 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeParaCodex: A Profiling-Guided Autonomous Coding Agent for Reliable Parallel Code Generation and Translation
Jan 07, 2026Parallel programming is central to HPC and AI, but producing code that is correct and fast remains challenging, especially for OpenMP GPU offload, where data movement and tuning dominate. Autonomous coding agents can compile, test, and profile on target hardware, but outputs are brittle without domain scaffolding. We present ParaCodex, an HPC-engineer workflow that turns a Codex-based agent into an autonomous OpenMP GPU offload system using staged hotspot analysis, explicit data planning, correctness gating, and profiling-guided refinement. We evaluate translation from serial CPU kernels to OpenMP GPU offload kernels on HeCBench, Rodinia, and NAS. After excluding five kernels, ParaCodex succeeded on all 31 valid kernels. The generated kernels improved GPU time over reference OpenMP implementations in 25/31 cases, achieving geometric-mean speedups of 3x on HeCBench and 5x on Rodinia, and outperforming a zero-shot Codex baseline on all suites. We also evaluate CUDA to OpenMP offload translation on ParEval, where ParaCodex maintains high compilation and validation rates in code-only and end-to-end settings.
TextureSAM: Towards a Texture Aware Foundation Model for Segmentation
May 22, 2025Segment Anything Models (SAM) have achieved remarkable success in object segmentation tasks across diverse datasets. However, these models are predominantly trained on large-scale semantic segmentation datasets, which introduce a bias toward object shape rather than texture cues in the image. This limitation is critical in domains such as medical imaging, material classification, and remote sensing, where texture changes define object boundaries. In this study, we investigate SAM's bias toward semantics over textures and introduce a new texture-aware foundation model, TextureSAM, which performs superior segmentation in texture-dominant scenarios. To achieve this, we employ a novel fine-tuning approach that incorporates texture augmentation techniques, incrementally modifying training images to emphasize texture features. By leveraging a novel texture-alternation of the ADE20K dataset, we guide TextureSAM to prioritize texture-defined regions, thereby mitigating the inherent shape bias present in the original SAM model. Our extensive experiments demonstrate that TextureSAM significantly outperforms SAM-2 on both natural (+0.2 mIoU) and synthetic (+0.18 mIoU) texture-based segmentation datasets. The code and texture-augmented dataset will be publicly available.
Can Large Language Models Predict Parallel Code Performance?
May 06, 2025Accurate determination of the performance of parallel GPU code typically requires execution-time profiling on target hardware -- an increasingly prohibitive step due to limited access to high-end GPUs. This paper explores whether Large Language Models (LLMs) can offer an alternative approach for GPU performance prediction without relying on hardware. We frame the problem as a roofline classification task: given the source code of a GPU kernel and the hardware specifications of a target GPU, can an LLM predict whether the GPU kernel is compute-bound or bandwidth-bound? For this study, we build a balanced dataset of 340 GPU kernels, obtained from HeCBench benchmark and written in CUDA and OpenMP, along with their ground-truth labels obtained via empirical GPU profiling. We evaluate LLMs across four scenarios: (1) with access to profiling data of the kernel source, (2) zero-shot with source code only, (3) few-shot with code and label pairs, and (4) fine-tuned on a small custom dataset. Our results show that state-of-the-art LLMs have a strong understanding of the Roofline model, achieving 100% classification accuracy when provided with explicit profiling data. We also find that reasoning-capable LLMs significantly outperform standard LLMs in zero- and few-shot settings, achieving up to 64% accuracy on GPU source codes, without profiling information. Lastly, we find that LLM fine-tuning will require much more data than what we currently have available. This work is among the first to use LLMs for source-level roofline performance prediction via classification, and illustrates their potential to guide optimization efforts when runtime profiling is infeasible. Our findings suggest that with better datasets and prompt strategies, LLMs could become practical tools for HPC performance analysis and performance portability.
Reactor Optimization Benchmark by Reinforcement Learning
Mar 21, 2024



Neutronic calculations for reactors are a daunting task when using Monte Carlo (MC) methods. As high-performance computing has advanced, the simulation of a reactor is nowadays more readily done, but design and optimization with multiple parameters is still a computational challenge. MC transport simulations, coupled with machine learning techniques, offer promising avenues for enhancing the efficiency and effectiveness of nuclear reactor optimization. This paper introduces a novel benchmark problem within the OpenNeoMC framework designed specifically for reinforcement learning. The benchmark involves optimizing a unit cell of a research reactor with two varying parameters (fuel density and water spacing) to maximize neutron flux while maintaining reactor criticality. The test case features distinct local optima, representing different physical regimes, thus posing a challenge for learning algorithms. Through extensive simulations utilizing evolutionary and neuroevolutionary algorithms, we demonstrate the effectiveness of reinforcement learning in navigating complex optimization landscapes with strict constraints. Furthermore, we propose acceleration techniques within the OpenNeoMC framework, including model updating and cross-section usage by RAM utilization, to expedite simulation times. Our findings emphasize the importance of machine learning integration in reactor optimization and contribute to advancing methodologies for addressing intricate optimization challenges in nuclear engineering. The sources of this work are available at our GitHub repository: https://github.com/Scientific-Computing-Lab-NRCN/RLOpenNeoMC
MPIrigen: MPI Code Generation through Domain-Specific Language Models
Feb 14, 2024



The imperative need to scale computation across numerous nodes highlights the significance of efficient parallel computing, particularly in the realm of Message Passing Interface (MPI) integration. The challenging parallel programming task of generating MPI-based parallel programs has remained unexplored. This study first investigates the performance of state-of-the-art language models in generating MPI-based parallel programs. Findings reveal that widely used models such as GPT-3.5 and PolyCoder (specialized multi-lingual code models) exhibit notable performance degradation, when generating MPI-based programs compared to general-purpose programs. In contrast, domain-specific models such as MonoCoder, which are pretrained on MPI-related programming languages of C and C++, outperform larger models. Subsequently, we introduce a dedicated downstream task of MPI-based program generation by fine-tuning MonoCoder on HPCorpusMPI. We call the resulting model as MPIrigen. We propose an innovative preprocessing for completion only after observing the whole code, thus enabling better completion with a wider context. Comparative analysis against GPT-3.5 zero-shot performance, using a novel HPC-oriented evaluation method, demonstrates that MPIrigen excels in generating accurate MPI functions up to 0.8 accuracy in location and function predictions, and with more than 0.9 accuracy for argument predictions. The success of this tailored solution underscores the importance of domain-specific fine-tuning in optimizing language models for parallel computing code generation, paving the way for a new generation of automatic parallelization tools. The sources of this work are available at our GitHub MPIrigen repository: https://github.com/Scientific-Computing-Lab-NRCN/MPI-rigen
The Landscape and Challenges of HPC Research and LLMs
Feb 07, 2024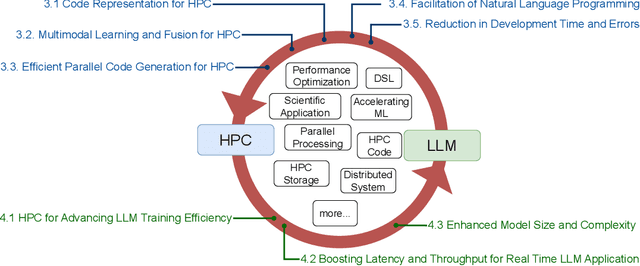

Recently, language models (LMs), especially large language models (LLMs), have revolutionized the field of deep learning. Both encoder-decoder models and prompt-based techniques have shown immense potential for natural language processing and code-based tasks. Over the past several years, many research labs and institutions have invested heavily in high-performance computing, approaching or breaching exascale performance levels. In this paper, we posit that adapting and utilizing such language model-based techniques for tasks in high-performance computing (HPC) would be very beneficial. This study presents our reasoning behind the aforementioned position and highlights how existing ideas can be improved and adapted for HPC tasks.
OMPGPT: A Generative Pre-trained Transformer Model for OpenMP
Jan 28, 2024Large language models (LLMs), as epitomized by models like ChatGPT, have revolutionized the field of natural language processing (NLP). Along with this trend, code-based large language models such as StarCoder, WizardCoder, and CodeLlama have emerged, trained extensively on vast repositories of code data. Yet, inherent in their design, these models primarily focus on generative tasks like code generation, code completion, and comment generation, and general support for multiple programming languages. While the generic abilities of code LLMs are useful for many programmers, the area of high-performance computing (HPC) has a narrower set of requirements that make a smaller and more domain-specific LM a smarter choice. This paper introduces OMPGPT, a novel model meticulously designed to harness the inherent strengths of language models for OpenMP pragma generation. Furthermore, we adopt and adapt prompt engineering techniques from the NLP domain to create chain-of-OMP, an innovative strategy designed to enhance OMPGPT's effectiveness. Our extensive evaluations demonstrate that OMPGPT outperforms existing large language models specialized in OpenMP tasks and maintains a notably smaller size, aligning it more closely with the typical hardware constraints of HPC environments. We consider our contribution as a pivotal bridge, connecting the advantage of language models with the specific demands of HPC tasks. The success of OMPGPT lays a solid foundation, suggesting its potential applicability and adaptability to a wider range of HPC tasks, thereby opening new avenues in the field of computational efficiency and effectiveness.
Domain-Specific Code Language Models: Unraveling the Potential for HPC Codes and Tasks
Dec 20, 2023With easier access to powerful compute resources, there is a growing trend in AI for software development to develop larger language models (LLMs) to address a variety of programming tasks. Even LLMs applied to tasks from the high-performance computing (HPC) domain are huge in size and demand expensive compute resources for training. This is partly because these LLMs for HPC tasks are obtained by finetuning existing LLMs that support several natural and/or programming languages. We found this design choice confusing - why do we need large LMs trained on natural languages and programming languages unrelated to HPC for HPC-specific tasks? In this line of work, we aim to question choices made by existing LLMs by developing smaller LMs for specific domains - we call them domain-specific LMs. Specifically, we start off with HPC as a domain and build an HPC-specific LM, named MonoCoder, that is orders of magnitude smaller than existing LMs but delivers similar, if not better performance, on non-HPC and HPC tasks. Specifically, we pre-trained MonoCoder on an HPC-specific dataset (named HPCorpus) of C and C++ programs mined from GitHub. We evaluated the performance of MonoCoder against conventional multi-lingual LLMs. Results demonstrate that MonoCoder, although much smaller than existing LMs, achieves similar results on normalized-perplexity tests and much better ones in CodeBLEU competence for high-performance and parallel code generations. Furthermore, fine-tuning the base model for the specific task of parallel code generation (OpenMP parallel for pragmas) demonstrates outstanding results compared to GPT, especially when local misleading semantics are removed by our novel pre-processor Tokompiler, showcasing the ability of domain-specific models to assist in HPC-relevant tasks.
CompCodeVet: A Compiler-guided Validation and Enhancement Approach for Code Dataset
Nov 11, 2023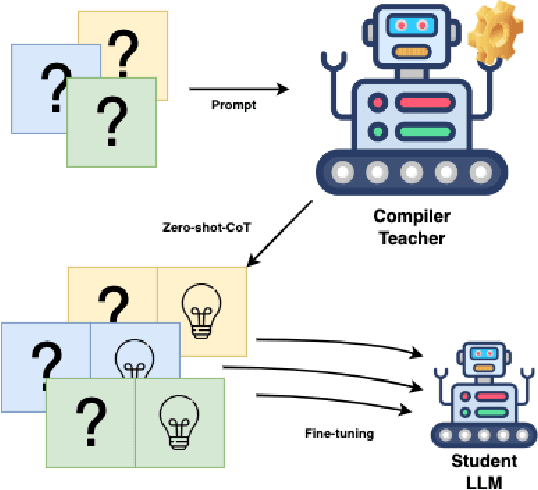
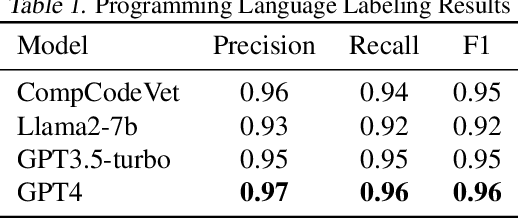

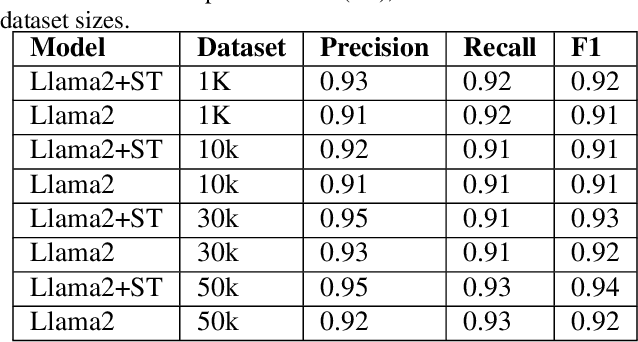
Large language models (LLMs) have become increasingly prominent in academia and industry due to their remarkable performance in diverse applications. As these models evolve with increasing parameters, they excel in tasks like sentiment analysis and machine translation. However, even models with billions of parameters face challenges in tasks demanding multi-step reasoning. Code generation and comprehension, especially in C and C++, emerge as significant challenges. While LLMs trained on code datasets demonstrate competence in many tasks, they struggle with rectifying non-compilable C and C++ code. Our investigation attributes this subpar performance to two primary factors: the quality of the training dataset and the inherent complexity of the problem which demands intricate reasoning. Existing "Chain of Thought" (CoT) prompting techniques aim to enhance multi-step reasoning. This approach, however, retains the limitations associated with the latent drawbacks of LLMs. In this work, we propose CompCodeVet, a compiler-guided CoT approach to produce compilable code from non-compilable ones. Diverging from the conventional approach of utilizing larger LLMs, we employ compilers as a teacher to establish a more robust zero-shot thought process. The evaluation of CompCodeVet on two open-source code datasets shows that CompCodeVet has the ability to improve the training dataset quality for LLMs.
Scope is all you need: Transforming LLMs for HPC Code
Aug 18, 2023



With easier access to powerful compute resources, there is a growing trend in the field of AI for software development to develop larger and larger language models (LLMs) to address a variety of programming tasks. Even LLMs applied to tasks from the high-performance computing (HPC) domain are huge in size (e.g., billions of parameters) and demand expensive compute resources for training. We found this design choice confusing - why do we need large LLMs trained on natural languages and programming languages unrelated to HPC for HPC-specific tasks? In this line of work, we aim to question design choices made by existing LLMs by developing smaller LLMs for specific domains - we call them domain-specific LLMs. Specifically, we start off with HPC as a domain and propose a novel tokenizer named Tokompiler, designed specifically for preprocessing code in HPC and compilation-centric tasks. Tokompiler leverages knowledge of language primitives to generate language-oriented tokens, providing a context-aware understanding of code structure while avoiding human semantics attributed to code structures completely. We applied Tokompiler to pre-train two state-of-the-art models, SPT-Code and Polycoder, for a Fortran code corpus mined from GitHub. We evaluate the performance of these models against the conventional LLMs. Results demonstrate that Tokompiler significantly enhances code completion accuracy and semantic understanding compared to traditional tokenizers in normalized-perplexity tests, down to ~1 perplexity score. This research opens avenues for further advancements in domain-specific LLMs, catering to the unique demands of HPC and compilation tasks.