 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMPIrigen: MPI Code Generation through Domain-Specific Language Models
Feb 14, 2024



The imperative need to scale computation across numerous nodes highlights the significance of efficient parallel computing, particularly in the realm of Message Passing Interface (MPI) integration. The challenging parallel programming task of generating MPI-based parallel programs has remained unexplored. This study first investigates the performance of state-of-the-art language models in generating MPI-based parallel programs. Findings reveal that widely used models such as GPT-3.5 and PolyCoder (specialized multi-lingual code models) exhibit notable performance degradation, when generating MPI-based programs compared to general-purpose programs. In contrast, domain-specific models such as MonoCoder, which are pretrained on MPI-related programming languages of C and C++, outperform larger models. Subsequently, we introduce a dedicated downstream task of MPI-based program generation by fine-tuning MonoCoder on HPCorpusMPI. We call the resulting model as MPIrigen. We propose an innovative preprocessing for completion only after observing the whole code, thus enabling better completion with a wider context. Comparative analysis against GPT-3.5 zero-shot performance, using a novel HPC-oriented evaluation method, demonstrates that MPIrigen excels in generating accurate MPI functions up to 0.8 accuracy in location and function predictions, and with more than 0.9 accuracy for argument predictions. The success of this tailored solution underscores the importance of domain-specific fine-tuning in optimizing language models for parallel computing code generation, paving the way for a new generation of automatic parallelization tools. The sources of this work are available at our GitHub MPIrigen repository: https://github.com/Scientific-Computing-Lab-NRCN/MPI-rigen
Enabling Factor Analysis on Thousand-Subject Neuroimaging Datasets
Aug 18, 2016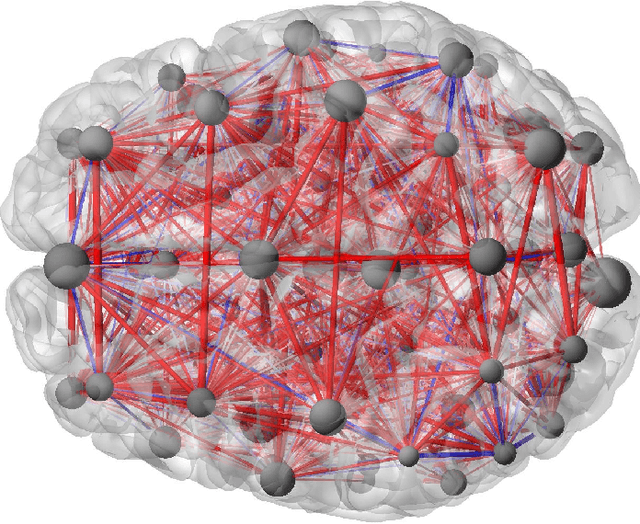
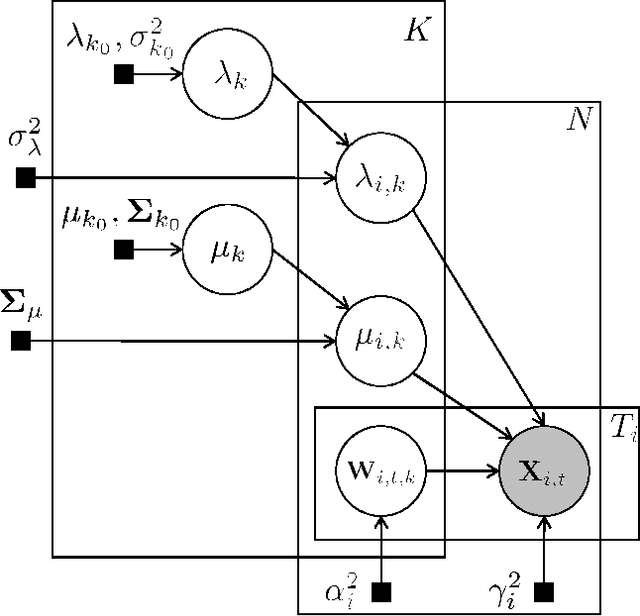
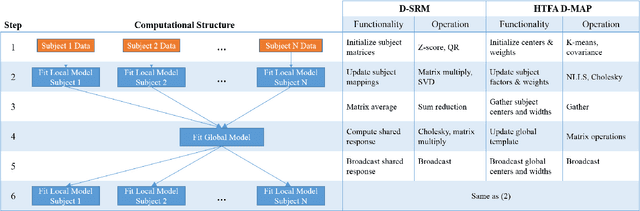
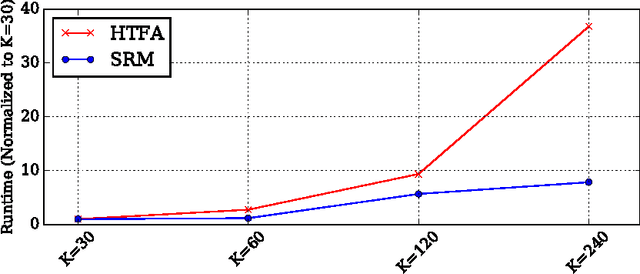
The scale of functional magnetic resonance image data is rapidly increasing as large multi-subject datasets are becoming widely available and high-resolution scanners are adopted. The inherent low-dimensionality of the information in this data has led neuroscientists to consider factor analysis methods to extract and analyze the underlying brain activity. In this work, we consider two recent multi-subject factor analysis methods: the Shared Response Model and Hierarchical Topographic Factor Analysis. We perform analytical, algorithmic, and code optimization to enable multi-node parallel implementations to scale. Single-node improvements result in 99x and 1812x speedups on these two methods, and enables the processing of larger datasets. Our distributed implementations show strong scaling of 3.3x and 5.5x respectively with 20 nodes on real datasets. We also demonstrate weak scaling on a synthetic dataset with 1024 subjects, on up to 1024 nodes and 32,768 cores.