 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeModeling Parallel Programs using Large Language Models
Paper and Code
Jun 29, 2023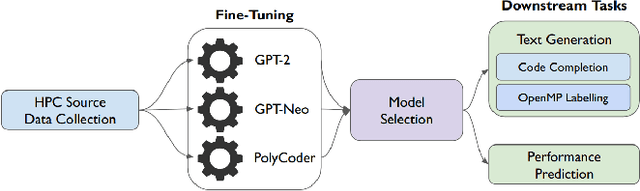
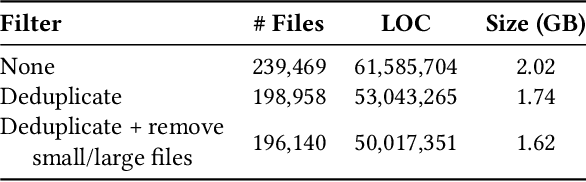
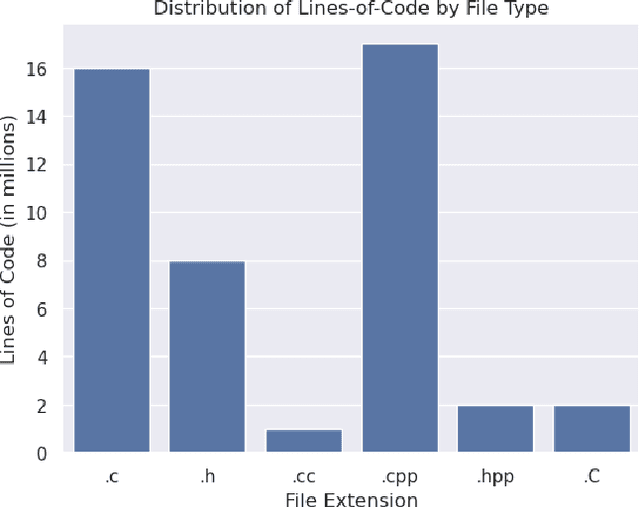

Parallel software codes in high performance computing (HPC) continue to grow in complexity and scale as we enter the exascale era. A diverse set of emerging hardware and programming paradigms make developing, optimizing, and maintaining parallel software burdensome for developers. One way to alleviate some of these burdens is with automated development and analysis tools. Such tools can perform complex and/or remedial tasks for developers that increase their productivity and decrease the chance for error. So far, such tools for code development and performance analysis have been limited in the complexity of tasks they can perform. However, with recent advancements in language modeling, and the wealth of code related data that is now available online, these tools have started to utilize predictive language models to automate more complex tasks. In this paper, we show how large language models (LLMs) can be applied to tasks specific to high performance and scientific codes. We train LLMs using code and performance data that is specific to parallel codes. We compare several recent LLMs on HPC related tasks and introduce a new model, HPC-Coder, trained on parallel code. In our experiments we show that this model can auto-complete HPC functions where general models cannot, decorate for loops with OpenMP pragmas, and model performance changes in two scientific application repositories.