 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLeveraging AI for Productive and Trustworthy HPC Software: Challenges and Research Directions
May 13, 2025We discuss the challenges and propose research directions for using AI to revolutionize the development of high-performance computing (HPC) software. AI technologies, in particular large language models, have transformed every aspect of software development. For its part, HPC software is recognized as a highly specialized scientific field of its own. We discuss the challenges associated with leveraging state-of-the-art AI technologies to develop such a unique and niche class of software and outline our research directions in the two US Department of Energy--funded projects for advancing HPC Software via AI: Ellora and Durban.
Fast and accurate object detection in high resolution 4K and 8K video using GPUs
Oct 24, 2018

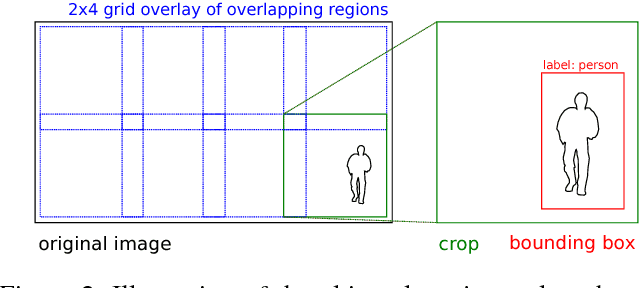

Machine learning has celebrated a lot of achievements on computer vision tasks such as object detection, but the traditionally used models work with relatively low resolution images. The resolution of recording devices is gradually increasing and there is a rising need for new methods of processing high resolution data. We propose an attention pipeline method which uses two staged evaluation of each image or video frame under rough and refined resolution to limit the total number of necessary evaluations. For both stages, we make use of the fast object detection model YOLO v2. We have implemented our model in code, which distributes the work across GPUs. We maintain high accuracy while reaching the average performance of 3-6 fps on 4K video and 2 fps on 8K video.
High Performance Zero-Memory Overhead Direct Convolutions
Sep 20, 2018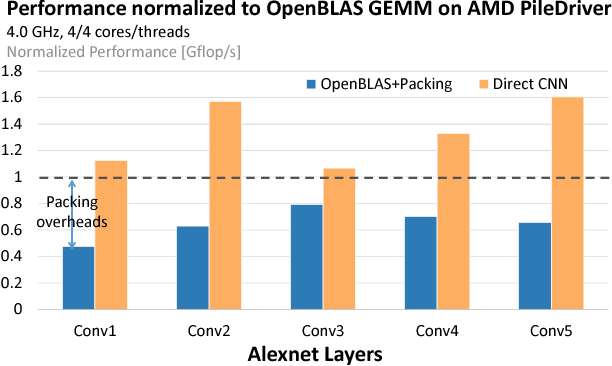
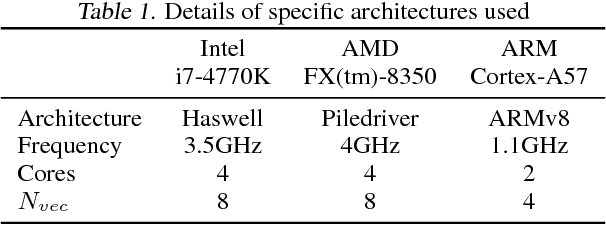

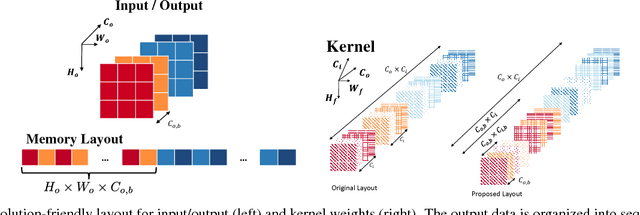
The computation of convolution layers in deep neural networks typically rely on high performance routines that trade space for time by using additional memory (either for packing purposes or required as part of the algorithm) to improve performance. The problems with such an approach are two-fold. First, these routines incur additional memory overhead which reduces the overall size of the network that can fit on embedded devices with limited memory capacity. Second, these high performance routines were not optimized for performing convolution, which means that the performance obtained is usually less than conventionally expected. In this paper, we demonstrate that direct convolution, when implemented correctly, eliminates all memory overhead, and yields performance that is between 10% to 400% times better than existing high performance implementations of convolution layers on conventional and embedded CPU architectures. We also show that a high performance direct convolution exhibits better scaling performance, i.e. suffers less performance drop, when increasing the number of threads.