 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGenerative Marginalization Models
Oct 19, 2023We introduce marginalization models (MaMs), a new family of generative models for high-dimensional discrete data. They offer scalable and flexible generative modeling with tractable likelihoods by explicitly modeling all induced marginal distributions. Marginalization models enable fast evaluation of arbitrary marginal probabilities with a single forward pass of the neural network, which overcomes a major limitation of methods with exact marginal inference, such as autoregressive models (ARMs). We propose scalable methods for learning the marginals, grounded in the concept of "marginalization self-consistency". Unlike previous methods, MaMs support scalable training of any-order generative models for high-dimensional problems under the setting of energy-based training, where the goal is to match the learned distribution to a given desired probability (specified by an unnormalized (log) probability function such as energy function or reward function). We demonstrate the effectiveness of the proposed model on a variety of discrete data distributions, including binary images, language, physical systems, and molecules, for maximum likelihood and energy-based training settings. MaMs achieve orders of magnitude speedup in evaluating the marginal probabilities on both settings. For energy-based training tasks, MaMs enable any-order generative modeling of high-dimensional problems beyond the capability of previous methods. Code is at https://github.com/PrincetonLIPS/MaM.
Fast, Smooth, and Safe: Implicit Control Barrier Functions through Reach-Avoid Differential Dynamic Programming
Jul 01, 2023Safety is a central requirement for autonomous system operation across domains. Hamilton-Jacobi (HJ) reachability analysis can be used to construct "least-restrictive" safety filters that result in infrequent, but often extreme, control overrides. In contrast, control barrier function (CBF) methods apply smooth control corrections to guard the system against an often conservative safety boundary. This paper provides an online scheme to construct an implicit CBF through HJ reach-avoid differential dynamic programming in a receding-horizon framework, enabling smooth safety filtering with infinite-time safety guarantees. Simulations with the Dubins car and 5D bicycle dynamics demonstrate the scheme's ability to preserve safety smoothly without the conservativeness of handcrafted CBFs.
Latent Positional Information is in the Self-Attention Variance of Transformer Language Models Without Positional Embeddings
May 23, 2023



The use of positional embeddings in transformer language models is widely accepted. However, recent research has called into question the necessity of such embeddings. We further extend this inquiry by demonstrating that a randomly initialized and frozen transformer language model, devoid of positional embeddings, inherently encodes strong positional information through the shrinkage of self-attention variance. To quantify this variance, we derive the underlying distribution of each step within a transformer layer. Through empirical validation using a fully pretrained model, we show that the variance shrinkage effect still persists after extensive gradient updates. Our findings serve to justify the decision to discard positional embeddings and thus facilitate more efficient pretraining of transformer language models.
Transformer Working Memory Enables Regular Language Reasoning and Natural Language Length Extrapolation
May 05, 2023



Unlike recurrent models, conventional wisdom has it that Transformers cannot perfectly model regular languages. Inspired by the notion of working memory, we propose a new Transformer variant named RegularGPT. With its novel combination of Weight-Sharing, Adaptive-Depth, and Sliding-Dilated-Attention, RegularGPT constructs working memory along the depth dimension, thereby enabling efficient and successful modeling of regular languages such as PARITY. We further test RegularGPT on the task of natural language length extrapolation and surprisingly find that it rediscovers the local windowed attention effect deemed necessary in prior work for length extrapolation.
Training Discrete Deep Generative Models via Gapped Straight-Through Estimator
Jun 15, 2022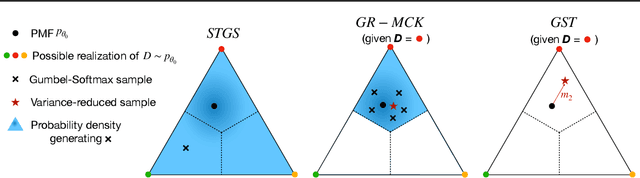
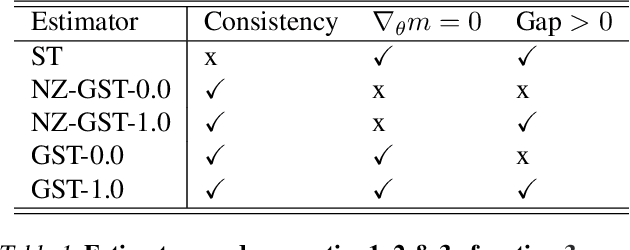
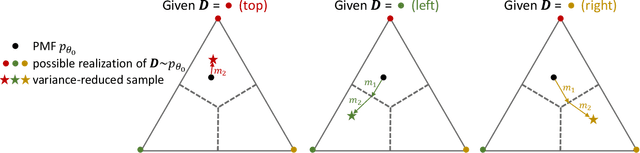
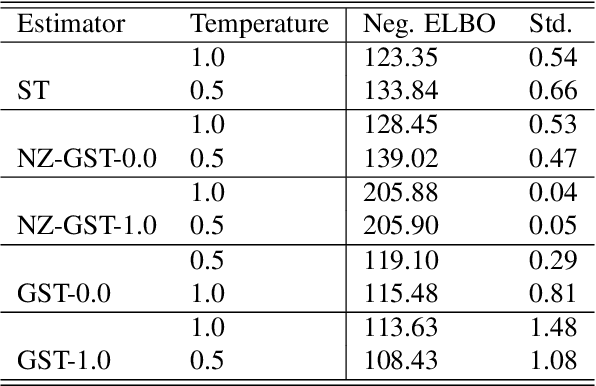
While deep generative models have succeeded in image processing, natural language processing, and reinforcement learning, training that involves discrete random variables remains challenging due to the high variance of its gradient estimation process. Monte Carlo is a common solution used in most variance reduction approaches. However, this involves time-consuming resampling and multiple function evaluations. We propose a Gapped Straight-Through (GST) estimator to reduce the variance without incurring resampling overhead. This estimator is inspired by the essential properties of Straight-Through Gumbel-Softmax. We determine these properties and show via an ablation study that they are essential. Experiments demonstrate that the proposed GST estimator enjoys better performance compared to strong baselines on two discrete deep generative modeling tasks, MNIST-VAE and ListOps.
KERPLE: Kernelized Relative Positional Embedding for Length Extrapolation
May 20, 2022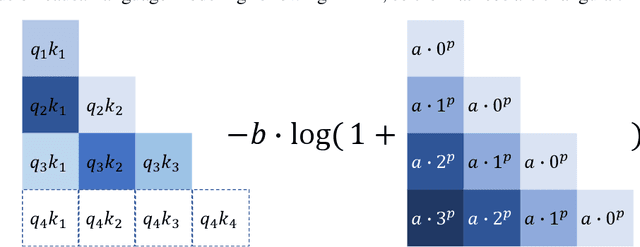
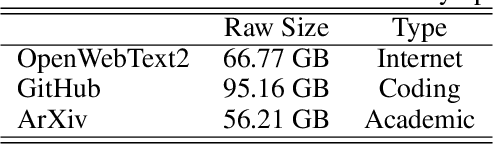

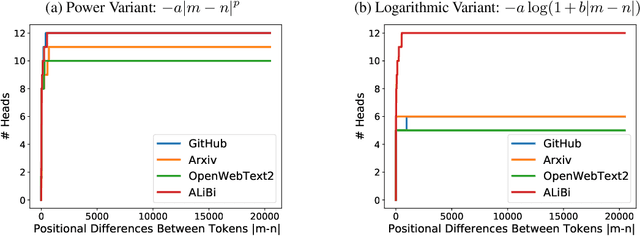
Relative positional embeddings (RPE) have received considerable attention since RPEs effectively model the relative distance among tokens and enable length extrapolation. We propose KERPLE, a framework that generalizes relative position embedding for extrapolation by kernelizing positional differences. We achieve this goal using conditionally positive definite (CPD) kernels, a class of functions known for generalizing distance metrics. To maintain the inner product interpretation of self-attention, we show that a CPD kernel can be transformed into a PD kernel by adding a constant offset. This offset is implicitly absorbed in the Softmax normalization during self-attention. The diversity of CPD kernels allows us to derive various RPEs that enable length extrapolation in a principled way. Experiments demonstrate that the logarithmic variant achieves excellent extrapolation performance on three large language modeling datasets.
ProBF: Learning Probabilistic Safety Certificates with Barrier Functions
Dec 24, 2021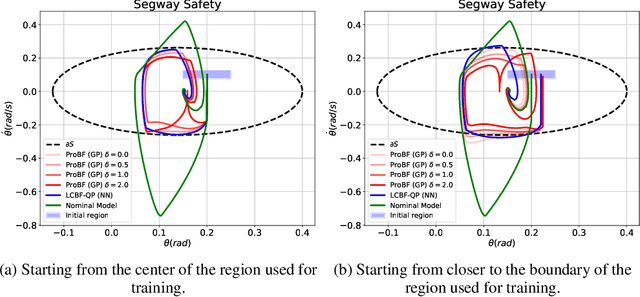
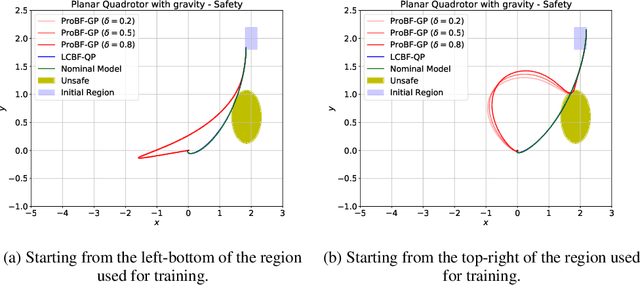
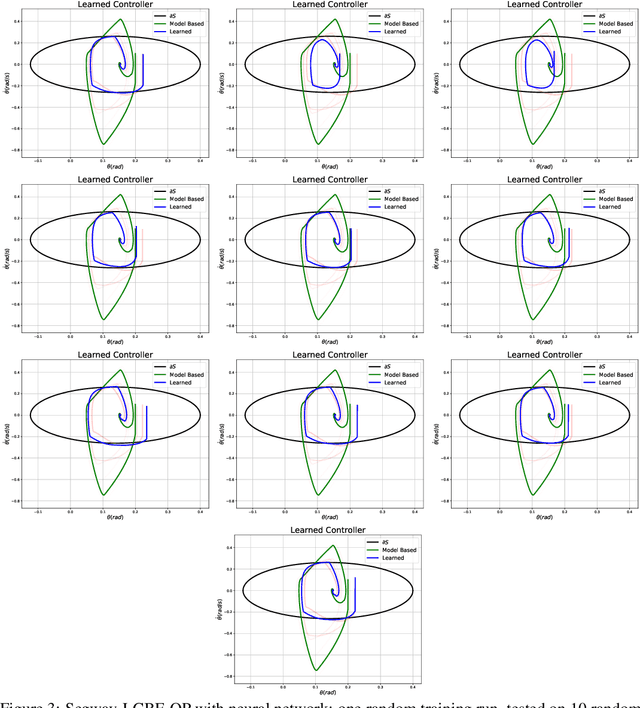
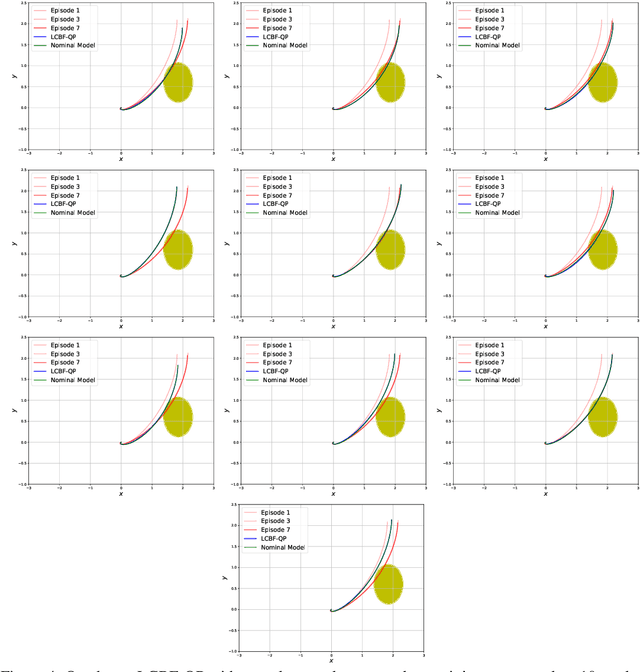
Safety-critical applications require controllers/policies that can guarantee safety with high confidence. The control barrier function is a useful tool to guarantee safety if we have access to the ground-truth system dynamics. In practice, we have inaccurate knowledge of the system dynamics, which can lead to unsafe behaviors due to unmodeled residual dynamics. Learning the residual dynamics with deterministic machine learning models can prevent the unsafe behavior but can fail when the predictions are imperfect. In this situation, a probabilistic learning method that reasons about the uncertainty of its predictions can help provide robust safety margins. In this work, we use a Gaussian process to model the projection of the residual dynamics onto a control barrier function. We propose a novel optimization procedure to generate safe controls that can guarantee safety with high probability. The safety filter is provided with the ability to reason about the uncertainty of the predictions from the GP. We show the efficacy of this method through experiments on Segway and Quadrotor simulations. Our proposed probabilistic approach is able to reduce the number of safety violations significantly as compared to the deterministic approach with a neural network.
Explaining Off-Policy Actor-Critic From A Bias-Variance Perspective
Oct 06, 2021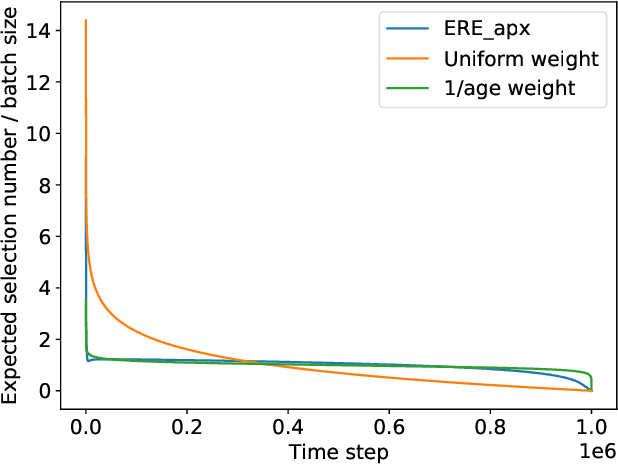
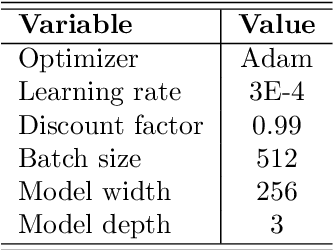
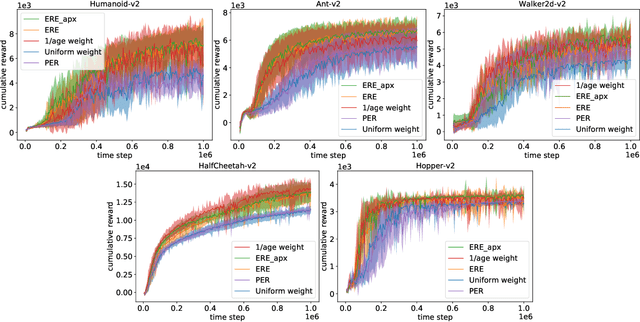

Off-policy Actor-Critic algorithms have demonstrated phenomenal experimental performance but still require better explanations. To this end, we show its policy evaluation error on the distribution of transitions decomposes into: a Bellman error, a bias from policy mismatch, and a variance term from sampling. By comparing the magnitude of bias and variance, we explain the success of the Emphasizing Recent Experience sampling and 1/age weighted sampling. Both sampling strategies yield smaller bias and variance and are hence preferable to uniform sampling.
DiffLoop: Tuning PID controllers by differentiating through the feedback loop
Jun 19, 2021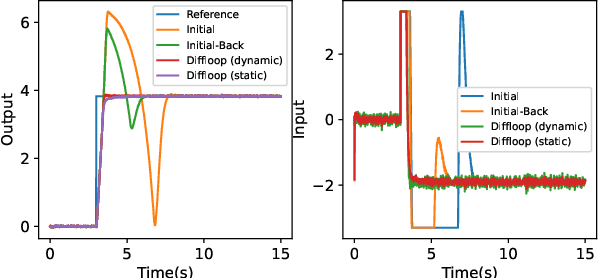
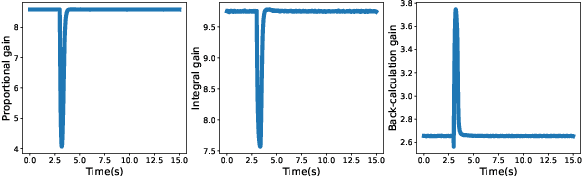
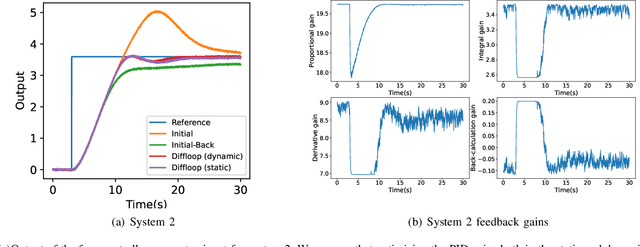
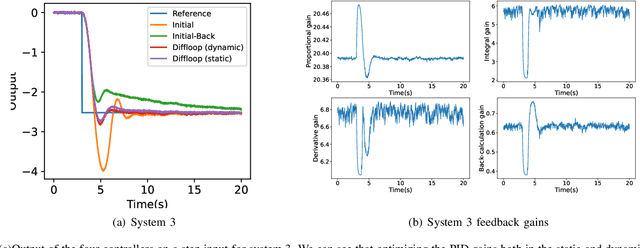
Since most industrial control applications use PID controllers, PID tuning and anti-windup measures are significant problems. This paper investigates tuning the feedback gains of a PID controller via back-calculation and automatic differentiation tools. In particular, we episodically use a cost function to generate gradients and perform gradient descent to improve controller performance. We provide a theoretical framework for analyzing this non-convex optimization and establish a relationship between back-calculation and disturbance feedback policies. We include numerical experiments on linear systems with actuator saturation to show the efficacy of this approach.
Safe Reinforcement Learning with Natural Language Constraints
Oct 11, 2020
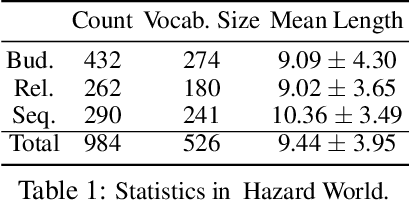
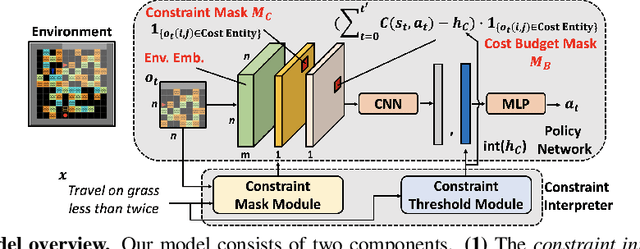
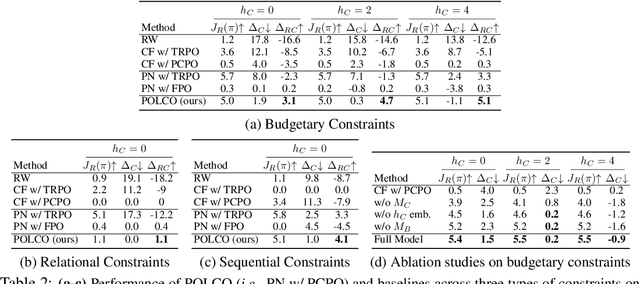
In this paper, we tackle the problem of learning control policies for tasks when provided with constraints in natural language. In contrast to instruction following, language here is used not to specify goals, but rather to describe situations that an agent must avoid during its exploration of the environment. Specifying constraints in natural language also differs from the predominant paradigm in safe reinforcement learning, where safety criteria are enforced by hand-defined cost functions. While natural language allows for easy and flexible specification of safety constraints and budget limitations, its ambiguous nature presents a challenge when mapping these specifications into representations that can be used by techniques for safe reinforcement learning. To address this, we develop a model that contains two components: (1) a constraint interpreter to encode natural language constraints into vector representations capturing spatial and temporal information on forbidden states, and (2) a policy network that uses these representations to output a policy with minimal constraint violations. Our model is end-to-end differentiable and we train it using a recently proposed algorithm for constrained policy optimization. To empirically demonstrate the effectiveness of our approach, we create a new benchmark task for autonomous navigation with crowd-sourced free-form text specifying three different types of constraints. Our method outperforms several baselines by achieving 6-7 times higher returns and 76% fewer constraint violations on average. Dataset and code to reproduce our experiments are available at https://sites.google.com/view/polco-hazard-world/.