 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLLMs as Packagers of HPC Software
Nov 07, 2025High performance computing (HPC) software ecosystems are inherently heterogeneous, comprising scientific applications that depend on hundreds of external packages, each with distinct build systems, options, and dependency constraints. Tools such as Spack automate dependency resolution and environment management, but their effectiveness relies on manually written build recipes. As these ecosystems grow, maintaining existing specifications and creating new ones becomes increasingly labor-intensive. While large language models (LLMs) have shown promise in code generation, automatically producing correct and maintainable Spack recipes remains a significant challenge. We present a systematic analysis of how LLMs and context-augmentation methods can assist in the generation of Spack recipes. To this end, we introduce SpackIt, an end-to-end framework that combines repository analysis, retrieval of relevant examples, and iterative refinement through diagnostic feedback. We apply SpackIt to a representative subset of 308 open-source HPC packages to assess its effectiveness and limitations. Our results show that SpackIt increases installation success from 20% in a zero-shot setting to over 80% in its best configuration, demonstrating the value of retrieval and structured feedback for reliable package synthesis.
Leveraging AI for Productive and Trustworthy HPC Software: Challenges and Research Directions
May 13, 2025We discuss the challenges and propose research directions for using AI to revolutionize the development of high-performance computing (HPC) software. AI technologies, in particular large language models, have transformed every aspect of software development. For its part, HPC software is recognized as a highly specialized scientific field of its own. We discuss the challenges associated with leveraging state-of-the-art AI technologies to develop such a unique and niche class of software and outline our research directions in the two US Department of Energy--funded projects for advancing HPC Software via AI: Ellora and Durban.
Toward a Cohesive AI and Simulation Software Ecosystem for Scientific Innovation
Nov 14, 2024In this paper, we discuss the need for an integrated software stack that unites artificial intelligence (AI) and modeling and simulation (ModSim) tools to advance scientific discovery. The authors advocate for a unified AI/ModSim software ecosystem that ensures compatibility across a wide range of software on diverse high-performance computing systems, promoting ease of deployment, version management, and binary distribution. Key challenges highlighted include balancing the distinct needs of AI and ModSim, especially in terms of software build practices, dependency management, and compatibility. The document underscores the importance of continuous integration, community-driven stewardship, and collaboration with the Department of Energy (DOE) to develop a portable and cohesive scientific software ecosystem. Recommendations focus on supporting standardized environments through initiatives like the Extreme-scale Scientific Software Stack (E4S) and Spack to foster interdisciplinary innovation and facilitate new scientific advancements.
Performance-Aligned LLMs for Generating Fast Code
Apr 29, 2024Optimizing scientific software is a difficult task because codebases are often large and complex, and performance can depend upon several factors including the algorithm, its implementation, and hardware among others. Causes of poor performance can originate from disparate sources and be difficult to diagnose. Recent years have seen a multitude of work that use large language models (LLMs) to assist in software development tasks. However, these tools are trained to model the distribution of code as text, and are not specifically designed to understand performance aspects of code. In this work, we introduce a reinforcement learning based methodology to align the outputs of code LLMs with performance. This allows us to build upon the current code modeling capabilities of LLMs and extend them to generate better performing code. We demonstrate that our fine-tuned model improves the expected speedup of generated code over base models for a set of benchmark tasks from 0.9 to 1.6 for serial code and 1.9 to 4.5 for OpenMP code.
Modeling Parallel Programs using Large Language Models
Jun 29, 2023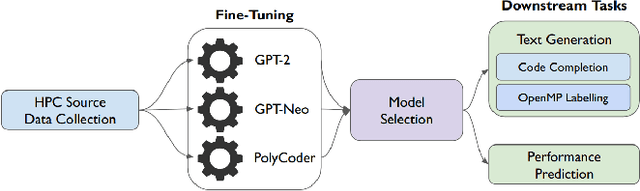
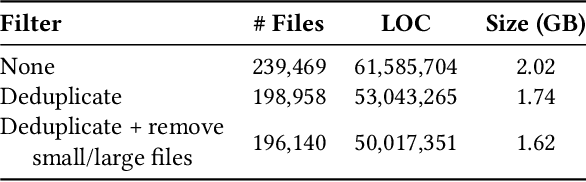
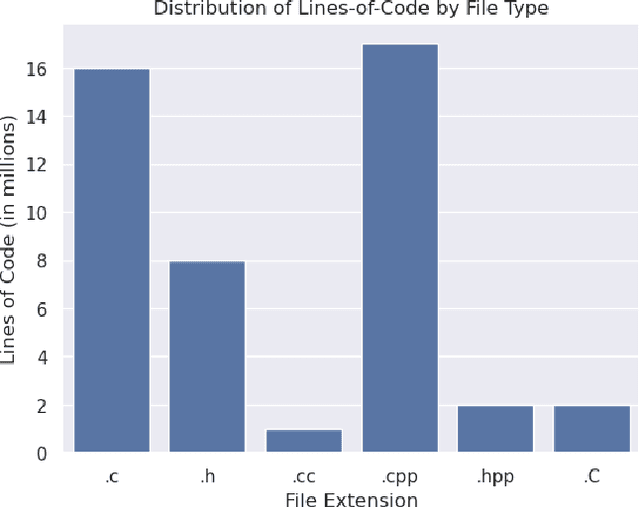

Parallel software codes in high performance computing (HPC) continue to grow in complexity and scale as we enter the exascale era. A diverse set of emerging hardware and programming paradigms make developing, optimizing, and maintaining parallel software burdensome for developers. One way to alleviate some of these burdens is with automated development and analysis tools. Such tools can perform complex and/or remedial tasks for developers that increase their productivity and decrease the chance for error. So far, such tools for code development and performance analysis have been limited in the complexity of tasks they can perform. However, with recent advancements in language modeling, and the wealth of code related data that is now available online, these tools have started to utilize predictive language models to automate more complex tasks. In this paper, we show how large language models (LLMs) can be applied to tasks specific to high performance and scientific codes. We train LLMs using code and performance data that is specific to parallel codes. We compare several recent LLMs on HPC related tasks and introduce a new model, HPC-Coder, trained on parallel code. In our experiments we show that this model can auto-complete HPC functions where general models cannot, decorate for loops with OpenMP pragmas, and model performance changes in two scientific application repositories.
Machine Learning-Driven Adaptive OpenMP For Portable Performance on Heterogeneous Systems
Mar 15, 2023



Heterogeneity has become a mainstream architecture design choice for building High Performance Computing systems. However, heterogeneity poses significant challenges for achieving performance portability of execution. Adapting a program to a new heterogeneous platform is laborious and requires developers to manually explore a vast space of execution parameters. To address those challenges, this paper proposes new extensions to OpenMP for autonomous, machine learning-driven adaptation. Our solution includes a set of novel language constructs, compiler transformations, and runtime support. We propose a producer-consumer pattern to flexibly define multiple, different variants of OpenMP code regions to enable adaptation. Those regions are transparently profiled at runtime to autonomously learn optimizing machine learning models that dynamically select the fastest variant. Our approach significantly reduces users' efforts of programming adaptive applications on heterogeneous architectures by leveraging machine learning techniques and code generation capabilities of OpenMP compilation. Using a complete reference implementation in Clang/LLVM we evaluate three use-cases of adaptive CPU-GPU execution. Experiments with HPC proxy applications and benchmarks demonstrate that the proposed adaptive OpenMP extensions automatically choose the best performing code variants for various adaptation possibilities, in several different heterogeneous platforms of CPUs and GPUs.