 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProfiling checkpointing schedules in adjoint ST-AD
May 24, 2024Checkpointing is a cornerstone of data-flow reversal in adjoint algorithmic differentiation. Checkpointing is a storage/recomputation trade-off that can be applied at different levels, one of which being the call tree. We are looking for good placements of checkpoints onto the call tree of a given application, to reduce run time and memory footprint of its adjoint. There is no known optimal solution to this problem other than a combinatorial search on all placements. We propose a heuristics based on run-time profiling of the adjoint code. We describe implementation of this profiling tool in an existing source-transformation AD tool. We demonstrate the interest of this approach on test cases taken from the MITgcm ocean and atmospheric global circulation model. We discuss the limitations of our approach and propose directions to lift them.
Forward Gradients for Data-Driven CFD Wall Modeling
Nov 28, 2023
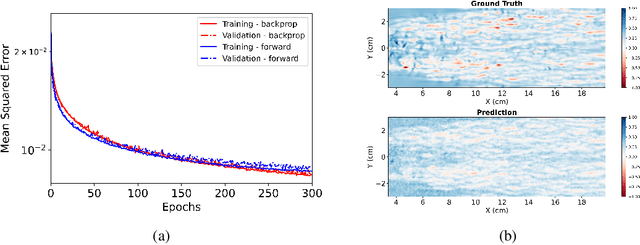
Computational Fluid Dynamics (CFD) is used in the design and optimization of gas turbines and many other industrial/ scientific applications. However, the practical use is often limited by the high computational cost, and the accurate resolution of near-wall flow is a significant contributor to this cost. Machine learning (ML) and other data-driven methods can complement existing wall models. Nevertheless, training these models is bottlenecked by the large computational effort and memory footprint demanded by back-propagation. Recent work has presented alternatives for computing gradients of neural networks where a separate forward and backward sweep is not needed and storage of intermediate results between sweeps is not required because an unbiased estimator for the gradient is computed in a single forward sweep. In this paper, we discuss the application of this approach for training a subgrid wall model that could potentially be used as a surrogate in wall-bounded flow CFD simulations to reduce the computational overhead while preserving predictive accuracy.
Surrogate Neural Networks to Estimate Parametric Sensitivity of Ocean Models
Nov 10, 2023



Modeling is crucial to understanding the effect of greenhouse gases, warming, and ice sheet melting on the ocean. At the same time, ocean processes affect phenomena such as hurricanes and droughts. Parameters in the models that cannot be physically measured have a significant effect on the model output. For an idealized ocean model, we generated perturbed parameter ensemble data and trained surrogate neural network models. The neural surrogates accurately predicted the one-step forward dynamics, of which we then computed the parametric sensitivity.
Understanding Automatic Differentiation Pitfalls
May 12, 2023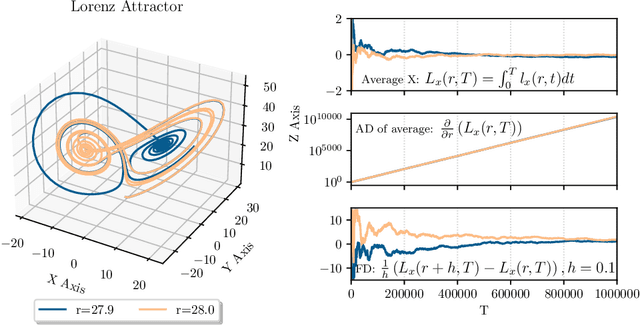
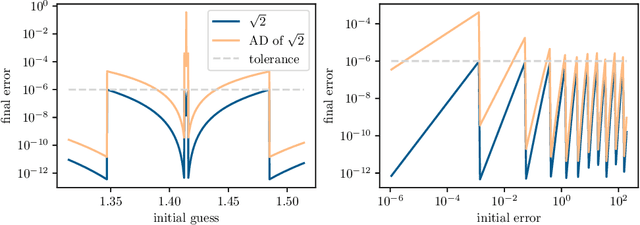
Automatic differentiation, also known as backpropagation, AD, autodiff, or algorithmic differentiation, is a popular technique for computing derivatives of computer programs accurately and efficiently. Sometimes, however, the derivatives computed by AD could be interpreted as incorrect. These pitfalls occur systematically across tools and approaches. In this paper we broadly categorize problematic usages of AD and illustrate each category with examples such as chaos, time-averaged oscillations, discretizations, fixed-point loops, lookup tables, and linear solvers. We also review debugging techniques and their effectiveness in these situations. With this article we hope to help readers avoid unexpected behavior, detect problems more easily when they occur, and have more realistic expectations from AD tools.
Source-to-Source Automatic Differentiation of OpenMP Parallel Loops
Nov 02, 2021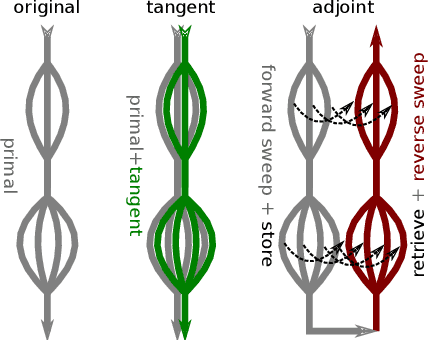



This paper presents our work toward correct and efficient automatic differentiation of OpenMP parallel worksharing loops in forward and reverse mode. Automatic differentiation is a method to obtain gradients of numerical programs, which are crucial in optimization, uncertainty quantification, and machine learning. The computational cost to compute gradients is a common bottleneck in practice. For applications that are parallelized for multicore CPUs or GPUs using OpenMP, one also wishes to compute the gradients in parallel. We propose a framework to reason about the correctness of the generated derivative code, from which we justify our OpenMP extension to the differentiation model. We implement this model in the automatic differentiation tool Tapenade and present test cases that are differentiated following our extended differentiation procedure. Performance of the generated derivative programs in forward and reverse mode is better than sequential, although our reverse mode often scales worse than the input programs.
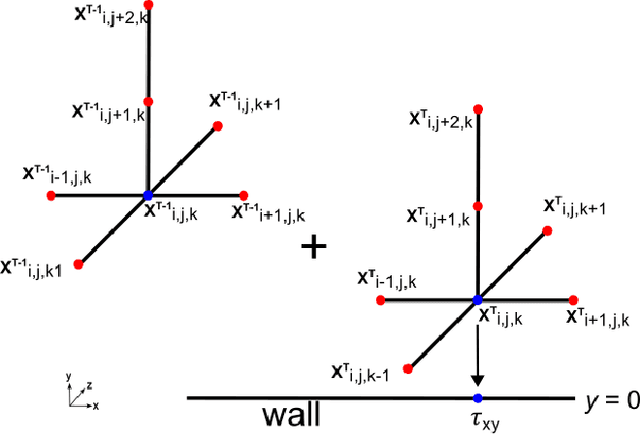
Automatic Differentiation for Adjoint Stencil Loops
Jul 05, 2019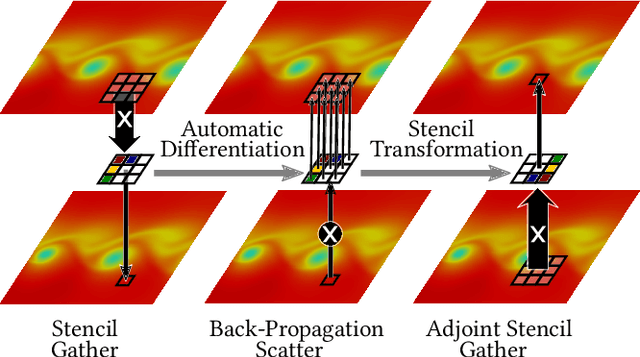
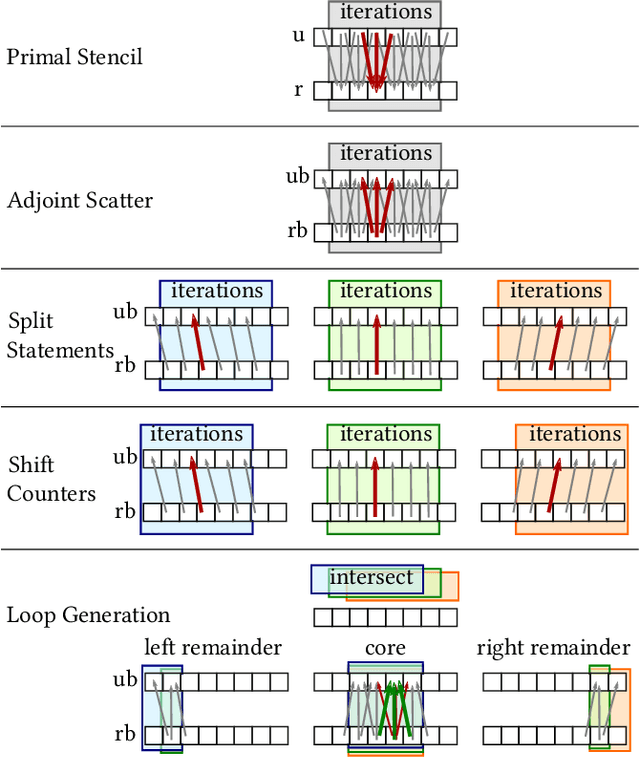
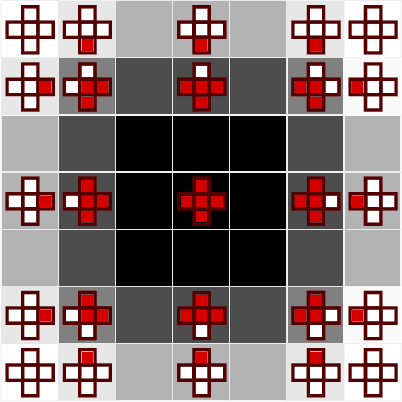

Stencil loops are a common motif in computations including convolutional neural networks, structured-mesh solvers for partial differential equations, and image processing. Stencil loops are easy to parallelise, and their fast execution is aided by compilers, libraries, and domain-specific languages. Reverse-mode automatic differentiation, also known as algorithmic differentiation, autodiff, adjoint differentiation, or back-propagation, is sometimes used to obtain gradients of programs that contain stencil loops. Unfortunately, conventional automatic differentiation results in a memory access pattern that is not stencil-like and not easily parallelisable. In this paper we present a novel combination of automatic differentiation and loop transformations that preserves the structure and memory access pattern of stencil loops, while computing fully consistent derivatives. The generated loops can be parallelised and optimised for performance in the same way and using the same tools as the original computation. We have implemented this new technique in the Python tool PerforAD, which we release with this paper along with test cases derived from seismic imaging and computational fluid dynamics applications.