 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContextualized Sensorimotor Norms: multi-dimensional measures of sensorimotor strength for ambiguous English words, in context
Paper and Code

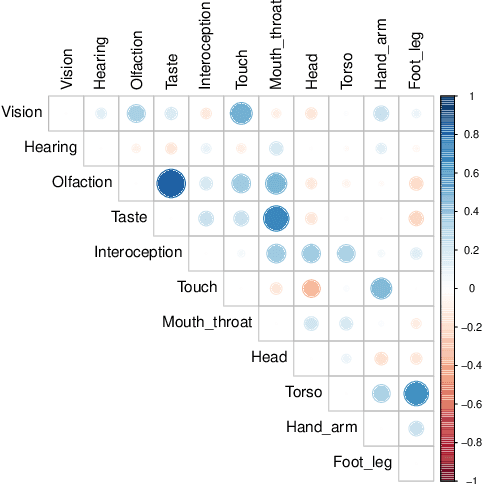
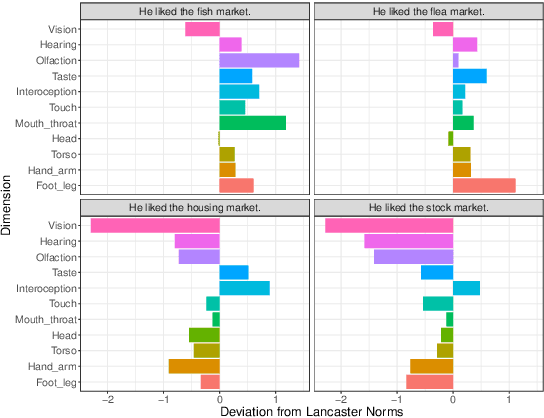
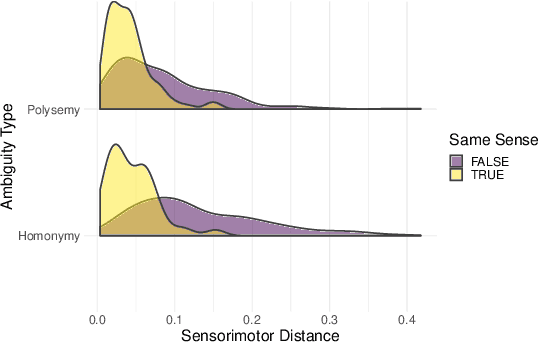
Most large language models are trained on linguistic input alone, yet humans appear to ground their understanding of words in sensorimotor experience. A natural solution is to augment LM representations with human judgments of a word's sensorimotor associations (e.g., the Lancaster Sensorimotor Norms), but this raises another challenge: most words are ambiguous, and judgments of words in isolation fail to account for this multiplicity of meaning (e.g., "wooden table" vs. "data table"). We attempted to address this problem by building a new lexical resource of contextualized sensorimotor judgments for 112 English words, each rated in four different contexts (448 sentences total). We show that these ratings encode overlapping but distinct information from the Lancaster Sensorimotor Norms, and that they also predict other measures of interest (e.g., relatedness), above and beyond measures derived from BERT. Beyond shedding light on theoretical questions, we suggest that these ratings could be of use as a "challenge set" for researchers building grounded language models.