Visual Active Tracking with Occlusion-Aware Planning
Apr 23, 2026Visual Active Tracking (VAT) aims to control cameras to follow a target in 3D space, which is critical for applications like drone navigation and security surveillance. However, it faces two key bottlenecks in real-world deployment: confusion from visually similar distractors caused by insufficient instance-level discrimination and severe failure under occlusions due to the absence of active planning. To address these, we propose OA-VAT, a unified pipeline with three complementary modules. First, a training-free Instance-Aware Offline Prototype Initialization aggregates multi-view augmented features via DINOv3 to construct discriminative instance prototypes, mitigating distractor confusion. Second, an Online Prototype Enhancement Tracker enhances prototypes online and integrates a confidence-aware Kalman filter for stable tracking under appearance and motion changes. Third, an Occlusion-Aware Trajectory Planner, trained on our new Planning-20k dataset, uses conditional diffusion to generate obstacle-avoiding paths for occlusion recovery. Experiments demonstrate OA-VAT achieves 0.93 average SR on UnrealCV (+2.2% vs. SOTA TrackVLA), 90.8% average CAR on real-world datasets (+12.1% vs. SOTA GC-VAT), and 81.6% TSR on a DJI Tello drone. Running at 35 FPS on an RTX 3090, it delivers robust, real-time performance for practical deployment.
Training-Free Test-Time Contrastive Learning for Large Language Models
Apr 15, 2026Large language models (LLMs) demonstrate strong reasoning capabilities, but their performance often degrades under distribution shift. Existing test-time adaptation (TTA) methods rely on gradient-based updates that require white-box access and need substantial overhead, while training-free alternatives are either static or depend on external guidance. In this paper, we propose Training-Free Test-Time Contrastive Learning TF-TTCL, a training-free adaptation framework that enables a frozen LLM to improve online by distilling supervision from its own inference experiences. Specifically, TF-TTCL implements a dynamic "Explore-Reflect-Steer" loop through three core modules: 1) Semantic Query Augmentation first diversifies problem views via multi-agent role-playing to generate different reasoning trajectories; 2) Contrastive Experience Distillation then captures the semantic gap between superior and inferior trajectories, distilling them into explicit textual rules; and 3) Contextual Rule Retrieval finally activates these stored rules during inference to dynamically steer the frozen LLM toward robust reasoning patterns while avoiding observed errors. Extensive experiments on closed-ended reasoning tasks and open-ended evaluation tasks demonstrate that TF-TTCL consistently outperforms strong zero-shot baselines and representative TTA methods under online evaluation. Code is available at https://github.com/KevinSCUTer/TF-TTCL.
HandX: Scaling Bimanual Motion and Interaction Generation
Mar 30, 2026Synthesizing human motion has advanced rapidly, yet realistic hand motion and bimanual interaction remain underexplored. Whole-body models often miss the fine-grained cues that drive dexterous behavior, finger articulation, contact timing, and inter-hand coordination, and existing resources lack high-fidelity bimanual sequences that capture nuanced finger dynamics and collaboration. To fill this gap, we present HandX, a unified foundation spanning data, annotation, and evaluation. We consolidate and filter existing datasets for quality, and collect a new motion-capture dataset targeting underrepresented bimanual interactions with detailed finger dynamics. For scalable annotation, we introduce a decoupled strategy that extracts representative motion features, e.g., contact events and finger flexion, and then leverages reasoning from large language models to produce fine-grained, semantically rich descriptions aligned with these features. Building on the resulting data and annotations, we benchmark diffusion and autoregressive models with versatile conditioning modes. Experiments demonstrate high-quality dexterous motion generation, supported by our newly proposed hand-focused metrics. We further observe clear scaling trends: larger models trained on larger, higher-quality datasets produce more semantically coherent bimanual motion. Our dataset is released to support future research.
ScoutAttention: Efficient KV Cache Offloading via Layer-Ahead CPU Pre-computation for LLM Inference
Mar 28, 2026Large language models encounter critical GPU memory capacity constraints during long-context inference, where KV cache memory consumption severely limits decode batch sizes. While existing research has explored offloading KV cache to DRAM, these approaches either demand frequent GPU-CPU data transfers or impose extensive CPU computation requirements, resulting in poor GPU utilization as the system waits for I/O operations or CPU processing to complete. We propose ScoutAttention, a novel KV cache offloading framework that accelerates LLM inference through collaborative GPU-CPU attention computation. To prevent CPU computation from bottlenecking the system, ScoutAttention introduces GPU-CPU collaborative block-wise sparse attention that significantly reduces CPU load. Unlike conventional parallel computing approaches, our framework features a novel layer-ahead CPU pre-computation algorithm, enabling the CPU to initiate attention computation one layer in advance, complemented by asynchronous periodic recall mechanisms to maintain minimal CPU compute load. Experimental results demonstrate that ScoutAttention maintains accuracy within 2.4% of baseline while achieving 2.1x speedup compared to existing offloading methods.
PositionOCR: Augmenting Positional Awareness in Multi-Modal Models via Hybrid Specialist Integration
Feb 22, 2026In recent years, Multi-modal Large Language Models (MLLMs) have achieved strong performance in OCR-centric Visual Question Answering (VQA) tasks, illustrating their capability to process heterogeneous data and exhibit adaptability across varied contexts. However, these MLLMs rely on a Large Language Model (LLM) as the decoder, which is primarily designed for linguistic processing, and thus inherently lacks the positional reasoning required for precise visual tasks, such as text spotting and text grounding. Additionally, the extensive parameters of MLLMs necessitate substantial computational resources and large-scale data for effective training. Conversely, text spotting specialists achieve state-of-the-art coordinate predictions but lack semantic reasoning capabilities. This dichotomy motivates our key research question: Can we synergize the efficiency of specialists with the contextual power of LLMs to create a positionally-accurate MLLM? To overcome these challenges, we introduce PositionOCR, a parameter-efficient hybrid architecture that seamlessly integrates a text spotting model's positional strengths with an LLM's contextual reasoning. Comprising 131M trainable parameters, this framework demonstrates outstanding multi-modal processing capabilities, particularly excelling in tasks such as text grounding and text spotting, consistently surpassing traditional MLLMs.
Context Forcing: Consistent Autoregressive Video Generation with Long Context
Feb 05, 2026Recent approaches to real-time long video generation typically employ streaming tuning strategies, attempting to train a long-context student using a short-context (memoryless) teacher. In these frameworks, the student performs long rollouts but receives supervision from a teacher limited to short 5-second windows. This structural discrepancy creates a critical \textbf{student-teacher mismatch}: the teacher's inability to access long-term history prevents it from guiding the student on global temporal dependencies, effectively capping the student's context length. To resolve this, we propose \textbf{Context Forcing}, a novel framework that trains a long-context student via a long-context teacher. By ensuring the teacher is aware of the full generation history, we eliminate the supervision mismatch, enabling the robust training of models capable of long-term consistency. To make this computationally feasible for extreme durations (e.g., 2 minutes), we introduce a context management system that transforms the linearly growing context into a \textbf{Slow-Fast Memory} architecture, significantly reducing visual redundancy. Extensive results demonstrate that our method enables effective context lengths exceeding 20 seconds -- 2 to 10 times longer than state-of-the-art methods like LongLive and Infinite-RoPE. By leveraging this extended context, Context Forcing preserves superior consistency across long durations, surpassing state-of-the-art baselines on various long video evaluation metrics.
A Review of Machine Learning for Cavitation Intensity Recognition in Complex Industrial Systems
Nov 19, 2025Cavitation intensity recognition (CIR) is a critical technology for detecting and evaluating cavitation phenomena in hydraulic machinery, with significant implications for operational safety, performance optimization, and maintenance cost reduction in complex industrial systems. Despite substantial research progress, a comprehensive review that systematically traces the development trajectory and provides explicit guidance for future research is still lacking. To bridge this gap, this paper presents a thorough review and analysis of hundreds of publications on intelligent CIR across various types of mechanical equipment from 2002 to 2025, summarizing its technological evolution and offering insights for future development. The early stages are dominated by traditional machine learning approaches that relied on manually engineered features under the guidance of domain expert knowledge. The advent of deep learning has driven the development of end-to-end models capable of automatically extracting features from multi-source signals, thereby significantly improving recognition performance and robustness. Recently, physical informed diagnostic models have been proposed to embed domain knowledge into deep learning models, which can enhance interpretability and cross-condition generalization. In the future, transfer learning, multi-modal fusion, lightweight network architectures, and the deployment of industrial agents are expected to propel CIR technology into a new stage, addressing challenges in multi-source data acquisition, standardized evaluation, and industrial implementation. The paper aims to systematically outline the evolution of CIR technology and highlight the emerging trend of integrating deep learning with physical knowledge. This provides a significant reference for researchers and practitioners in the field of intelligent cavitation diagnosis in complex industrial systems.
Stealthy Dual-Trigger Backdoors: Attacking Prompt Tuning in LM-Empowered Graph Foundation Models
Oct 16, 2025The emergence of graph foundation models (GFMs), particularly those incorporating language models (LMs), has revolutionized graph learning and demonstrated remarkable performance on text-attributed graphs (TAGs). However, compared to traditional GNNs, these LM-empowered GFMs introduce unique security vulnerabilities during the unsecured prompt tuning phase that remain understudied in current research. Through empirical investigation, we reveal a significant performance degradation in traditional graph backdoor attacks when operating in attribute-inaccessible constrained TAG systems without explicit trigger node attribute optimization. To address this, we propose a novel dual-trigger backdoor attack framework that operates at both text-level and struct-level, enabling effective attacks without explicit optimization of trigger node text attributes through the strategic utilization of a pre-established text pool. Extensive experimental evaluations demonstrate that our attack maintains superior clean accuracy while achieving outstanding attack success rates, including scenarios with highly concealed single-trigger nodes. Our work highlights critical backdoor risks in web-deployed LM-empowered GFMs and contributes to the development of more robust supervision mechanisms for open-source platforms in the era of foundation models.
Hierarchical knowledge guided fault intensity diagnosis of complex industrial systems
Aug 17, 2025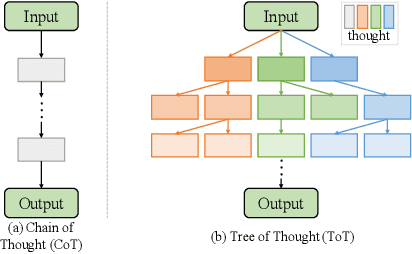
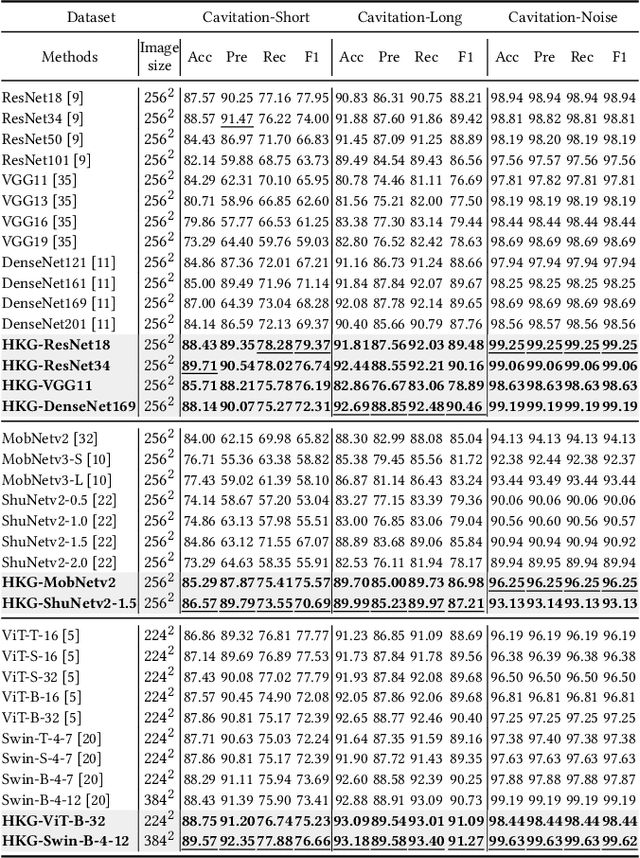
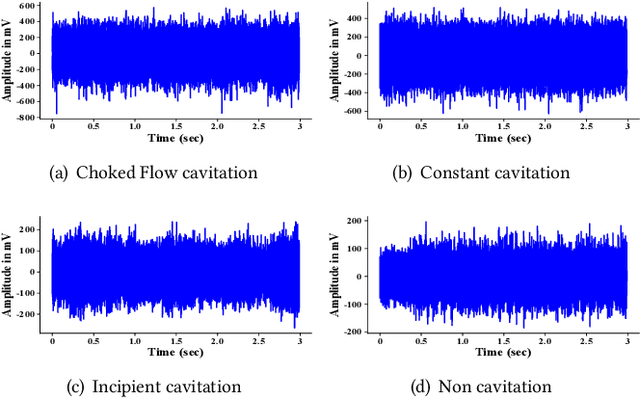
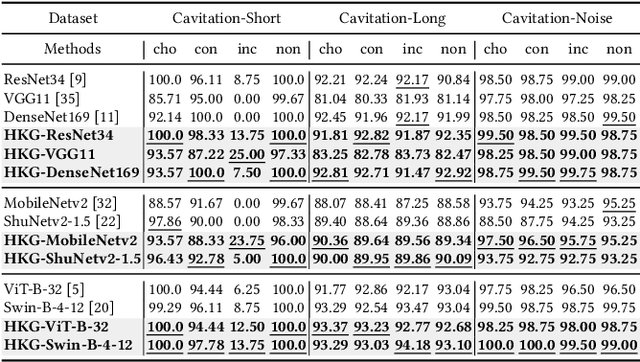
Fault intensity diagnosis (FID) plays a pivotal role in monitoring and maintaining mechanical devices within complex industrial systems. As current FID methods are based on chain of thought without considering dependencies among target classes. To capture and explore dependencies, we propose a hierarchical knowledge guided fault intensity diagnosis framework (HKG) inspired by the tree of thought, which is amenable to any representation learning methods. The HKG uses graph convolutional networks to map the hierarchical topological graph of class representations into a set of interdependent global hierarchical classifiers, where each node is denoted by word embeddings of a class. These global hierarchical classifiers are applied to learned deep features extracted by representation learning, allowing the entire model to be end-to-end learnable. In addition, we develop a re-weighted hierarchical knowledge correlation matrix (Re-HKCM) scheme by embedding inter-class hierarchical knowledge into a data-driven statistical correlation matrix (SCM) which effectively guides the information sharing of nodes in graphical convolutional neural networks and avoids over-smoothing issues. The Re-HKCM is derived from the SCM through a series of mathematical transformations. Extensive experiments are performed on four real-world datasets from different industrial domains (three cavitation datasets from SAMSON AG and one existing publicly) for FID, all showing superior results and outperform recent state-of-the-art FID methods.
* 12 pages