Get our free extension to see links to code for papers anywhere online!Free add-on: code for papers everywhere!Free add-on: See code for papers anywhere!
 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeExplaining Off-Policy Actor-Critic From A Bias-Variance Perspective
Paper and Code
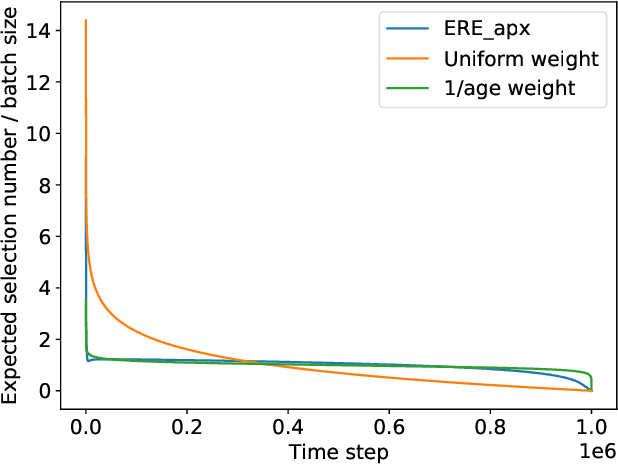
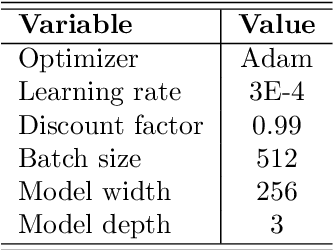
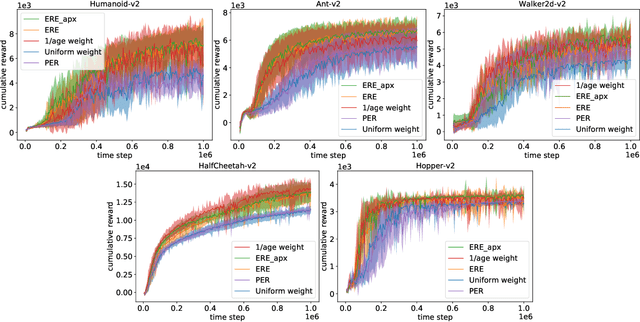

Off-policy Actor-Critic algorithms have demonstrated phenomenal experimental performance but still require better explanations. To this end, we show its policy evaluation error on the distribution of transitions decomposes into: a Bellman error, a bias from policy mismatch, and a variance term from sampling. By comparing the magnitude of bias and variance, we explain the success of the Emphasizing Recent Experience sampling and 1/age weighted sampling. Both sampling strategies yield smaller bias and variance and are hence preferable to uniform sampling.
View paper on
 OpenReview
OpenReview