 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFedQueue: Queue-Aware Federated Learning for Cross-Facility HPC Training
May 04, 2026Federated learning (FL) across multiple HPC facilities faces stochastic admission delays from batch schedulers that dominate wall-clock time. Synchronous FL suffers from severe stragglers, while asynchronous FL accumulates stale updates when queues spike. We propose FedQueue, a queue-aware FL protocol that incorporates scheduler delays directly into training and aggregation, which (i) predicts per-facility queue delays online to budget local work, (ii) applies cutoff-based admission that buffers late arrivals to bound staleness, and (iii) performs staleness-aware aggregation to stabilize heterogeneous local workloads. We prove the convergence for non-convex objectives at rate $\mathcal{O}(1/\sqrt{R})$ under bounded staleness, and show that the admission controls yield bounded staleness with high probability under queue-prediction error. Real-world cross-facility deployment of FedQueue shows 20.5% improvement over baseline algorithms. Controlled queue simulations demonstrate robust improvement over the baselines; in particular, about 34% reduction in time to reach a target accuracy level under high queue variance and non-IID partitions.
Incentive-Aware Federated Averaging with Performance Guarantees under Strategic Participation
Mar 21, 2026Federated learning (FL) is a communication-efficient collaborative learning framework that enables model training across multiple agents with private local datasets. While the benefits of FL in improving global model performance are well established, individual agents may behave strategically, balancing the learning payoff against the cost of contributing their local data. Motivated by the need for FL frameworks that successfully retain participating agents, we propose an incentive-aware federated averaging method in which, at each communication round, clients transmit both their local model parameters and their updated training dataset sizes to the server. The dataset sizes are dynamically adjusted via a Nash equilibrium (NE)-seeking update rule that captures strategic data participation. We analyze the proposed method under convex and nonconvex global objective settings and establish performance guarantees for the resulting incentive-aware FL algorithm. Numerical experiments on the MNIST and CIFAR-10 datasets demonstrate that agents achieve competitive global model performance while converging to stable data participation strategies.
Mitigating Task-Order Sensitivity and Forgetting via Hierarchical Second-Order Consolidation
Jan 31, 2026We introduce $\textbf{Hierarchical Taylor Series-based Continual Learning (HTCL)}$, a framework that couples fast local adaptation with conservative, second-order global consolidation to address the high variance introduced by random task ordering. To address task-order effects, HTCL identifies the best intra-group task sequence and integrates the resulting local updates through a Hessian-regularized Taylor expansion, yielding a consolidation step with theoretical guarantees. The approach naturally extends to an $L$-level hierarchy, enabling multiscale knowledge integration in a manner not supported by conventional single-level CL systems. Across a wide range of datasets and replay and regularization baselines, HTCL acts as a model-agnostic consolidation layer that consistently enhances performance, yielding mean accuracy gains of $7\%$ to $25\%$ while reducing the standard deviation of final accuracy by up to $68\%$ across random task permutations.
The Effect of Architecture During Continual Learning
Jan 27, 2026Continual learning is a challenge for models with static architecture, as they fail to adapt to when data distributions evolve across tasks. We introduce a mathematical framework that jointly models architecture and weights in a Sobolev space, enabling a rigorous investigation into the role of neural network architecture in continual learning and its effect on the forgetting loss. We derive necessary conditions for the continual learning solution and prove that learning only model weights is insufficient to mitigate catastrophic forgetting under distribution shifts. Consequently, we prove that by learning the architecture and weights simultaneously at each task, we can reduce catastrophic forgetting. To learn weights and architecture simultaneously, we formulate continual learning as a bilevel optimization problem: the upper level selects an optimal architecture for a given task, while the lower level computes optimal weights via dynamic programming over all tasks. To solve the upper level problem, we introduce a derivative-free direct search algorithm to determine the optimal architecture. Once found, we must transfer knowledge from the current architecture to the optimal one. However, the optimal architecture will result in a weights parameter space different from the current architecture (i.e., dimensions of weights matrices will not match). To bridge the dimensionality gap, we develop a low-rank transfer mechanism to map knowledge across architectures of mismatched dimensions. Empirical studies across regression and classification problems, including feedforward, convolutional, and graph neural networks, demonstrate that learning the optimal architecture and weights simultaneously yields substantially improved performance (up to two orders of magnitude), reduced forgetting, and enhanced robustness to noise compared with static architecture approaches.
Who Gets the Reward, Who Gets the Blame? Evaluation-Aligned Training Signals for Multi-LLM Agents
Nov 17, 2025Large Language Models (LLMs) in multi-agent systems (MAS) have shown promise for complex tasks, yet current training methods lack principled ways to connect system-level evaluation with agent-level and message-level learning. We propose a theoretical framework that unifies cooperative game-theoretic attribution with process reward modeling to transform system evaluation into agent credit and then into response-level signals. Unlike prior approaches that rely only on attribution (e.g., Shapley) or step-level labels (e.g., PRM), our method produces local, signed, and credit-conserving signals. In success cases, Shapley-based credit assignment fairly allocates outcomes across agents and is refined into per-message rewards that promote cooperation while discouraging redundancy or sabotage. In failure cases, first-error localization yields repair-aware preferences that penalize harmful steps while rewarding corrective attempts. The resulting signals are bounded, cooperative, and directly compatible with reinforcement-based or preference-based post-training, providing a unified and auditable pathway from global evaluation to local supervision in LLM multi-agent training. Our contribution is conceptual: we present a theoretical foundation and training signals, leaving empirical validation for future work.
On Understanding of the Dynamics of Model Capacity in Continual Learning
Aug 11, 2025The stability-plasticity dilemma, closely related to a neural network's (NN) capacity-its ability to represent tasks-is a fundamental challenge in continual learning (CL). Within this context, we introduce CL's effective model capacity (CLEMC) that characterizes the dynamic behavior of the stability-plasticity balance point. We develop a difference equation to model the evolution of the interplay between the NN, task data, and optimization procedure. We then leverage CLEMC to demonstrate that the effective capacity-and, by extension, the stability-plasticity balance point is inherently non-stationary. We show that regardless of the NN architecture or optimization method, a NN's ability to represent new tasks diminishes when incoming task distributions differ from previous ones. We conduct extensive experiments to support our theoretical findings, spanning a range of architectures-from small feedforward network and convolutional networks to medium-sized graph neural networks and transformer-based large language models with millions of parameters.
Sampling Imbalanced Data with Multi-objective Bilevel Optimization
Jun 12, 2025Two-class classification problems are often characterized by an imbalance between the number of majority and minority datapoints resulting in poor classification of the minority class in particular. Traditional approaches, such as reweighting the loss function or na\"ive resampling, risk overfitting and subsequently fail to improve classification because they do not consider the diversity between majority and minority datasets. Such consideration is infeasible because there is no metric that can measure the impact of imbalance on the model. To obviate these challenges, we make two key contributions. First, we introduce MOODS~(Multi-Objective Optimization for Data Sampling), a novel multi-objective bilevel optimization framework that guides both synthetic oversampling and majority undersampling. Second, we introduce a validation metric -- `$\epsilon/ \delta$ non-overlapping diversification metric' -- that quantifies the goodness of a sampling method towards model performance. With this metric we experimentally demonstrate state-of-the-art performance with improvement in diversity driving a $1-15 \%$ increase in $F1$ scores.
A Bilevel Optimization Framework for Imbalanced Data Classification
Oct 15, 2024



Data rebalancing techniques, including oversampling and undersampling, are a common approach to addressing the challenges of imbalanced data. To tackle unresolved problems related to both oversampling and undersampling, we propose a new undersampling approach that: (i) avoids the pitfalls of noise and overlap caused by synthetic data and (ii) avoids the pitfall of under-fitting caused by random undersampling. Instead of undersampling majority data randomly, our method undersamples datapoints based on their ability to improve model loss. Using improved model loss as a proxy measurement for classification performance, our technique assesses a datapoint's impact on loss and rejects those unable to improve it. In so doing, our approach rejects majority datapoints redundant to datapoints already accepted and, thereby, finds an optimal subset of majority training data for classification. The accept/reject component of our algorithm is motivated by a bilevel optimization problem uniquely formulated to identify the optimal training set we seek. Experimental results show our proposed technique with F1 scores up to 10% higher than state-of-the-art methods.
Large Language Models for Anomaly Detection in Computational Workflows: from Supervised Fine-Tuning to In-Context Learning
Jul 24, 2024



Anomaly detection in computational workflows is critical for ensuring system reliability and security. However, traditional rule-based methods struggle to detect novel anomalies. This paper leverages large language models (LLMs) for workflow anomaly detection by exploiting their ability to learn complex data patterns. Two approaches are investigated: 1) supervised fine-tuning (SFT), where pre-trained LLMs are fine-tuned on labeled data for sentence classification to identify anomalies, and 2) in-context learning (ICL) where prompts containing task descriptions and examples guide LLMs in few-shot anomaly detection without fine-tuning. The paper evaluates the performance, efficiency, generalization of SFT models, and explores zero-shot and few-shot ICL prompts and interpretability enhancement via chain-of-thought prompting. Experiments across multiple workflow datasets demonstrate the promising potential of LLMs for effective anomaly detection in complex executions.
Forward Gradients for Data-Driven CFD Wall Modeling
Nov 28, 2023
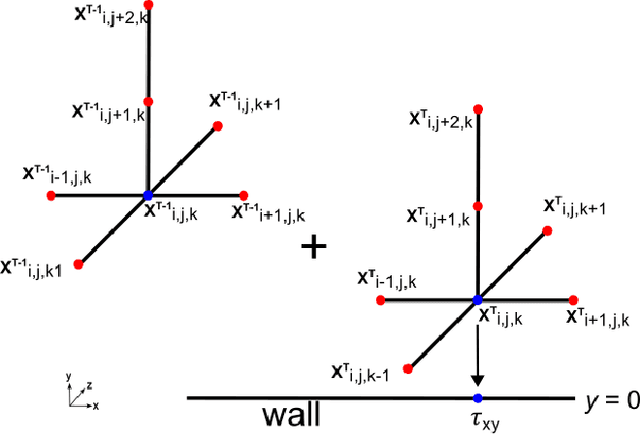
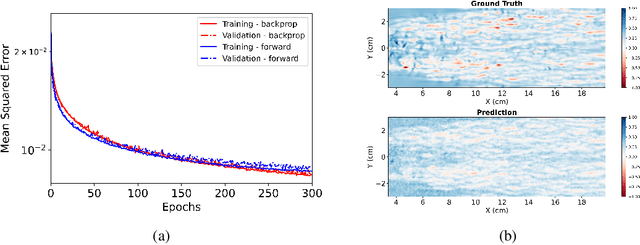
Computational Fluid Dynamics (CFD) is used in the design and optimization of gas turbines and many other industrial/ scientific applications. However, the practical use is often limited by the high computational cost, and the accurate resolution of near-wall flow is a significant contributor to this cost. Machine learning (ML) and other data-driven methods can complement existing wall models. Nevertheless, training these models is bottlenecked by the large computational effort and memory footprint demanded by back-propagation. Recent work has presented alternatives for computing gradients of neural networks where a separate forward and backward sweep is not needed and storage of intermediate results between sweeps is not required because an unbiased estimator for the gradient is computed in a single forward sweep. In this paper, we discuss the application of this approach for training a subgrid wall model that could potentially be used as a surrogate in wall-bounded flow CFD simulations to reduce the computational overhead while preserving predictive accuracy.