 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHow to Train Your Neural Network: A Comparative Evaluation
Nov 09, 2021

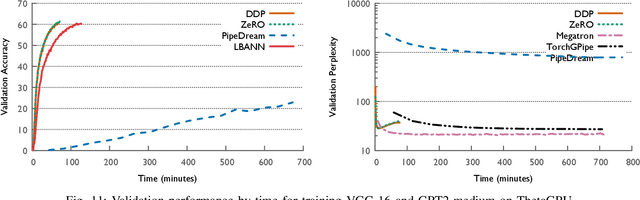
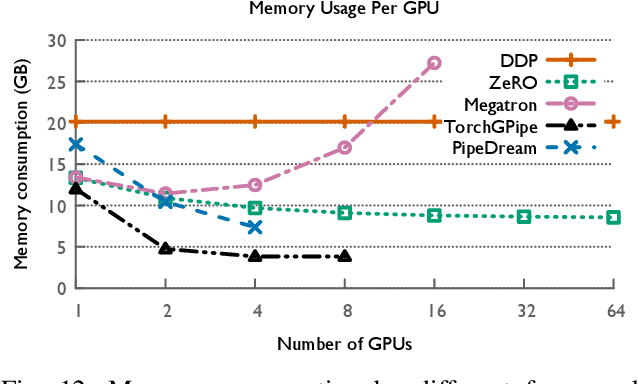
The field of deep learning has witnessed a remarkable shift towards extremely compute- and memory-intensive neural networks. These newer larger models have enabled researchers to advance state-of-the-art tools across a variety of fields. This phenomenon has spurred the development of algorithms for distributed training of neural networks over a larger number of hardware accelerators. In this paper, we discuss and compare current state-of-the-art frameworks for large scale distributed deep learning. First, we survey current practices in distributed learning and identify the different types of parallelism used. Then, we present empirical results comparing their performance on large image and language training tasks. Additionally, we address their statistical efficiency and memory consumption behavior. Based on our results, we discuss algorithmic and implementation portions of each framework which hinder performance.