 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging Interpolation Models and Error Bounds for Verifiable Scientific Machine Learning
Apr 04, 2024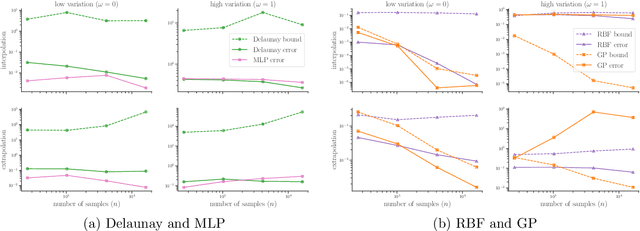

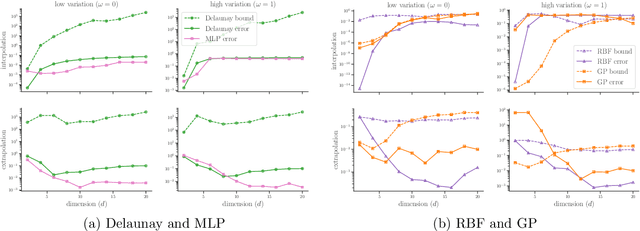
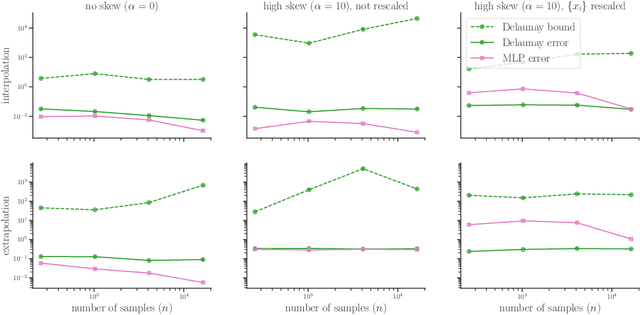
Effective verification and validation techniques for modern scientific machine learning workflows are challenging to devise. Statistical methods are abundant and easily deployed, but often rely on speculative assumptions about the data and methods involved. Error bounds for classical interpolation techniques can provide mathematically rigorous estimates of accuracy, but often are difficult or impractical to determine computationally. In this work, we present a best-of-both-worlds approach to verifiable scientific machine learning by demonstrating that (1) multiple standard interpolation techniques have informative error bounds that can be computed or estimated efficiently; (2) comparative performance among distinct interpolants can aid in validation goals; (3) deploying interpolation methods on latent spaces generated by deep learning techniques enables some interpretability for black-box models. We present a detailed case study of our approach for predicting lift-drag ratios from airfoil images. Code developed for this work is available in a public Github repository.
Parallel Multi-Objective Hyperparameter Optimization with Uniform Normalization and Bounded Objectives
Sep 26, 2023



Machine learning (ML) methods offer a wide range of configurable hyperparameters that have a significant influence on their performance. While accuracy is a commonly used performance objective, in many settings, it is not sufficient. Optimizing the ML models with respect to multiple objectives such as accuracy, confidence, fairness, calibration, privacy, latency, and memory consumption is becoming crucial. To that end, hyperparameter optimization, the approach to systematically optimize the hyperparameters, which is already challenging for a single objective, is even more challenging for multiple objectives. In addition, the differences in objective scales, the failures, and the presence of outlier values in objectives make the problem even harder. We propose a multi-objective Bayesian optimization (MoBO) algorithm that addresses these problems through uniform objective normalization and randomized weights in scalarization. We increase the efficiency of our approach by imposing constraints on the objective to avoid exploring unnecessary configurations (e.g., insufficient accuracy). Finally, we leverage an approach to parallelize the MoBO which results in a 5x speed-up when using 16x more workers.
Do Large Language Models know what humans know?
Sep 04, 2022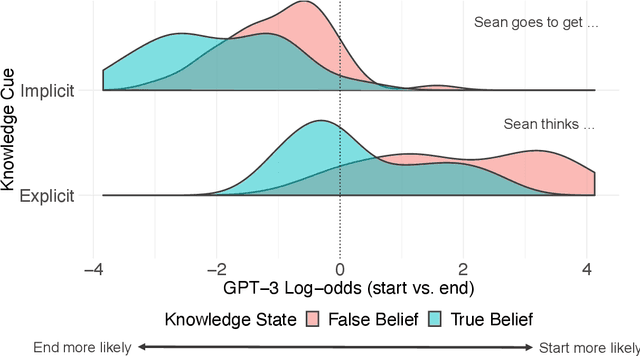
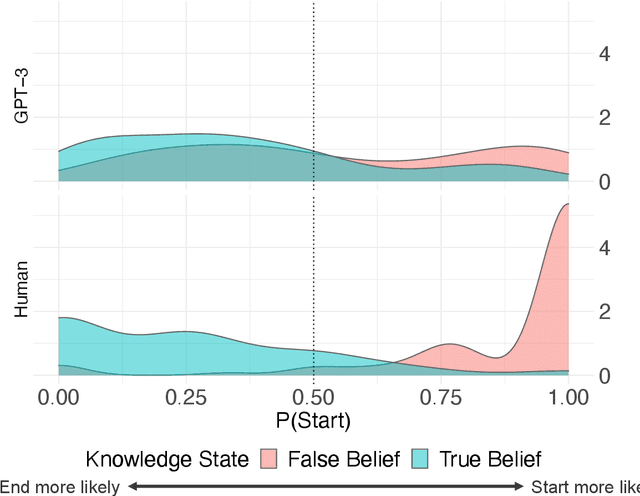
Humans can attribute mental states to others, a capacity known as Theory of Mind. However, it is unknown to what extent this ability results from an innate biological endowment or from experience accrued through child development, particularly exposure to language describing others' mental states. We test the viability of the language exposure hypothesis by assessing whether models exposed to large quantities of human language develop evidence of Theory of Mind. In a pre-registered analysis, we present a linguistic version of the False Belief Task, widely used to assess Theory of Mind, to both human participants and a state-of-the-art Large Language Model, GPT-3. Both are sensitive to others' beliefs, but the language model does not perform as well as the humans, nor does it explain the full extent of their behavior, despite being exposed to more language than a human would in a lifetime. This suggests that while language exposure may in part explain how humans develop Theory of Mind, other mechanisms are also responsible.
Co-Scale Conv-Attentional Image Transformers
Apr 13, 2021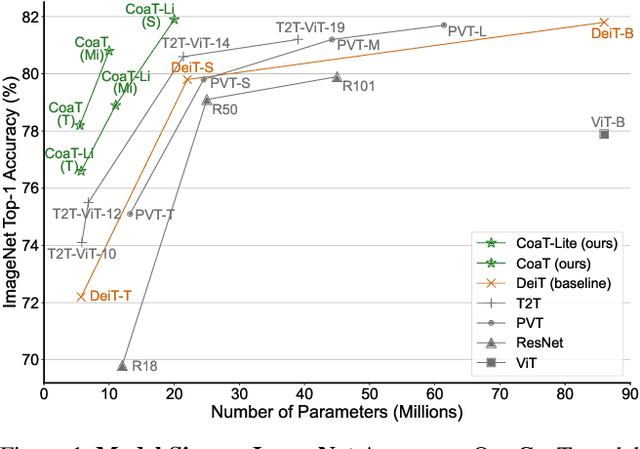

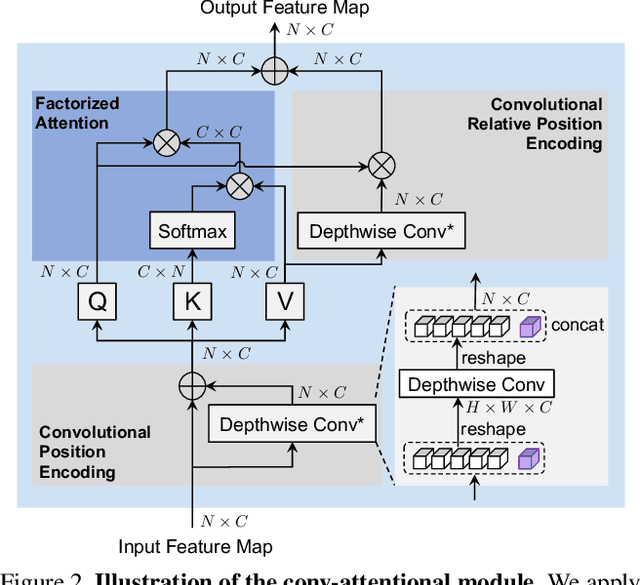
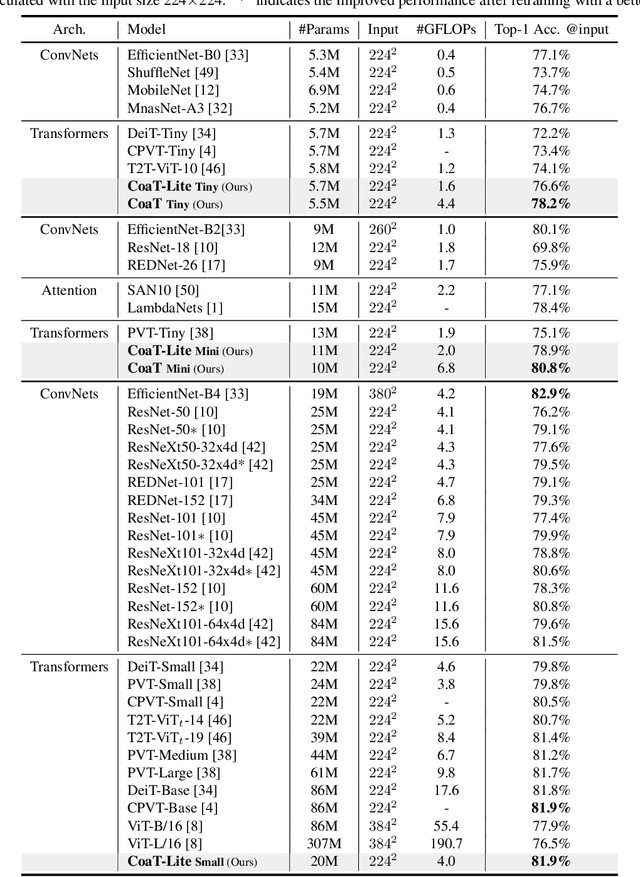
In this paper, we present Co-scale conv-attentional image Transformers (CoaT), a Transformer-based image classifier equipped with co-scale and conv-attentional mechanisms. First, the co-scale mechanism maintains the integrity of Transformers' encoder branches at individual scales, while allowing representations learned at different scales to effectively communicate with each other; we design a series of serial and parallel blocks to realize the co-scale attention mechanism. Second, we devise a conv-attentional mechanism by realizing a relative position embedding formulation in the factorized attention module with an efficient convolution-like implementation. CoaT empowers image Transformers with enriched multi-scale and contextual modeling capabilities. On ImageNet, relatively small CoaT models attain superior classification results compared with the similar-sized convolutional neural networks and image/vision Transformers. The effectiveness of CoaT's backbone is also illustrated on object detection and instance segmentation, demonstrating its applicability to the downstream computer vision tasks.