 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDoes GPT-4 Pass the Turing Test?
Oct 31, 2023We evaluated GPT-4 in a public online Turing Test. The best-performing GPT-4 prompt passed in 41% of games, outperforming baselines set by ELIZA (27%) and GPT-3.5 (14%), but falling short of chance and the baseline set by human participants (63%). Participants' decisions were based mainly on linguistic style (35%) and socio-emotional traits (27%), supporting the idea that intelligence is not sufficient to pass the Turing Test. Participants' demographics, including education and familiarity with LLMs, did not predict detection rate, suggesting that even those who understand systems deeply and interact with them frequently may be susceptible to deception. Despite known limitations as a test of intelligence, we argue that the Turing Test continues to be relevant as an assessment of naturalistic communication and deception. AI models with the ability to masquerade as humans could have widespread societal consequences, and we analyse the effectiveness of different strategies and criteria for judging humanlikeness.
Do Large Language Models know what humans know?
Sep 04, 2022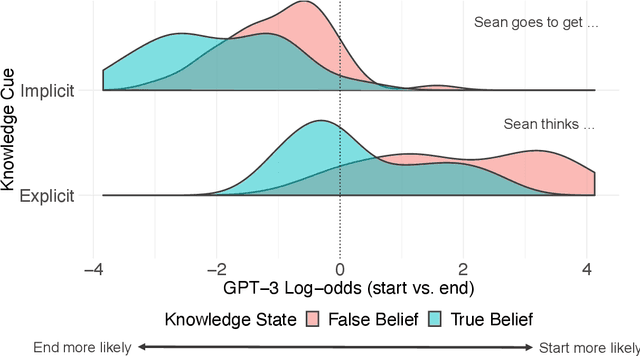
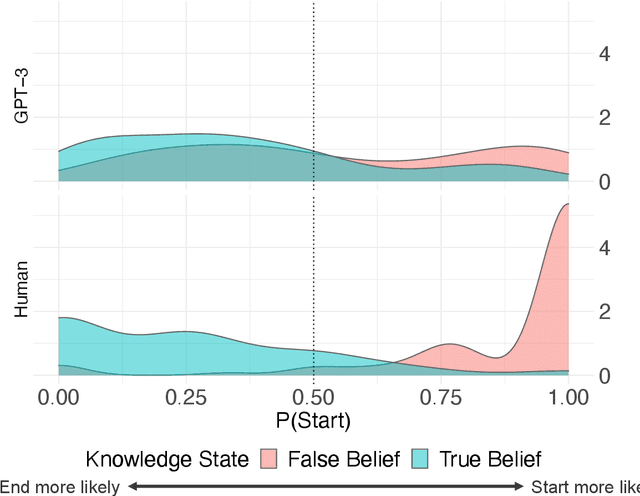
Humans can attribute mental states to others, a capacity known as Theory of Mind. However, it is unknown to what extent this ability results from an innate biological endowment or from experience accrued through child development, particularly exposure to language describing others' mental states. We test the viability of the language exposure hypothesis by assessing whether models exposed to large quantities of human language develop evidence of Theory of Mind. In a pre-registered analysis, we present a linguistic version of the False Belief Task, widely used to assess Theory of Mind, to both human participants and a state-of-the-art Large Language Model, GPT-3. Both are sensitive to others' beliefs, but the language model does not perform as well as the humans, nor does it explain the full extent of their behavior, despite being exposed to more language than a human would in a lifetime. This suggests that while language exposure may in part explain how humans develop Theory of Mind, other mechanisms are also responsible.
Contextualized Sensorimotor Norms: multi-dimensional measures of sensorimotor strength for ambiguous English words, in context
Mar 10, 2022
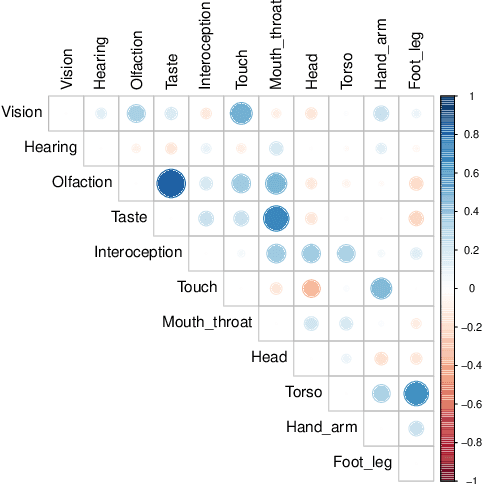
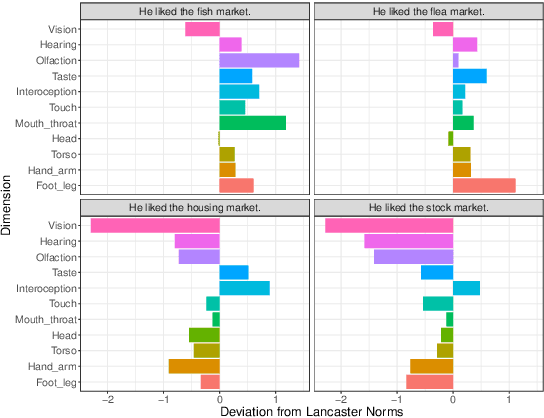
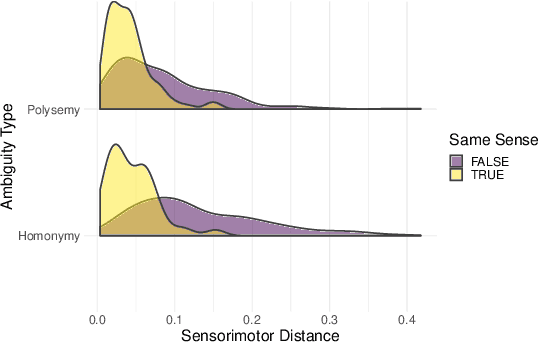
Most large language models are trained on linguistic input alone, yet humans appear to ground their understanding of words in sensorimotor experience. A natural solution is to augment LM representations with human judgments of a word's sensorimotor associations (e.g., the Lancaster Sensorimotor Norms), but this raises another challenge: most words are ambiguous, and judgments of words in isolation fail to account for this multiplicity of meaning (e.g., "wooden table" vs. "data table"). We attempted to address this problem by building a new lexical resource of contextualized sensorimotor judgments for 112 English words, each rated in four different contexts (448 sentences total). We show that these ratings encode overlapping but distinct information from the Lancaster Sensorimotor Norms, and that they also predict other measures of interest (e.g., relatedness), above and beyond measures derived from BERT. Beyond shedding light on theoretical questions, we suggest that these ratings could be of use as a "challenge set" for researchers building grounded language models.
RAW-C: Relatedness of Ambiguous Words--in Context
May 27, 2021

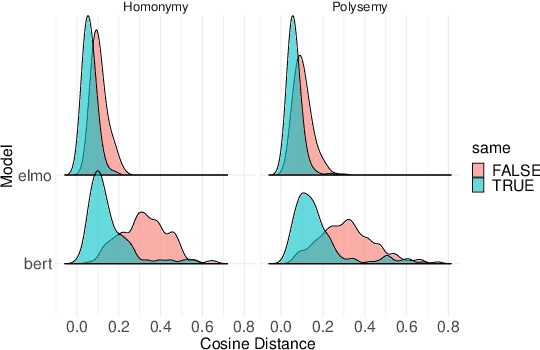
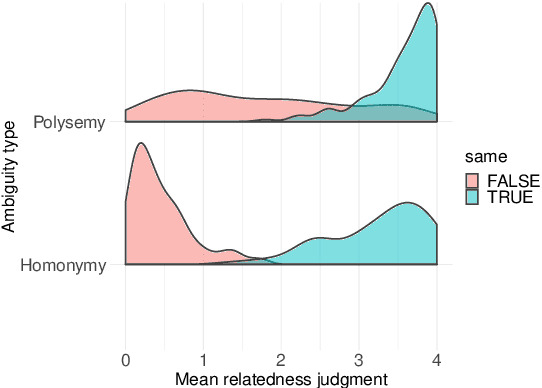
Most words are ambiguous--i.e., they convey distinct meanings in different contexts--and even the meanings of unambiguous words are context-dependent. Both phenomena present a challenge for NLP. Recently, the advent of contextualized word embeddings has led to success on tasks involving lexical ambiguity, such as Word Sense Disambiguation. However, there are few tasks that directly evaluate how well these contextualized embeddings accommodate the more continuous, dynamic nature of word meaning--particularly in a way that matches human intuitions. We introduce RAW-C, a dataset of graded, human relatedness judgments for 112 ambiguous words in context (with 672 sentence pairs total), as well as human estimates of sense dominance. The average inter-annotator agreement (assessed using a leave-one-annotator-out method) was 0.79. We then show that a measure of cosine distance, computed using contextualized embeddings from BERT and ELMo, correlates with human judgments, but that cosine distance also systematically underestimates how similar humans find uses of the same sense of a word to be, and systematically overestimates how similar humans find uses of different-sense homonyms. Finally, we propose a synthesis between psycholinguistic theories of the mental lexicon and computational models of lexical semantics.