 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeLongCoT: Benchmarking Long-Horizon Chain-of-Thought Reasoning
Apr 15, 2026As language models are increasingly deployed for complex autonomous tasks, their ability to reason accurately over longer horizons becomes critical. An essential component of this ability is planning and managing a long, complex chain-of-thought (CoT). We introduce LongCoT, a scalable benchmark of 2,500 expert-designed problems spanning chemistry, mathematics, computer science, chess, and logic to isolate and directly measure the long-horizon CoT reasoning capabilities of frontier models. Problems consist of a short input with a verifiable answer; solving them requires navigating a graph of interdependent steps that span tens to hundreds of thousands of reasoning tokens. Each local step is individually tractable for frontier models, so failures reflect long-horizon reasoning limitations. At release, the best models achieve <10% accuracy (GPT 5.2: 9.8%; Gemini 3 Pro: 6.1%) on LongCoT, revealing a substantial gap in current capabilities. Overall, LongCoT provides a rigorous measure of long-horizon reasoning, tracking the ability of frontier models to reason reliably over extended periods.
Record-Remix-Replay: Hierarchical GPU Kernel Optimization using Evolutionary Search
Apr 13, 2026As high-performance computing and AI workloads become increasingly dependent on GPUs, maintaining high performance across rapidly evolving hardware generations has become a major challenge. Developers often spend months tuning scientific applications to fully exploit new architectures, navigating a complex optimization space that spans algorithm design, source implementation, compiler flags and pass sequences, and kernel launch parameters. Existing approaches can effectively search parts of this space in isolation, such as launch configurations or compiler settings, but optimizing across the full space still requires substantial human expertise and iterative manual effort. In this paper, we present Record-Remix-Replay (R^3), a hierarchical optimization framework that combines LLM-driven evolutionary search, Bayesian optimization, and record-replay compilation techniques to efficiently explore GPU kernel optimizations from source-level implementation choices down to compiler pass ordering and runtime configuration. By making candidate evaluation fast and scalable, our approach enables practical end-to-end search over optimization dimensions that are typically treated separately. We show that Record-Remix-Replay can optimize full scientific applications better than traditional approaches over kernel parameters and compiler flags, while also being nearly an order of magnitude faster than modern evolutionary search approaches.
Communication-free Sampling and 4D Hybrid Parallelism for Scalable Mini-batch GNN Training
Apr 03, 2026Graph neural networks (GNNs) are widely used for learning on graph datasets derived from various real-world scenarios. Learning from extremely large graphs requires distributed training, and mini-batching with sampling is a popular approach for parallelizing GNN training. Existing distributed mini-batch approaches have significant performance bottlenecks due to expensive sampling methods and limited scaling when using data parallelism. In this work, we present ScaleGNN, a 4D parallel framework for scalable mini-batch GNN training that combines communication-free distributed sampling, 3D parallel matrix multiplication (PMM), and data parallelism. ScaleGNN introduces a uniform vertex sampling algorithm, enabling each process (GPU device) to construct its local mini-batch, i.e., subgraph partitions without any inter-process communication. 3D PMM enables scaling mini-batch training to much larger GPU counts than vanilla data parallelism with significantly lower communication overheads. We also present additional optimizations to overlap sampling with training, reduce communication overhead by sending data in lower precision, kernel fusion, and communication-computation overlap. We evaluate ScaleGNN on five graph datasets and demonstrate strong scaling up to 2048 GPUs on Perlmutter, 2048 GCDs on Frontier, and 1024 GPUs on Tuolumne. On Perlmutter, ScaleGNN achieves 3.5x end-to-end training speedup over the SOTA baseline on ogbn-products.
Optimizing Agentic Language Model Inference via Speculative Tool Calls
Dec 17, 2025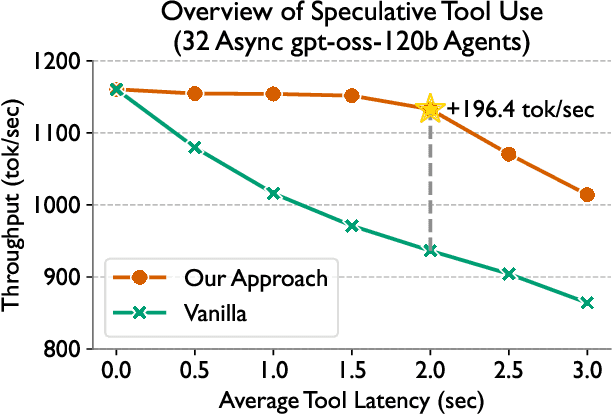
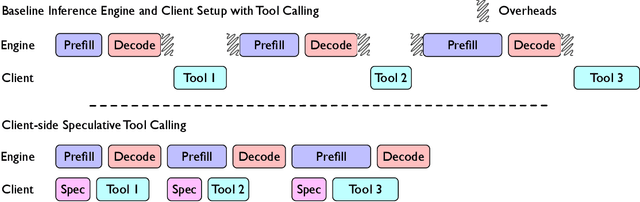
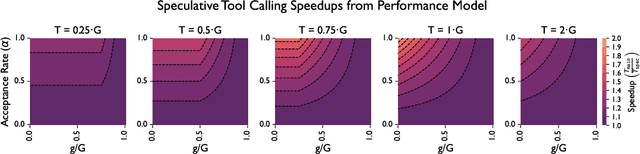
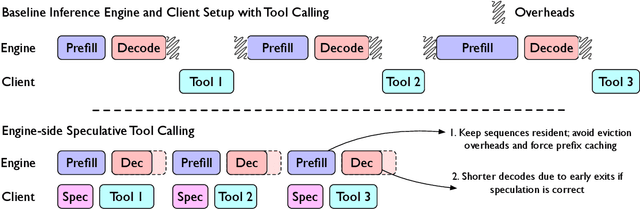
Language models (LMs) are becoming increasingly dependent on external tools. LM-based agentic frameworks frequently interact with their environment via such tools to search files, run code, call APIs, etc. Further, modern reasoning-based LMs use tools such as web search and Python code execution to enhance their reasoning capabilities. While tools greatly improve the capabilities of LMs, they also introduce performance bottlenecks during the inference process. In this paper, we introduce novel systems optimizations to address such performance bottlenecks by speculating tool calls and forcing sequences to remain resident in the inference engine to minimize overheads. Our optimizations lead to throughput improvements of several hundred tokens per second when hosting inference for LM agents. We provide a theoretical analysis of our algorithms to provide insights into speculation configurations that will yield the best performance. Further, we recommend a new "tool cache" API endpoint to enable LM providers to easily adopt these optimizations.
LLMs as Packagers of HPC Software
Nov 07, 2025High performance computing (HPC) software ecosystems are inherently heterogeneous, comprising scientific applications that depend on hundreds of external packages, each with distinct build systems, options, and dependency constraints. Tools such as Spack automate dependency resolution and environment management, but their effectiveness relies on manually written build recipes. As these ecosystems grow, maintaining existing specifications and creating new ones becomes increasingly labor-intensive. While large language models (LLMs) have shown promise in code generation, automatically producing correct and maintainable Spack recipes remains a significant challenge. We present a systematic analysis of how LLMs and context-augmentation methods can assist in the generation of Spack recipes. To this end, we introduce SpackIt, an end-to-end framework that combines repository analysis, retrieval of relevant examples, and iterative refinement through diagnostic feedback. We apply SpackIt to a representative subset of 308 open-source HPC packages to assess its effectiveness and limitations. Our results show that SpackIt increases installation success from 20% in a zero-shot setting to over 80% in its best configuration, demonstrating the value of retrieval and structured feedback for reliable package synthesis.
Modeling Code: Is Text All You Need?
Jul 15, 2025Code LLMs have become extremely popular recently for modeling source code across a variety of tasks, such as generation, translation, and summarization. However, transformer-based models are limited in their capabilities to reason through structured, analytical properties of code, such as control and data flow. Previous work has explored the modeling of these properties with structured data and graph neural networks. However, these approaches lack the generative capabilities and scale of modern LLMs. In this work, we introduce a novel approach to combine the strengths of modeling both code as text and more structured forms.
Leveraging AI for Productive and Trustworthy HPC Software: Challenges and Research Directions
May 13, 2025We discuss the challenges and propose research directions for using AI to revolutionize the development of high-performance computing (HPC) software. AI technologies, in particular large language models, have transformed every aspect of software development. For its part, HPC software is recognized as a highly specialized scientific field of its own. We discuss the challenges associated with leveraging state-of-the-art AI technologies to develop such a unique and niche class of software and outline our research directions in the two US Department of Energy--funded projects for advancing HPC Software via AI: Ellora and Durban.
HPC-Coder-V2: Studying Code LLMs Across Low-Resource Parallel Languages
Dec 19, 2024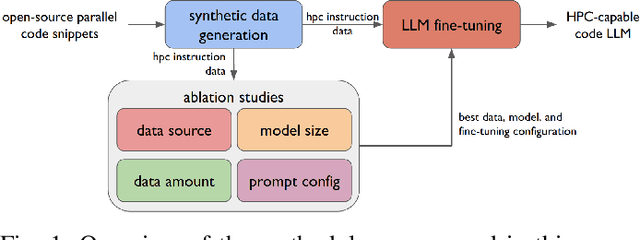
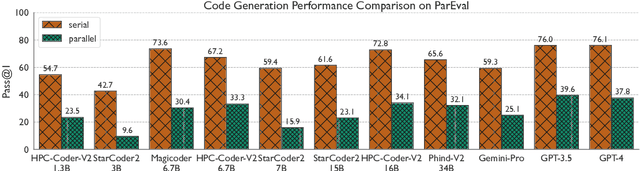
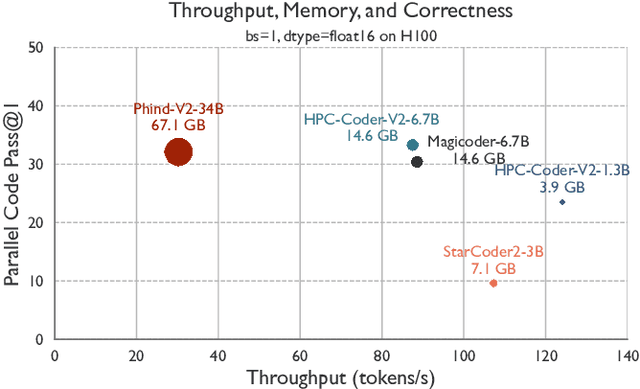
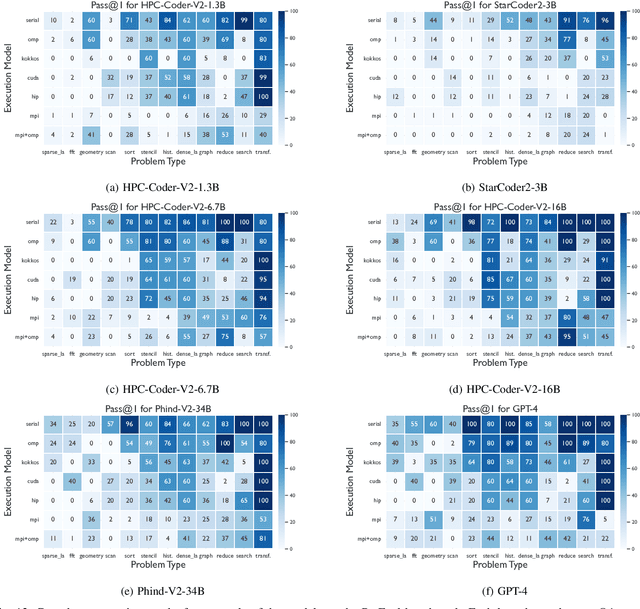
Large Language Model (LLM) based coding tools have been tremendously successful as software development assistants, yet they are often designed for general purpose programming tasks and perform poorly for more specialized domains such as high performance computing. Creating specialized models and tools for these domains is crucial towards gaining the benefits of LLMs in areas such as HPC. While previous work has explored HPC-specific models, LLMs still struggle to generate parallel code and it is not at all clear what hurdles are still holding back these LLMs and what must be done to overcome them. In this work, we conduct an in-depth study along the many axes of fine-tuning a specialized HPC LLM in order to better understand the challenges. Based on our findings we fine-tune and evaluate a specialized HPC LLM that is shown to be the best performing open-source code LLM for parallel code generation to date.
Performance-Aligned LLMs for Generating Fast Code
Apr 29, 2024Optimizing scientific software is a difficult task because codebases are often large and complex, and performance can depend upon several factors including the algorithm, its implementation, and hardware among others. Causes of poor performance can originate from disparate sources and be difficult to diagnose. Recent years have seen a multitude of work that use large language models (LLMs) to assist in software development tasks. However, these tools are trained to model the distribution of code as text, and are not specifically designed to understand performance aspects of code. In this work, we introduce a reinforcement learning based methodology to align the outputs of code LLMs with performance. This allows us to build upon the current code modeling capabilities of LLMs and extend them to generate better performing code. We demonstrate that our fine-tuned model improves the expected speedup of generated code over base models for a set of benchmark tasks from 0.9 to 1.6 for serial code and 1.9 to 4.5 for OpenMP code.
Can Large Language Models Write Parallel Code?
Jan 23, 2024



Large Language Models are becoming an increasingly popular tool for software development. Their ability to model and generate source code has been demonstrated in a variety of contexts, including code completion, summarization, translation, and lookup. However, they often struggle to generate code for more complex tasks. In this paper, we explore the ability of state-of-the-art language models to generate parallel code. We propose a benchmark, PCGBench, consisting of a set of 420 tasks for evaluating the ability of language models to generate parallel code, and we evaluate the performance of several state-of-the-art open- and closed-source language models on these tasks. We introduce novel metrics for comparing parallel code generation performance and use them to explore how well each LLM performs on various parallel programming models and computational problem types.