 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRAW-C: Relatedness of Ambiguous Words--in Context
Paper and Code


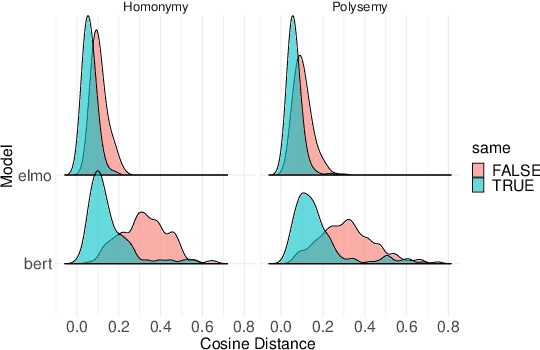
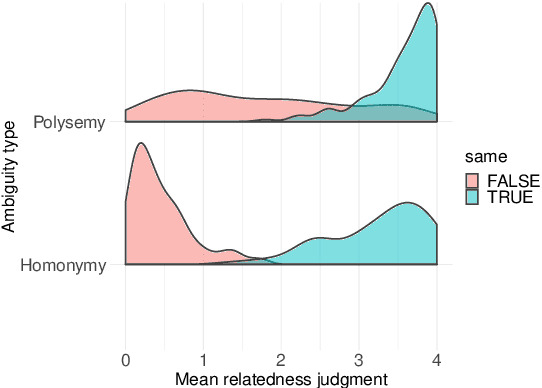
Most words are ambiguous--i.e., they convey distinct meanings in different contexts--and even the meanings of unambiguous words are context-dependent. Both phenomena present a challenge for NLP. Recently, the advent of contextualized word embeddings has led to success on tasks involving lexical ambiguity, such as Word Sense Disambiguation. However, there are few tasks that directly evaluate how well these contextualized embeddings accommodate the more continuous, dynamic nature of word meaning--particularly in a way that matches human intuitions. We introduce RAW-C, a dataset of graded, human relatedness judgments for 112 ambiguous words in context (with 672 sentence pairs total), as well as human estimates of sense dominance. The average inter-annotator agreement (assessed using a leave-one-annotator-out method) was 0.79. We then show that a measure of cosine distance, computed using contextualized embeddings from BERT and ELMo, correlates with human judgments, but that cosine distance also systematically underestimates how similar humans find uses of the same sense of a word to be, and systematically overestimates how similar humans find uses of different-sense homonyms. Finally, we propose a synthesis between psycholinguistic theories of the mental lexicon and computational models of lexical semantics.