 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOptimizing Agentic Language Model Inference via Speculative Tool Calls
Dec 17, 2025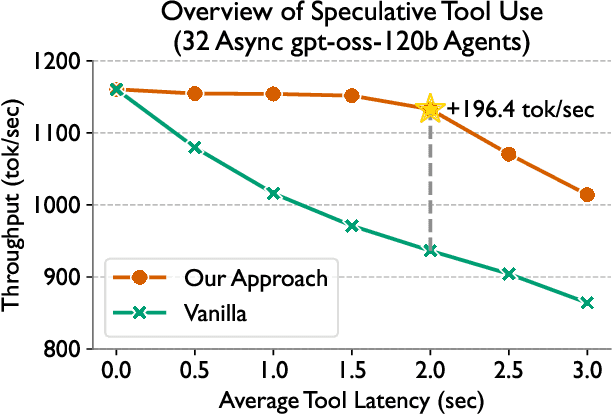
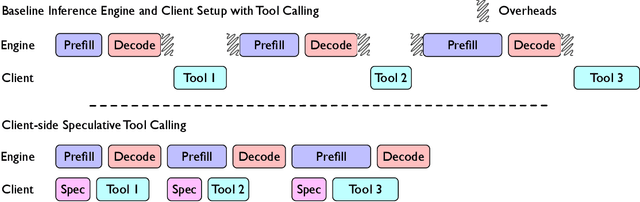
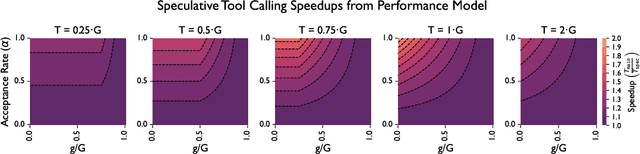
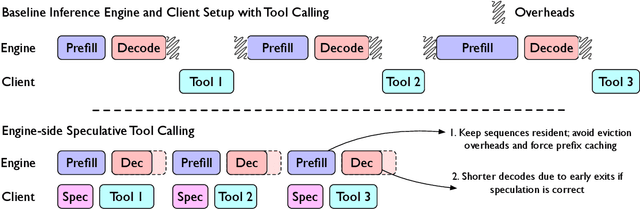
Language models (LMs) are becoming increasingly dependent on external tools. LM-based agentic frameworks frequently interact with their environment via such tools to search files, run code, call APIs, etc. Further, modern reasoning-based LMs use tools such as web search and Python code execution to enhance their reasoning capabilities. While tools greatly improve the capabilities of LMs, they also introduce performance bottlenecks during the inference process. In this paper, we introduce novel systems optimizations to address such performance bottlenecks by speculating tool calls and forcing sequences to remain resident in the inference engine to minimize overheads. Our optimizations lead to throughput improvements of several hundred tokens per second when hosting inference for LM agents. We provide a theoretical analysis of our algorithms to provide insights into speculation configurations that will yield the best performance. Further, we recommend a new "tool cache" API endpoint to enable LM providers to easily adopt these optimizations.
LLM Inference Beyond a Single Node: From Bottlenecks to Mitigations with Fast All-Reduce Communication
Nov 13, 2025
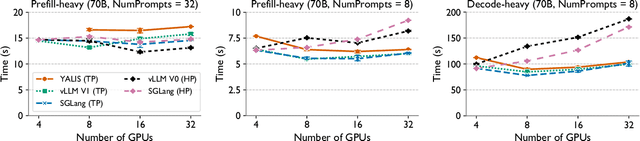

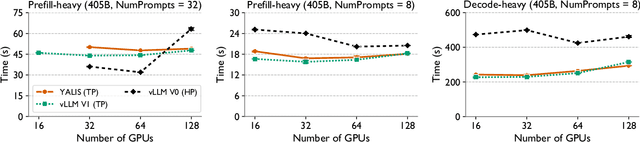
As large language models (LLMs) continue to grow in size, distributed inference has become increasingly important. Model-parallel strategies must now efficiently scale not only across multiple GPUs but also across multiple nodes. In this work, we present a detailed performance study of multi-node distributed inference using LLMs on GPU-based supercomputers. We conduct experiments with several state-of-the-art inference engines alongside YALIS, a research-oriented prototype engine designed for controlled experimentation. We analyze the strong-scaling behavior of different model-parallel schemes and identify key bottlenecks. Since all-reduce operations are a common performance bottleneck, we develop NVRAR, a hierarchical all-reduce algorithm based on recursive doubling with NVSHMEM. NVRAR achieves up to 1.9x-3.6x lower latency than NCCL for message sizes between 128 KB and 2 MB on HPE Slingshot and InfiniBand interconnects. Integrated into YALIS, NVRAR achieves up to a 1.72x reduction in end-to-end batch latency for the Llama 3.1 405B model in multi-node decode-heavy workloads using tensor parallelism.
LLMs as Packagers of HPC Software
Nov 07, 2025High performance computing (HPC) software ecosystems are inherently heterogeneous, comprising scientific applications that depend on hundreds of external packages, each with distinct build systems, options, and dependency constraints. Tools such as Spack automate dependency resolution and environment management, but their effectiveness relies on manually written build recipes. As these ecosystems grow, maintaining existing specifications and creating new ones becomes increasingly labor-intensive. While large language models (LLMs) have shown promise in code generation, automatically producing correct and maintainable Spack recipes remains a significant challenge. We present a systematic analysis of how LLMs and context-augmentation methods can assist in the generation of Spack recipes. To this end, we introduce SpackIt, an end-to-end framework that combines repository analysis, retrieval of relevant examples, and iterative refinement through diagnostic feedback. We apply SpackIt to a representative subset of 308 open-source HPC packages to assess its effectiveness and limitations. Our results show that SpackIt increases installation success from 20% in a zero-shot setting to over 80% in its best configuration, demonstrating the value of retrieval and structured feedback for reliable package synthesis.
Modeling Code: Is Text All You Need?
Jul 15, 2025Code LLMs have become extremely popular recently for modeling source code across a variety of tasks, such as generation, translation, and summarization. However, transformer-based models are limited in their capabilities to reason through structured, analytical properties of code, such as control and data flow. Previous work has explored the modeling of these properties with structured data and graph neural networks. However, these approaches lack the generative capabilities and scale of modern LLMs. In this work, we introduce a novel approach to combine the strengths of modeling both code as text and more structured forms.
Leveraging AI for Productive and Trustworthy HPC Software: Challenges and Research Directions
May 13, 2025We discuss the challenges and propose research directions for using AI to revolutionize the development of high-performance computing (HPC) software. AI technologies, in particular large language models, have transformed every aspect of software development. For its part, HPC software is recognized as a highly specialized scientific field of its own. We discuss the challenges associated with leveraging state-of-the-art AI technologies to develop such a unique and niche class of software and outline our research directions in the two US Department of Energy--funded projects for advancing HPC Software via AI: Ellora and Durban.
Can Large Language Models Predict Parallel Code Performance?
May 06, 2025Accurate determination of the performance of parallel GPU code typically requires execution-time profiling on target hardware -- an increasingly prohibitive step due to limited access to high-end GPUs. This paper explores whether Large Language Models (LLMs) can offer an alternative approach for GPU performance prediction without relying on hardware. We frame the problem as a roofline classification task: given the source code of a GPU kernel and the hardware specifications of a target GPU, can an LLM predict whether the GPU kernel is compute-bound or bandwidth-bound? For this study, we build a balanced dataset of 340 GPU kernels, obtained from HeCBench benchmark and written in CUDA and OpenMP, along with their ground-truth labels obtained via empirical GPU profiling. We evaluate LLMs across four scenarios: (1) with access to profiling data of the kernel source, (2) zero-shot with source code only, (3) few-shot with code and label pairs, and (4) fine-tuned on a small custom dataset. Our results show that state-of-the-art LLMs have a strong understanding of the Roofline model, achieving 100% classification accuracy when provided with explicit profiling data. We also find that reasoning-capable LLMs significantly outperform standard LLMs in zero- and few-shot settings, achieving up to 64% accuracy on GPU source codes, without profiling information. Lastly, we find that LLM fine-tuning will require much more data than what we currently have available. This work is among the first to use LLMs for source-level roofline performance prediction via classification, and illustrates their potential to guide optimization efforts when runtime profiling is infeasible. Our findings suggest that with better datasets and prompt strategies, LLMs could become practical tools for HPC performance analysis and performance portability.
Performance-Aligned LLMs for Generating Fast Code
Apr 29, 2024Optimizing scientific software is a difficult task because codebases are often large and complex, and performance can depend upon several factors including the algorithm, its implementation, and hardware among others. Causes of poor performance can originate from disparate sources and be difficult to diagnose. Recent years have seen a multitude of work that use large language models (LLMs) to assist in software development tasks. However, these tools are trained to model the distribution of code as text, and are not specifically designed to understand performance aspects of code. In this work, we introduce a reinforcement learning based methodology to align the outputs of code LLMs with performance. This allows us to build upon the current code modeling capabilities of LLMs and extend them to generate better performing code. We demonstrate that our fine-tuned model improves the expected speedup of generated code over base models for a set of benchmark tasks from 0.9 to 1.6 for serial code and 1.9 to 4.5 for OpenMP code.
Modeling Parallel Programs using Large Language Models
Jun 29, 2023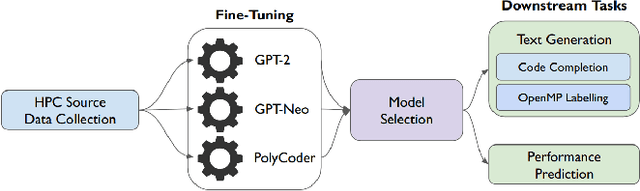
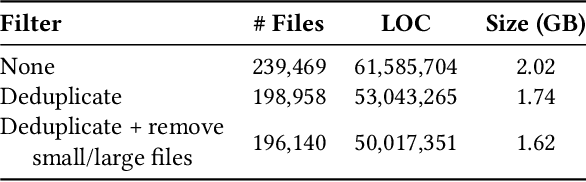
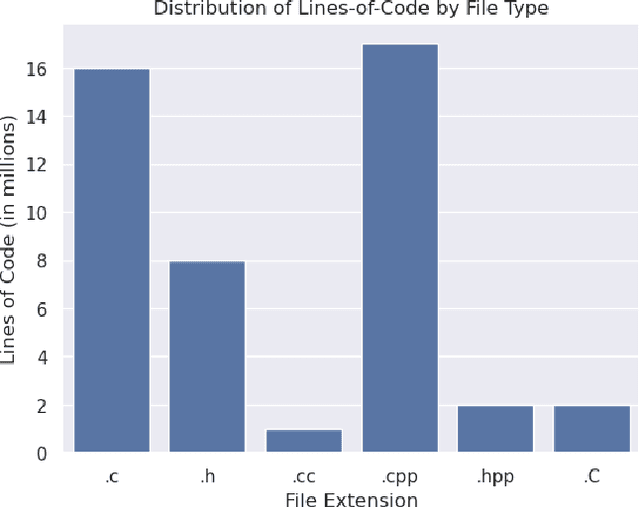

Parallel software codes in high performance computing (HPC) continue to grow in complexity and scale as we enter the exascale era. A diverse set of emerging hardware and programming paradigms make developing, optimizing, and maintaining parallel software burdensome for developers. One way to alleviate some of these burdens is with automated development and analysis tools. Such tools can perform complex and/or remedial tasks for developers that increase their productivity and decrease the chance for error. So far, such tools for code development and performance analysis have been limited in the complexity of tasks they can perform. However, with recent advancements in language modeling, and the wealth of code related data that is now available online, these tools have started to utilize predictive language models to automate more complex tasks. In this paper, we show how large language models (LLMs) can be applied to tasks specific to high performance and scientific codes. We train LLMs using code and performance data that is specific to parallel codes. We compare several recent LLMs on HPC related tasks and introduce a new model, HPC-Coder, trained on parallel code. In our experiments we show that this model can auto-complete HPC functions where general models cannot, decorate for loops with OpenMP pragmas, and model performance changes in two scientific application repositories.
Understanding Automatic Differentiation Pitfalls
May 12, 2023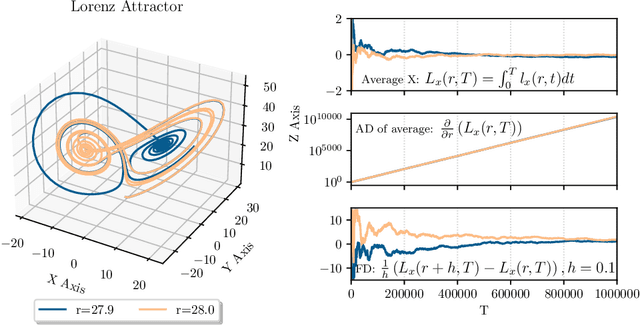
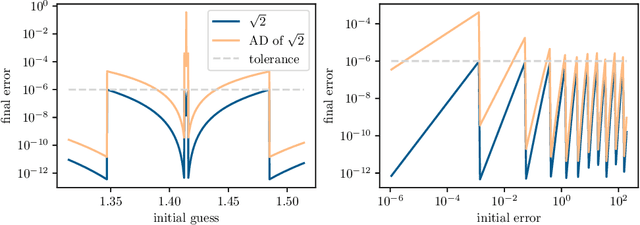
Automatic differentiation, also known as backpropagation, AD, autodiff, or algorithmic differentiation, is a popular technique for computing derivatives of computer programs accurately and efficiently. Sometimes, however, the derivatives computed by AD could be interpreted as incorrect. These pitfalls occur systematically across tools and approaches. In this paper we broadly categorize problematic usages of AD and illustrate each category with examples such as chaos, time-averaged oscillations, discretizations, fixed-point loops, lookup tables, and linear solvers. We also review debugging techniques and their effectiveness in these situations. With this article we hope to help readers avoid unexpected behavior, detect problems more easily when they occur, and have more realistic expectations from AD tools.