 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSWE-AGI: Benchmarking Specification-Driven Software Construction with MoonBit in the Era of Autonomous Agents
Feb 11, 2026Although large language models (LLMs) have demonstrated impressive coding capabilities, their ability to autonomously build production-scale software from explicit specifications remains an open question. We introduce SWE-AGI, an open-source benchmark for evaluating end-to-end, specification-driven construction of software systems written in MoonBit. SWE-AGI tasks require LLM-based agents to implement parsers, interpreters, binary decoders, and SAT solvers strictly from authoritative standards and RFCs under a fixed API scaffold. Each task involves implementing 1,000-10,000 lines of core logic, corresponding to weeks or months of engineering effort for an experienced human developer. By leveraging the nascent MoonBit ecosystem, SWE-AGI minimizes data leakage, forcing agents to rely on long-horizon architectural reasoning rather than code retrieval. Across frontier models, gpt-5.3-codex achieves the best overall performance (solving 19/22 tasks, 86.4%), outperforming claude-opus-4.6 (15/22, 68.2%), and kimi-2.5 exhibits the strongest performance among open-source models. Performance degrades sharply with increasing task difficulty, particularly on hard, specification-intensive systems. Behavioral analysis further reveals that as codebases scale, code reading, rather than writing, becomes the dominant bottleneck in AI-assisted development. Overall, while specification-driven autonomous software engineering is increasingly viable, substantial challenges remain before it can reliably support production-scale development.
Tracing the Heart's Pathways: ECG Representation Learning from a Cardiac Conduction Perspective
Dec 30, 2025The multi-lead electrocardiogram (ECG) stands as a cornerstone of cardiac diagnosis. Recent strides in electrocardiogram self-supervised learning (eSSL) have brightened prospects for enhancing representation learning without relying on high-quality annotations. Yet earlier eSSL methods suffer a key limitation: they focus on consistent patterns across leads and beats, overlooking the inherent differences in heartbeats rooted in cardiac conduction processes, while subtle but significant variations carry unique physiological signatures. Moreover, representation learning for ECG analysis should align with ECG diagnostic guidelines, which progress from individual heartbeats to single leads and ultimately to lead combinations. This sequential logic, however, is often neglected when applying pre-trained models to downstream tasks. To address these gaps, we propose CLEAR-HUG, a two-stage framework designed to capture subtle variations in cardiac conduction across leads while adhering to ECG diagnostic guidelines. In the first stage, we introduce an eSSL model termed Conduction-LEAd Reconstructor (CLEAR), which captures both specific variations and general commonalities across heartbeats. Treating each heartbeat as a distinct entity, CLEAR employs a simple yet effective sparse attention mechanism to reconstruct signals without interference from other heartbeats. In the second stage, we implement a Hierarchical lead-Unified Group head (HUG) for disease diagnosis, mirroring clinical workflow. Experimental results across six tasks show a 6.84% improvement, validating the effectiveness of CLEAR-HUG. This highlights its ability to enhance representations of cardiac conduction and align patterns with expert diagnostic guidelines.
Efficient Flow Matching using Latent Variables
May 07, 2025Flow matching models have shown great potential in image generation tasks among probabilistic generative models. Building upon the ideas of continuous normalizing flows, flow matching models generalize the transport path of the diffusion models from a simple prior distribution to the data. Most flow matching models in the literature do not explicitly model the underlying structure/manifold in the target data when learning the flow from a simple source distribution like the standard Gaussian. This leads to inefficient learning, especially for many high-dimensional real-world datasets, which often reside in a low-dimensional manifold. Existing strategies of incorporating manifolds, including data with underlying multi-modal distribution, often require expensive training and hence frequently lead to suboptimal performance. To this end, we present \texttt{Latent-CFM}, which provides simplified training/inference strategies to incorporate multi-modal data structures using pretrained deep latent variable models. Through experiments on multi-modal synthetic data and widely used image benchmark datasets, we show that \texttt{Latent-CFM} exhibits improved generation quality with significantly less training ($\sim 50\%$ less in some cases) and computation than state-of-the-art flow matching models. Using a 2d Darcy flow dataset, we demonstrate that our approach generates more physically accurate samples than competitive approaches. In addition, through latent space analysis, we demonstrate that our approach can be used for conditional image generation conditioned on latent features.
AuditVotes: A Framework Towards More Deployable Certified Robustness for Graph Neural Networks
Mar 29, 2025Despite advancements in Graph Neural Networks (GNNs), adaptive attacks continue to challenge their robustness. Certified robustness based on randomized smoothing has emerged as a promising solution, offering provable guarantees that a model's predictions remain stable under adversarial perturbations within a specified range. However, existing methods face a critical trade-off between accuracy and robustness, as achieving stronger robustness requires introducing greater noise into the input graph. This excessive randomization degrades data quality and disrupts prediction consistency, limiting the practical deployment of certifiably robust GNNs in real-world scenarios where both accuracy and robustness are essential. To address this challenge, we propose \textbf{AuditVotes}, the first framework to achieve both high clean accuracy and certifiably robust accuracy for GNNs. It integrates randomized smoothing with two key components, \underline{au}gmentation and con\underline{dit}ional smoothing, aiming to improve data quality and prediction consistency. The augmentation, acting as a pre-processing step, de-noises the randomized graph, significantly improving data quality and clean accuracy. The conditional smoothing, serving as a post-processing step, employs a filtering function to selectively count votes, thereby filtering low-quality predictions and improving voting consistency. Extensive experimental results demonstrate that AuditVotes significantly enhances clean accuracy, certified robustness, and empirical robustness while maintaining high computational efficiency. Notably, compared to baseline randomized smoothing, AuditVotes improves clean accuracy by $437.1\%$ and certified accuracy by $409.3\%$ when the attacker can arbitrarily insert $20$ edges on the Cora-ML datasets, representing a substantial step toward deploying certifiably robust GNNs in real-world applications.
Hierarchical Visual Categories Modeling: A Joint Representation Learning and Density Estimation Framework for Out-of-Distribution Detection
Aug 28, 2024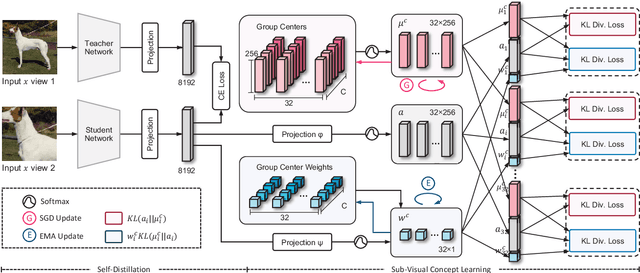
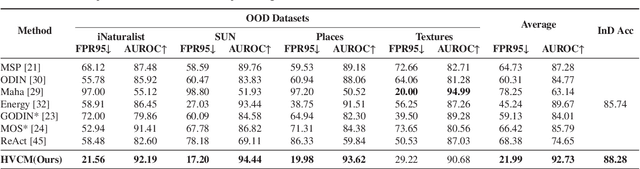
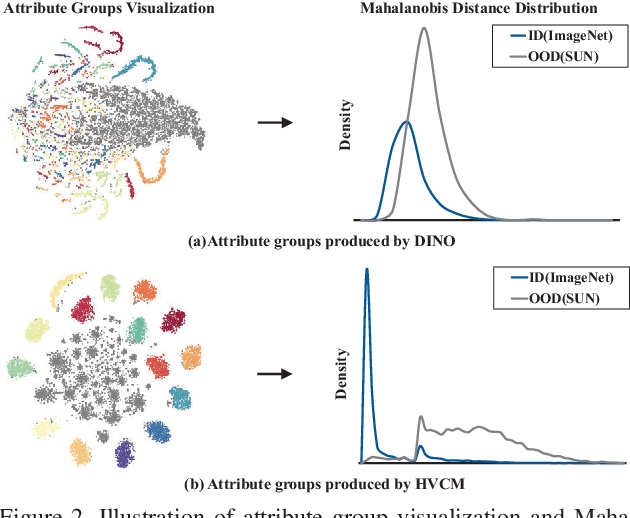
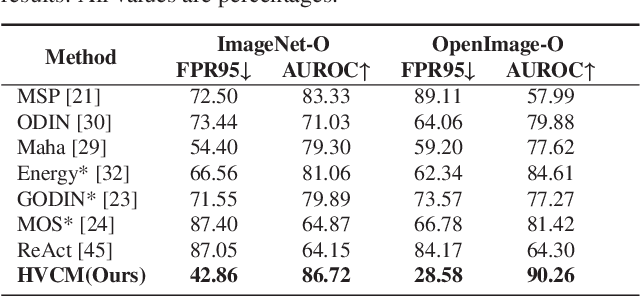
Detecting out-of-distribution inputs for visual recognition models has become critical in safe deep learning. This paper proposes a novel hierarchical visual category modeling scheme to separate out-of-distribution data from in-distribution data through joint representation learning and statistical modeling. We learn a mixture of Gaussian models for each in-distribution category. There are many Gaussian mixture models to model different visual categories. With these Gaussian models, we design an in-distribution score function by aggregating multiple Mahalanobis-based metrics. We don't use any auxiliary outlier data as training samples, which may hurt the generalization ability of out-of-distribution detection algorithms. We split the ImageNet-1k dataset into ten folds randomly. We use one fold as the in-distribution dataset and the others as out-of-distribution datasets to evaluate the proposed method. We also conduct experiments on seven popular benchmarks, including CIFAR, iNaturalist, SUN, Places, Textures, ImageNet-O, and OpenImage-O. Extensive experiments indicate that the proposed method outperforms state-of-the-art algorithms clearly. Meanwhile, we find that our visual representation has a competitive performance when compared with features learned by classical methods. These results demonstrate that the proposed method hasn't weakened the discriminative ability of visual recognition models and keeps high efficiency in detecting out-of-distribution samples.
The Merit of River Network Topology for Neural Flood Forecasting
May 30, 2024Climate change exacerbates riverine floods, which occur with higher frequency and intensity than ever. The much-needed forecasting systems typically rely on accurate river discharge predictions. To this end, the SOTA data-driven approaches treat forecasting at spatially distributed gauge stations as isolated problems, even within the same river network. However, incorporating the known topology of the river network into the prediction model has the potential to leverage the adjacency relationship between gauges. Thus, we model river discharge for a network of gauging stations with GNNs and compare the forecasting performance achieved by different adjacency definitions. Our results show that the model fails to benefit from the river network topology information, both on the entire network and small subgraphs. The learned edge weights correlate with neither of the static definitions and exhibit no regular pattern. Furthermore, the GNNs struggle to predict sudden, narrow discharge spikes. Our work hints at a more general underlying phenomenon of neural prediction not always benefitting from graphical structure and may inspire a systematic study of the conditions under which this happens.
* https://openreview.net/forum?id=QE6iC9s6vU
Quality-aware Masked Diffusion Transformer for Enhanced Music Generation
May 24, 2024



In recent years, diffusion-based text-to-music (TTM) generation has gained prominence, offering a novel approach to synthesizing musical content from textual descriptions. Achieving high accuracy and diversity in this generation process requires extensive, high-quality data, which often constitutes only a fraction of available datasets. Within open-source datasets, the prevalence of issues like mislabeling, weak labeling, unlabeled data, and low-quality music waveform significantly hampers the development of music generation models. To overcome these challenges, we introduce a novel quality-aware masked diffusion transformer (QA-MDT) approach that enables generative models to discern the quality of input music waveform during training. Building on the unique properties of musical signals, we have adapted and implemented a MDT model for TTM task, while further unveiling its distinct capacity for quality control. Moreover, we address the issue of low-quality captions with a caption refinement data processing approach. Our demo page is shown in https://qa-mdt.github.io/. Code on https://github.com/ivcylc/qa-mdt
Streamlining Ocean Dynamics Modeling with Fourier Neural Operators: A Multiobjective Hyperparameter and Architecture Optimization Approach
Apr 10, 2024



Training an effective deep learning model to learn ocean processes involves careful choices of various hyperparameters. We leverage the advanced search algorithms for multiobjective optimization in DeepHyper, a scalable hyperparameter optimization software, to streamline the development of neural networks tailored for ocean modeling. The focus is on optimizing Fourier neural operators (FNOs), a data-driven model capable of simulating complex ocean behaviors. Selecting the correct model and tuning the hyperparameters are challenging tasks, requiring much effort to ensure model accuracy. DeepHyper allows efficient exploration of hyperparameters associated with data preprocessing, FNO architecture-related hyperparameters, and various model training strategies. We aim to obtain an optimal set of hyperparameters leading to the most performant model. Moreover, on top of the commonly used mean squared error for model training, we propose adopting the negative anomaly correlation coefficient as the additional loss term to improve model performance and investigate the potential trade-off between the two terms. The experimental results show that the optimal set of hyperparameters enhanced model performance in single timestepping forecasting and greatly exceeded the baseline configuration in the autoregressive rollout for long-horizon forecasting up to 30 days. Utilizing DeepHyper, we demonstrate an approach to enhance the use of FNOs in ocean dynamics forecasting, offering a scalable solution with improved precision.
Weakly Supervised Gaussian Contrastive Grounding with Large Multimodal Models for Video Question Answering
Jan 28, 2024



Video Question Answering (VideoQA) aims to answer natural language questions based on the information observed in videos. Despite the recent success of Large Multimodal Models (LMMs) in image-language understanding and reasoning, they deal with VideoQA insufficiently by simply taking uniformly sampled frames as visual inputs, which ignores question-relevant visual clues. Moreover, there are no human annotations for question-critical timestamps in existing VideoQA datasets. In light of this, we propose a novel weakly supervised framework to enforce the LMMs to reason out the answers with question-critical moments as visual inputs. Specifically, we fuse the question and answer pairs as event descriptions to find multiple keyframes as target moments, which will be pseudo-labels. With these pseudo-labels as additionally weak supervision, we devise a lightweight Gaussian-based Contrastive Grounding (GCG) module. GCG learns multiple Gaussian functions to characterize the temporal structure of the video, and sample question-critical frames as positive moments to be the visual inputs of LMMs. Extensive experiments on several VideoQA benchmarks verify the effectiveness of our framework, and we achieve substantial improvements compared to previous state-of-the-art methods.
A Safe Reinforcement Learning Algorithm for Supervisory Control of Power Plants
Jan 23, 2024Traditional control theory-based methods require tailored engineering for each system and constant fine-tuning. In power plant control, one often needs to obtain a precise representation of the system dynamics and carefully design the control scheme accordingly. Model-free Reinforcement learning (RL) has emerged as a promising solution for control tasks due to its ability to learn from trial-and-error interactions with the environment. It eliminates the need for explicitly modeling the environment's dynamics, which is potentially inaccurate. However, the direct imposition of state constraints in power plant control raises challenges for standard RL methods. To address this, we propose a chance-constrained RL algorithm based on Proximal Policy Optimization for supervisory control. Our method employs Lagrangian relaxation to convert the constrained optimization problem into an unconstrained objective, where trainable Lagrange multipliers enforce the state constraints. Our approach achieves the smallest distance of violation and violation rate in a load-follow maneuver for an advanced Nuclear Power Plant design.