 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGameplay Filters: Safe Robot Walking through Adversarial Imagination
May 01, 2024
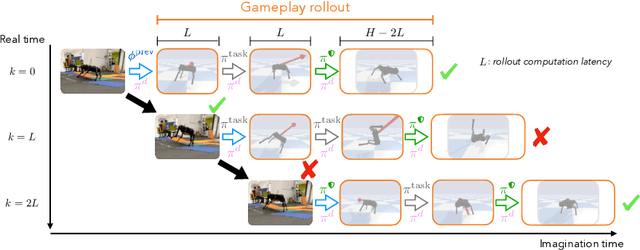
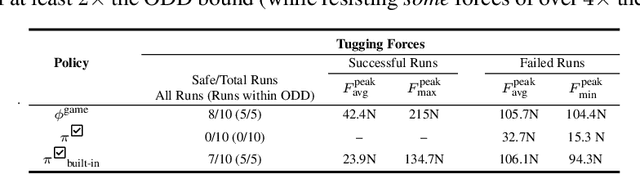
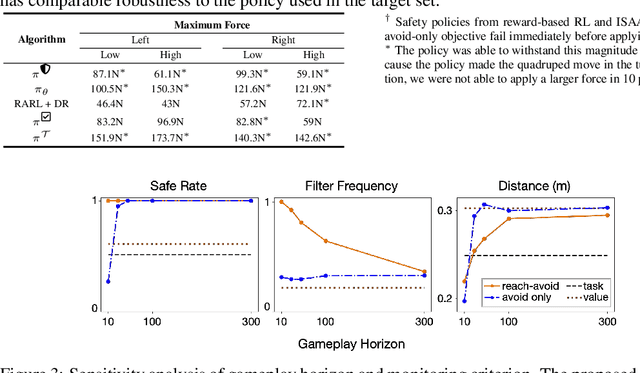
Ensuring the safe operation of legged robots in uncertain, novel environments is crucial to their widespread adoption. Despite recent advances in safety filters that can keep arbitrary task-driven policies from incurring safety failures, existing solutions for legged robot locomotion still rely on simplified dynamics and may fail when the robot is perturbed away from predefined stable gaits. This paper presents a general approach that leverages offline game-theoretic reinforcement learning to synthesize a highly robust safety filter for high-order nonlinear dynamics. This gameplay filter then maintains runtime safety by continually simulating adversarial futures and precluding task-driven actions that would cause it to lose future games (and thereby violate safety). Validated on a 36-dimensional quadruped robot locomotion task, the gameplay safety filter exhibits inherent robustness to the sim-to-real gap without manual tuning or heuristic designs. Physical experiments demonstrate the effectiveness of the gameplay safety filter under perturbations, such as tugging and unmodeled irregular terrains, while simulation studies shed light on how to trade off computation and conservativeness without compromising safety.
The Safety Filter: A Unified View of Safety-Critical Control in Autonomous Systems
Sep 11, 2023



Recent years have seen significant progress in the realm of robot autonomy, accompanied by the expanding reach of robotic technologies. However, the emergence of new deployment domains brings unprecedented challenges in ensuring safe operation of these systems, which remains as crucial as ever. While traditional model-based safe control methods struggle with generalizability and scalability, emerging data-driven approaches tend to lack well-understood guarantees, which can result in unpredictable catastrophic failures. Successful deployment of the next generation of autonomous robots will require integrating the strengths of both paradigms. This article provides a review of safety filter approaches, highlighting important connections between existing techniques and proposing a unified technical framework to understand, compare, and combine them. The new unified view exposes a shared modular structure across a range of seemingly disparate safety filter classes and naturally suggests directions for future progress towards more scalable synthesis, robust monitoring, and efficient intervention.
Fast, Smooth, and Safe: Implicit Control Barrier Functions through Reach-Avoid Differential Dynamic Programming
Jul 01, 2023Safety is a central requirement for autonomous system operation across domains. Hamilton-Jacobi (HJ) reachability analysis can be used to construct "least-restrictive" safety filters that result in infrequent, but often extreme, control overrides. In contrast, control barrier function (CBF) methods apply smooth control corrections to guard the system against an often conservative safety boundary. This paper provides an online scheme to construct an implicit CBF through HJ reach-avoid differential dynamic programming in a receding-horizon framework, enabling smooth safety filtering with infinite-time safety guarantees. Simulations with the Dubins car and 5D bicycle dynamics demonstrate the scheme's ability to preserve safety smoothly without the conservativeness of handcrafted CBFs.
Emergent Coordination through Game-Induced Nonlinear Opinion Dynamics
Apr 05, 2023



We present a multi-agent decision-making framework for the emergent coordination of autonomous agents whose intents are initially undecided. Dynamic non-cooperative games have been used to encode multi-agent interaction, but ambiguity arising from factors such as goal preference or the presence of multiple equilibria may lead to coordination issues, ranging from the "freezing robot" problem to unsafe behavior in safety-critical events. The recently developed nonlinear opinion dynamics (NOD) provide guarantees for breaking deadlocks. However, choosing the appropriate model parameters automatically in general multi-agent settings remains a challenge. In this paper, we first propose a novel and principled procedure for synthesizing NOD based on the value functions of dynamic games conditioned on agents' intents. In particular, we provide for the two-player two-option case precise stability conditions for equilibria of the game-induced NOD based on the mismatch between agents' opinions and their game values. We then propose an optimization-based trajectory optimization algorithm that computes agents' policies guided by the evolution of opinions. The efficacy of our method is illustrated with a simulated toll station coordination example.
ISAACS: Iterative Soft Adversarial Actor-Critic for Safety
Dec 06, 2022

The deployment of robots in uncontrolled environments requires them to operate robustly under previously unseen scenarios, like irregular terrain and wind conditions. Unfortunately, while rigorous safety frameworks from robust optimal control theory scale poorly to high-dimensional nonlinear dynamics, control policies computed by more tractable "deep" methods lack guarantees and tend to exhibit little robustness to uncertain operating conditions. This work introduces a novel approach enabling scalable synthesis of robust safety-preserving controllers for robotic systems with general nonlinear dynamics subject to bounded modeling error by combining game-theoretic safety analysis with adversarial reinforcement learning in simulation. Following a soft actor-critic scheme, a safety-seeking fallback policy is co-trained with an adversarial "disturbance" agent that aims to invoke the worst-case realization of model error and training-to-deployment discrepancy allowed by the designer's uncertainty. While the learned control policy does not intrinsically guarantee safety, it is used to construct a real-time safety filter (or shield) with robust safety guarantees based on forward reachability rollouts. This shield can be used in conjunction with a safety-agnostic control policy, precluding any task-driven actions that could result in loss of safety. We evaluate our learning-based safety approach in a 5D race car simulator, compare the learned safety policy to the numerically obtained optimal solution, and empirically validate the robust safety guarantee of our proposed safety shield against worst-case model discrepancy.
A Real Time Super Resolution Accelerator with Tilted Layer Fusion
May 09, 2022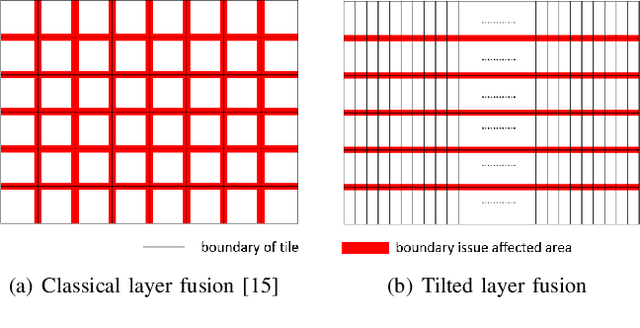
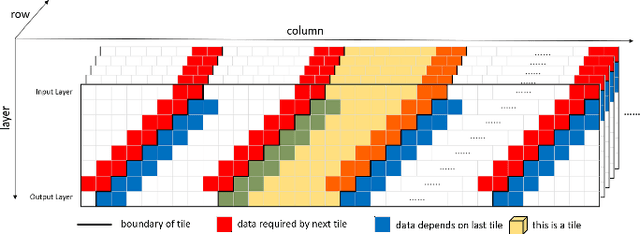
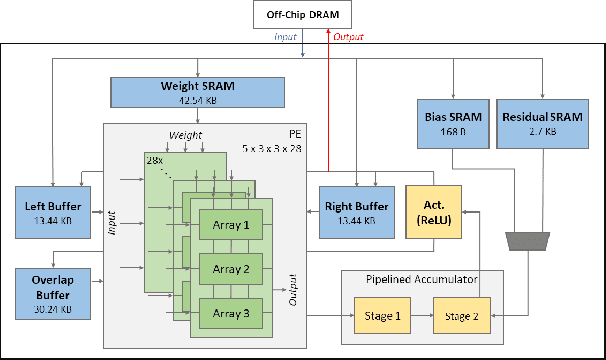
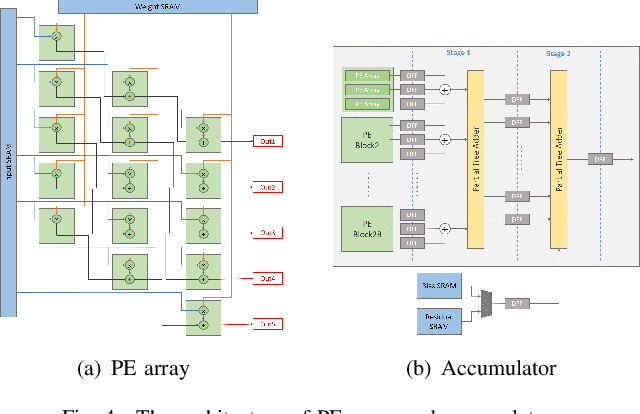
Deep learning based superresolution achieves high-quality results, but its heavy computational workload, large buffer, and high external memory bandwidth inhibit its usage in mobile devices. To solve the above issues, this paper proposes a real-time hardware accelerator with the tilted layer fusion method that reduces the external DRAM bandwidth by 92\% and just needs 102KB on-chip memory. The design implemented with a 40nm CMOS process achieves 1920x1080@60fps throughput with 544.3K gate count when running at 600MHz; it has higher throughput and lower area cost than previous designs.
Sim-to-Lab-to-Real: Safe Reinforcement Learning with Shielding and Generalization Guarantees
Feb 10, 2022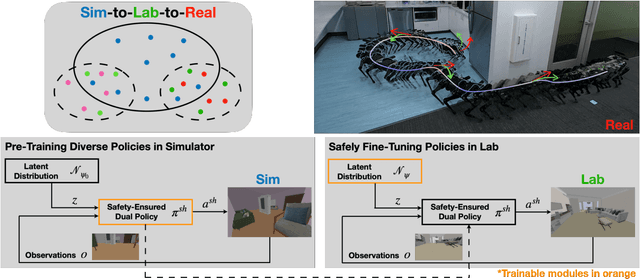


Safety is a critical component of autonomous systems and remains a challenge for learning-based policies to be utilized in the real world. In particular, policies learned using reinforcement learning often fail to generalize to novel environments due to unsafe behavior. In this paper, we propose Sim-to-Lab-to-Real to safely close the reality gap. To improve safety, we apply a dual policy setup where a performance policy is trained using the cumulative task reward and a backup (safety) policy is trained by solving the reach-avoid Bellman Equation based on Hamilton-Jacobi reachability analysis. In Sim-to-Lab transfer, we apply a supervisory control scheme to shield unsafe actions during exploration; in Lab-to-Real transfer, we leverage the Probably Approximately Correct (PAC)-Bayes framework to provide lower bounds on the expected performance and safety of policies in unseen environments. We empirically study the proposed framework for ego-vision navigation in two types of indoor environments including a photo-realistic one. We also demonstrate strong generalization performance through hardware experiments in real indoor spaces with a quadrupedal robot. See https://sites.google.com/princeton.edu/sim-to-lab-to-real for supplementary material.
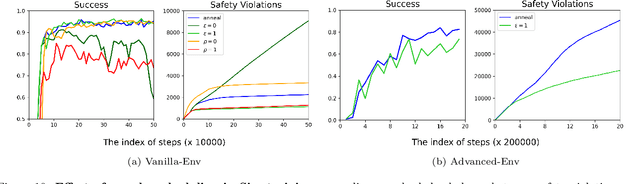
Safety and Liveness Guarantees through Reach-Avoid Reinforcement Learning
Dec 23, 2021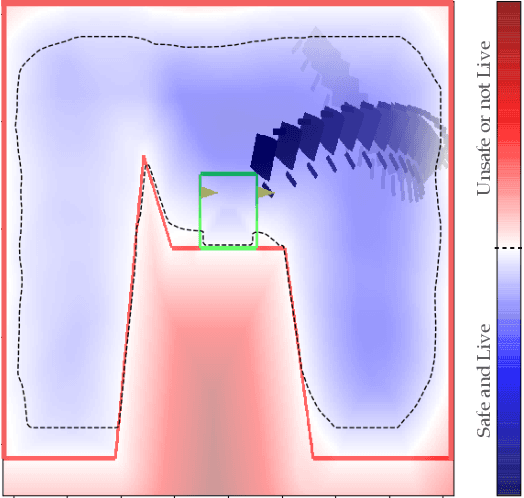
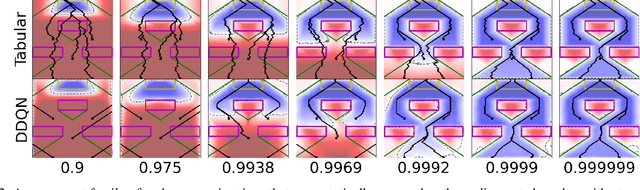
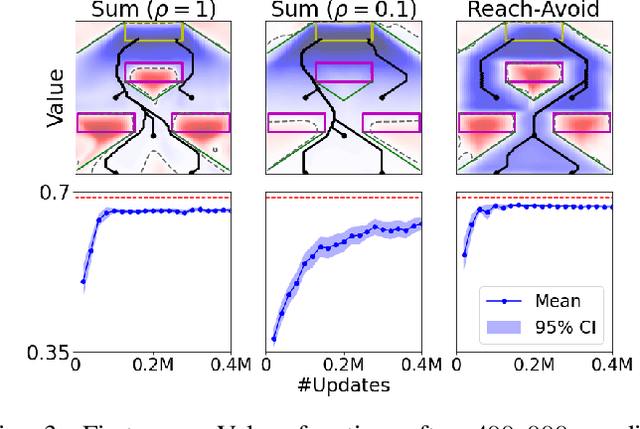
Reach-avoid optimal control problems, in which the system must reach certain goal conditions while staying clear of unacceptable failure modes, are central to safety and liveness assurance for autonomous robotic systems, but their exact solutions are intractable for complex dynamics and environments. Recent successes in reinforcement learning methods to approximately solve optimal control problems with performance objectives make their application to certification problems attractive; however, the Lagrange-type objective used in reinforcement learning is not suitable to encode temporal logic requirements. Recent work has shown promise in extending the reinforcement learning machinery to safety-type problems, whose objective is not a sum, but a minimum (or maximum) over time. In this work, we generalize the reinforcement learning formulation to handle all optimal control problems in the reach-avoid category. We derive a time-discounted reach-avoid Bellman backup with contraction mapping properties and prove that the resulting reach-avoid Q-learning algorithm converges under analogous conditions to the traditional Lagrange-type problem, yielding an arbitrarily tight conservative approximation to the reach-avoid set. We further demonstrate the use of this formulation with deep reinforcement learning methods, retaining zero-violation guarantees by treating the approximate solutions as untrusted oracles in a model-predictive supervisory control framework. We evaluate our proposed framework on a range of nonlinear systems, validating the results against analytic and numerical solutions, and through Monte Carlo simulation in previously intractable problems. Our results open the door to a range of learning-based methods for safe-and-live autonomous behavior, with applications across robotics and automation. See https://github.com/SafeRoboticsLab/safety_rl for code and supplementary material.