 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeForward Gradients for Data-Driven CFD Wall Modeling
Nov 28, 2023
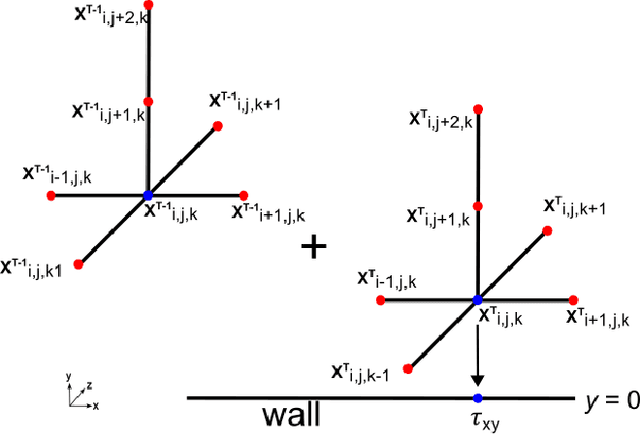
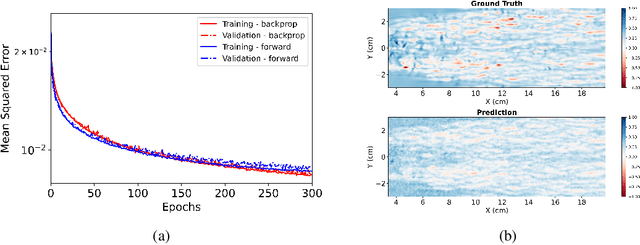
Computational Fluid Dynamics (CFD) is used in the design and optimization of gas turbines and many other industrial/ scientific applications. However, the practical use is often limited by the high computational cost, and the accurate resolution of near-wall flow is a significant contributor to this cost. Machine learning (ML) and other data-driven methods can complement existing wall models. Nevertheless, training these models is bottlenecked by the large computational effort and memory footprint demanded by back-propagation. Recent work has presented alternatives for computing gradients of neural networks where a separate forward and backward sweep is not needed and storage of intermediate results between sweeps is not required because an unbiased estimator for the gradient is computed in a single forward sweep. In this paper, we discuss the application of this approach for training a subgrid wall model that could potentially be used as a surrogate in wall-bounded flow CFD simulations to reduce the computational overhead while preserving predictive accuracy.
A Physics-Constrained NeuralODE Approach for Robust Learning of Stiff Chemical Kinetics
Nov 22, 2023The high computational cost associated with solving for detailed chemistry poses a significant challenge for predictive computational fluid dynamics (CFD) simulations of turbulent reacting flows. These models often require solving a system of coupled stiff ordinary differential equations (ODEs). While deep learning techniques have been experimented with to develop faster surrogate models, they often fail to integrate reliably with CFD solvers. This instability arises because deep learning methods optimize for training error without ensuring compatibility with ODE solvers, leading to accumulation of errors over time. Recently, NeuralODE-based techniques have offered a promising solution by effectively modeling chemical kinetics. In this study, we extend the NeuralODE framework for stiff chemical kinetics by incorporating mass conservation constraints directly into the loss function during training. This ensures that the total mass and the elemental mass are conserved, a critical requirement for reliable downstream integration with CFD solvers. Our results demonstrate that this enhancement not only improves the physical consistency with respect to mass conservation criteria but also ensures better robustness and makes the training process more computationally efficient.