 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIdentifying stimulus-driven neural activity patterns in multi-patient intracranial recordings
Feb 04, 2022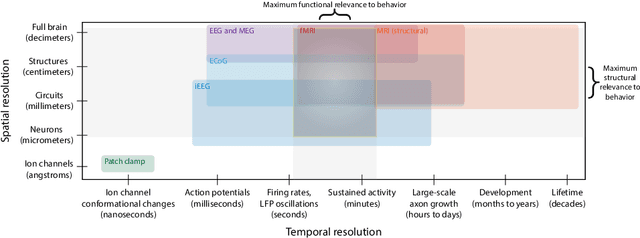
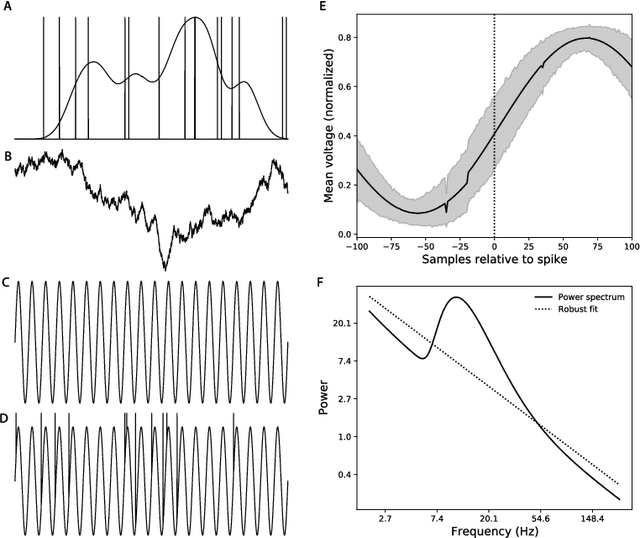
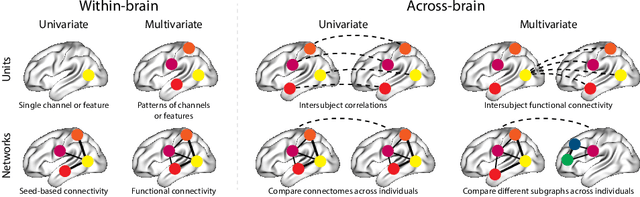
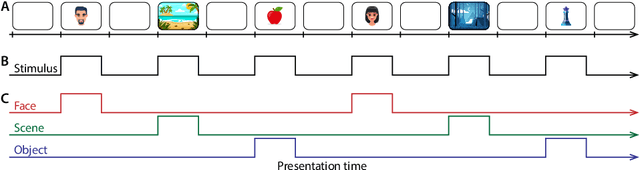
Identifying stimulus-driven neural activity patterns is critical for studying the neural basis of cognition. This can be particularly challenging in intracranial datasets, where electrode locations typically vary across patients. This chapter first presents an overview of the major challenges to identifying stimulus-driven neural activity patterns in the general case. Next, we will review several modality-specific considerations and approaches, along with a discussion of several issues that are particular to intracranial recordings. Against this backdrop, we will consider a variety of within-subject and across-subject approaches to identifying and modeling stimulus-driven neural activity patterns in multi-patient intracranial recordings. These approaches include generalized linear models, multivariate pattern analysis, representational similarity analysis, joint stimulus-activity models, hierarchical matrix factorization models, Gaussian process models, geometric alignment models, inter-subject correlations, and inter-subject functional correlations. Examples from the recent literature serve to illustrate the major concepts and provide the conceptual intuitions for each approach.
Enabling Factor Analysis on Thousand-Subject Neuroimaging Datasets
Aug 18, 2016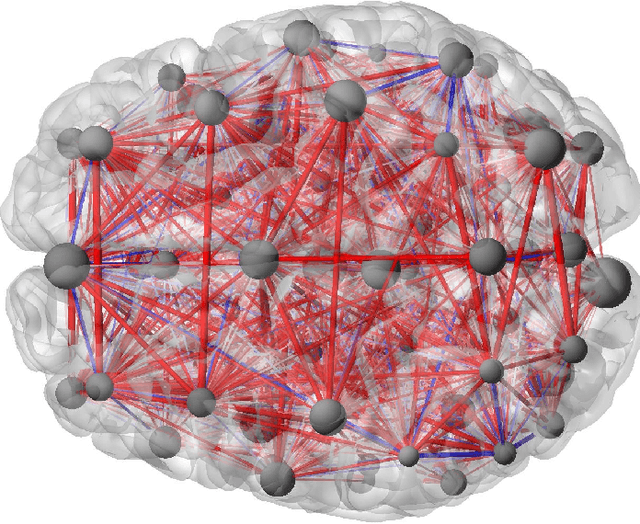
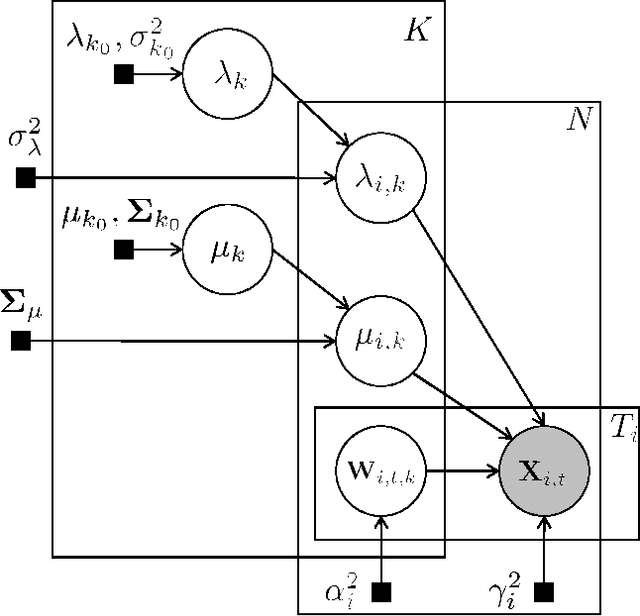
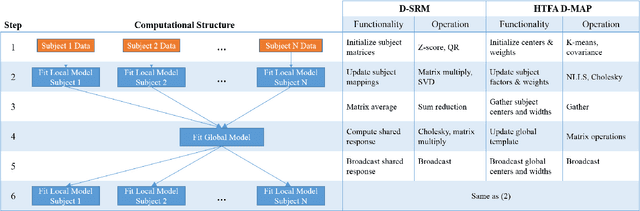
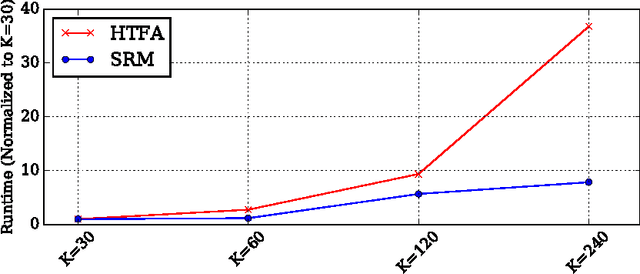
The scale of functional magnetic resonance image data is rapidly increasing as large multi-subject datasets are becoming widely available and high-resolution scanners are adopted. The inherent low-dimensionality of the information in this data has led neuroscientists to consider factor analysis methods to extract and analyze the underlying brain activity. In this work, we consider two recent multi-subject factor analysis methods: the Shared Response Model and Hierarchical Topographic Factor Analysis. We perform analytical, algorithmic, and code optimization to enable multi-node parallel implementations to scale. Single-node improvements result in 99x and 1812x speedups on these two methods, and enables the processing of larger datasets. Our distributed implementations show strong scaling of 3.3x and 5.5x respectively with 20 nodes on real datasets. We also demonstrate weak scaling on a synthetic dataset with 1024 subjects, on up to 1024 nodes and 32,768 cores.