 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeUncertainty-aware Latent Safety Filters for Avoiding Out-of-Distribution Failures
May 01, 2025Recent advances in generative world models have enabled classical safe control methods, such as Hamilton-Jacobi (HJ) reachability, to generalize to complex robotic systems operating directly from high-dimensional sensor observations. However, obtaining comprehensive coverage of all safety-critical scenarios during world model training is extremely challenging. As a result, latent safety filters built on top of these models may miss novel hazards and even fail to prevent known ones, overconfidently misclassifying risky out-of-distribution (OOD) situations as safe. To address this, we introduce an uncertainty-aware latent safety filter that proactively steers robots away from both known and unseen failures. Our key idea is to use the world model's epistemic uncertainty as a proxy for identifying unseen potential hazards. We propose a principled method to detect OOD world model predictions by calibrating an uncertainty threshold via conformal prediction. By performing reachability analysis in an augmented state space-spanning both the latent representation and the epistemic uncertainty-we synthesize a latent safety filter that can reliably safeguard arbitrary policies from both known and unseen safety hazards. In simulation and hardware experiments on vision-based control tasks with a Franka manipulator, we show that our uncertainty-aware safety filter preemptively detects potential unsafe scenarios and reliably proposes safe, in-distribution actions. Video results can be found on the project website at https://cmu-intentlab.github.io/UNISafe
Generalizing Safety Beyond Collision-Avoidance via Latent-Space Reachability Analysis
Feb 02, 2025Hamilton-Jacobi (HJ) reachability is a rigorous mathematical framework that enables robots to simultaneously detect unsafe states and generate actions that prevent future failures. While in theory, HJ reachability can synthesize safe controllers for nonlinear systems and nonconvex constraints, in practice, it has been limited to hand-engineered collision-avoidance constraints modeled via low-dimensional state-space representations and first-principles dynamics. In this work, our goal is to generalize safe robot controllers to prevent failures that are hard -- if not impossible -- to write down by hand, but can be intuitively identified from high-dimensional observations: for example, spilling the contents of a bag. We propose Latent Safety Filters, a latent-space generalization of HJ reachability that tractably operates directly on raw observation data (e.g., RGB images) by performing safety analysis in the latent embedding space of a generative world model. This transforms nuanced constraint specification to a classification problem in latent space and enables reasoning about dynamical consequences that are hard to simulate. In simulation and hardware experiments, we use Latent Safety Filters to safeguard arbitrary policies (from generative policies to direct teleoperation) from complex safety hazards, like preventing a Franka Research 3 manipulator from spilling the contents of a bag or toppling cluttered objects.
A General Calibrated Regret Metric for Detecting and Mitigating Human-Robot Interaction Failures
Mar 07, 2024



Robot decision-making increasingly relies on expressive data-driven human prediction models when operating around people. While these models are known to suffer from prediction errors in out-of-distribution interactions, not all prediction errors equally impact downstream robot performance. We identify that the mathematical notion of regret precisely characterizes the degree to which incorrect predictions of future interaction outcomes degraded closed-loop robot performance. However, canonical regret measures are poorly calibrated across diverse deployment interactions. We extend the canonical notion of regret by deriving a calibrated regret metric that generalizes from absolute reward space to probability space. With this transformation, our metric removes the need for explicit reward functions to calculate the robot's regret, enables fairer comparison of interaction anomalies across disparate deployment contexts, and facilitates targetted dataset construction of "system-level" prediction failures. We experimentally quantify the value of this high-regret interaction data for aiding the robot in improving its downstream decision-making. In a suite of closed-loop autonomous driving simulations, we find that fine-tuning ego-conditioned behavior predictors exclusively on high-regret human-robot interaction data can improve the robot's overall re-deployment performance with significantly (77%) less data.
Learning-Aware Safety for Interactive Autonomy
Sep 03, 2023



One of the outstanding challenges for the widespread deployment of robotic systems like autonomous vehicles is ensuring safe interaction with humans without sacrificing efficiency. Existing safety analysis methods often neglect the robot's ability to learn and adapt at runtime, leading to overly conservative behavior. This paper proposes a new closed-loop paradigm for synthesizing safe control policies that explicitly account for the system's evolving uncertainty under possible future scenarios. The formulation reasons jointly about the physical dynamics and the robot's learning algorithm, which updates its internal belief over time. We leverage adversarial deep reinforcement learning (RL) for scaling to high dimensions, enabling tractable safety analysis even for implicit learning dynamics induced by state-of-the-art prediction models. We demonstrate our framework's ability to work with both Bayesian belief propagation and the implicit learning induced by a large pre-trained neural trajectory predictor.
Emergent Coordination through Game-Induced Nonlinear Opinion Dynamics
Apr 05, 2023



We present a multi-agent decision-making framework for the emergent coordination of autonomous agents whose intents are initially undecided. Dynamic non-cooperative games have been used to encode multi-agent interaction, but ambiguity arising from factors such as goal preference or the presence of multiple equilibria may lead to coordination issues, ranging from the "freezing robot" problem to unsafe behavior in safety-critical events. The recently developed nonlinear opinion dynamics (NOD) provide guarantees for breaking deadlocks. However, choosing the appropriate model parameters automatically in general multi-agent settings remains a challenge. In this paper, we first propose a novel and principled procedure for synthesizing NOD based on the value functions of dynamic games conditioned on agents' intents. In particular, we provide for the two-player two-option case precise stability conditions for equilibria of the game-induced NOD based on the mismatch between agents' opinions and their game values. We then propose an optimization-based trajectory optimization algorithm that computes agents' policies guided by the evolution of opinions. The efficacy of our method is illustrated with a simulated toll station coordination example.
Online Update of Safety Assurances Using Confidence-Based Predictions
Oct 03, 2022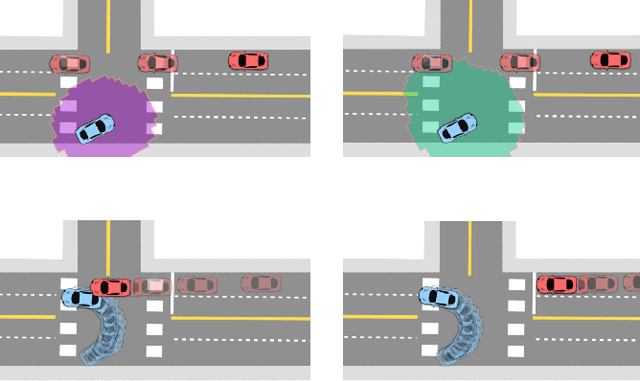
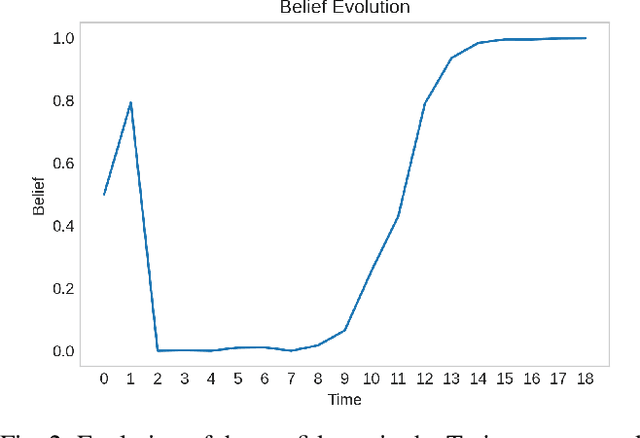
Robots such as autonomous vehicles and assistive manipulators are increasingly operating in dynamic environments and close physical proximity to people. In such scenarios, the robot can leverage a human motion predictor to predict their future states and plan safe and efficient trajectories. However, no model is ever perfect -- when the observed human behavior deviates from the model predictions, the robot might plan unsafe maneuvers. Recent works have explored maintaining a confidence parameter in the human model to overcome this challenge, wherein the predicted human actions are tempered online based on the likelihood of the observed human action under the prediction model. This has opened up a new research challenge, i.e., \textit{how to compute the future human states online as the confidence parameter changes?} In this work, we propose a Hamilton-Jacobi (HJ) reachability-based approach to overcome this challenge. Treating the confidence parameter as a virtual state in the system, we compute a parameter-conditioned forward reachable tube (FRT) that provides the future human states as a function of the confidence parameter. Online, as the confidence parameter changes, we can simply query the corresponding FRT, and use it to update the robot plan. Computing parameter-conditioned FRT corresponds to an (offline) high-dimensional reachability problem, which we solve by leveraging recent advances in data-driven reachability analysis. Overall, our framework enables online maintenance and updates of safety assurances in human-robot interaction scenarios, even when the human prediction model is incorrect. We demonstrate our approach in several safety-critical autonomous driving scenarios, involving a state-of-the-art deep learning-based prediction model.
Parameter-Conditioned Reachable Sets for Updating Safety Assurances Online
Sep 29, 2022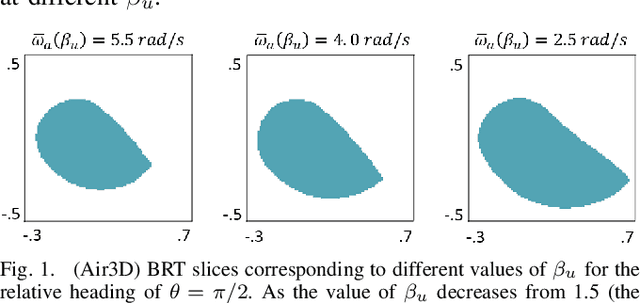
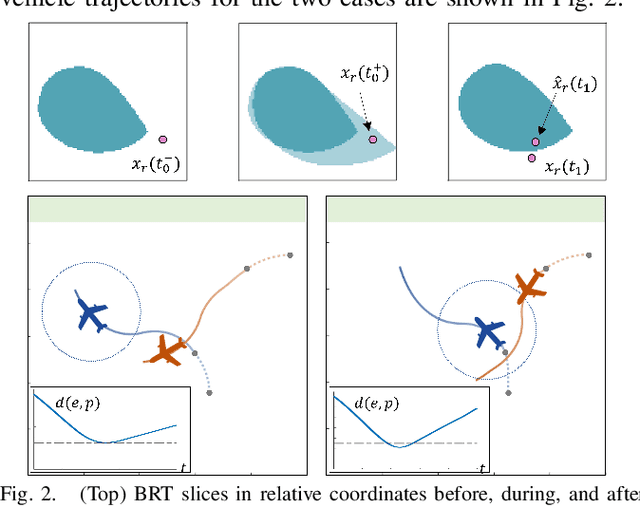
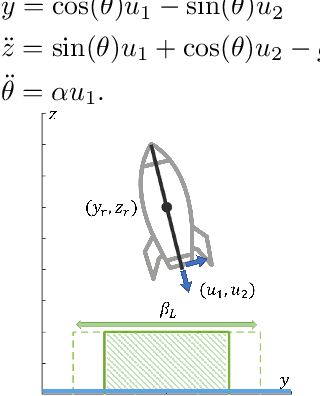
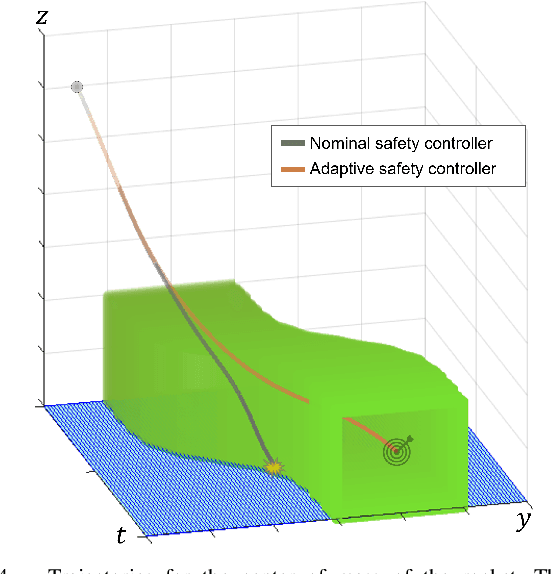
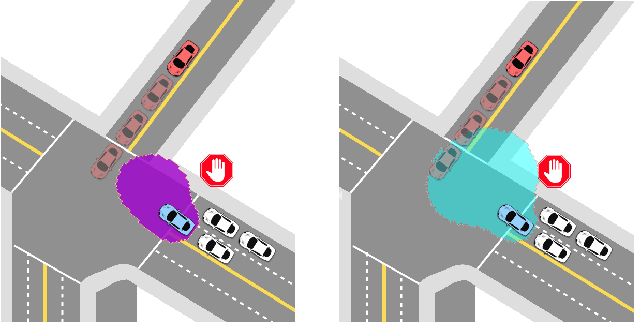
Hamilton-Jacobi (HJ) reachability analysis is a powerful tool for analyzing the safety of autonomous systems. However, the provided safety assurances are often predicated on the assumption that once deployed, the system or its environment does not evolve. Online, however, an autonomous system might experience changes in system dynamics, control authority, external disturbances, and/or the surrounding environment, requiring updated safety assurances. Rather than restarting the safety analysis from scratch, which can be time-consuming and often intractable to perform online, we propose to compute \textit{parameter-conditioned} reachable sets. Assuming expected system and environment changes can be parameterized, we treat these parameters as virtual states in the system and leverage recent advances in high-dimensional reachability analysis to solve the corresponding reachability problem offline. This results in a family of reachable sets that is parameterized by the environment and system factors. Online, as these factors change, the system can simply query the corresponding safety function from this family to ensure system safety, enabling a real-time update of the safety assurances. Through various simulation studies, we demonstrate the capability of our approach in maintaining system safety despite the system and environment evolution.
Decentralized Learning With Limited Communications for Multi-robot Coverage of Unknown Spatial Fields
Aug 03, 2022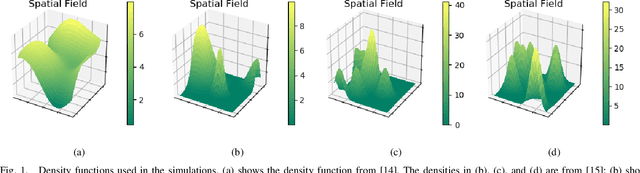

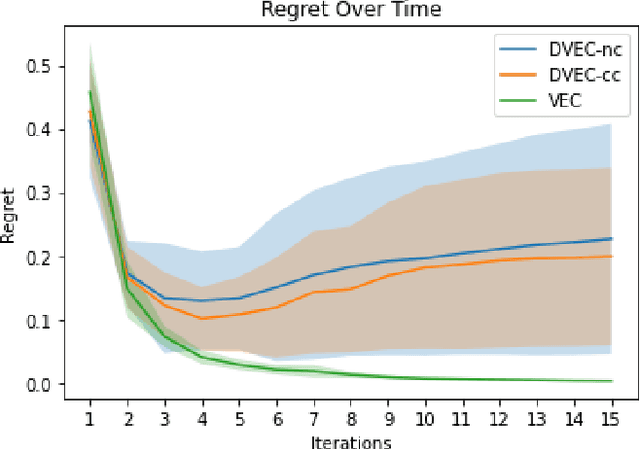
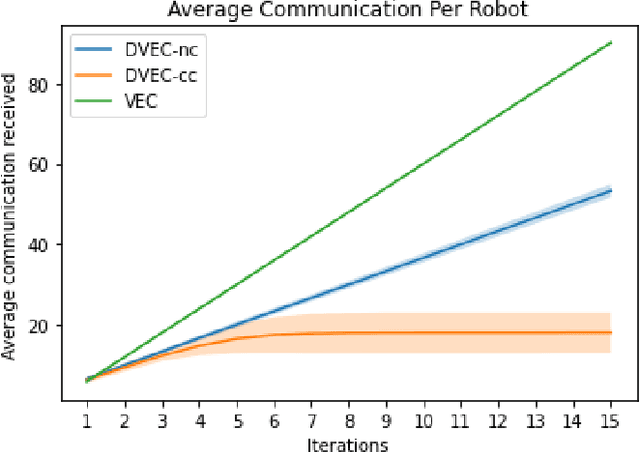
This paper presents an algorithm for a team of mobile robots to simultaneously learn a spatial field over a domain and spatially distribute themselves to optimally cover it. Drawing from previous approaches that estimate the spatial field through a centralized Gaussian process, this work leverages the spatial structure of the coverage problem and presents a decentralized strategy where samples are aggregated locally by establishing communications through the boundaries of a Voronoi partition. We present an algorithm whereby each robot runs a local Gaussian process calculated from its own measurements and those provided by its Voronoi neighbors, which are incorporated into the individual robot's Gaussian process only if they provide sufficiently novel information. The performance of the algorithm is evaluated in simulation and compared with centralized approaches.
SHARP: Shielding-Aware Robust Planning for Safe and Efficient Human-Robot Interaction
Oct 02, 2021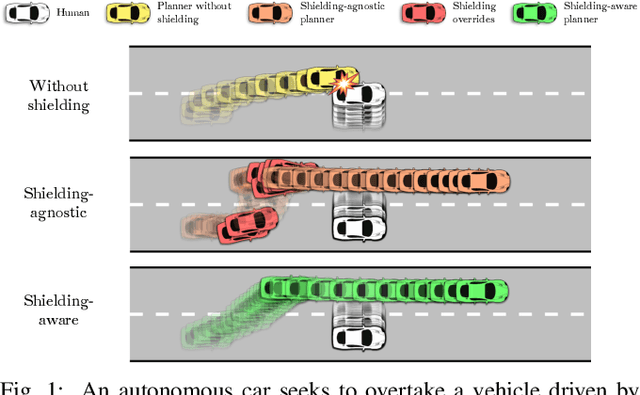
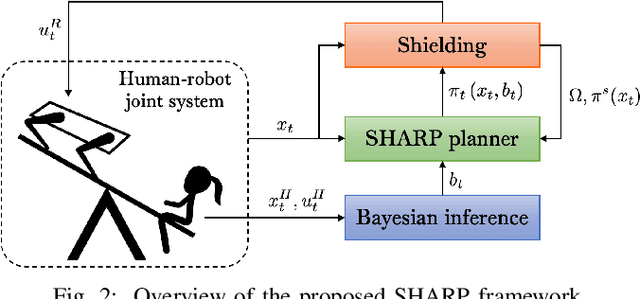
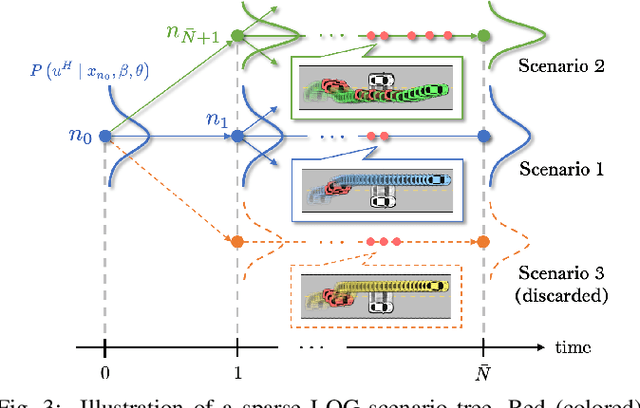
Jointly achieving safety and efficiency in human-robot interaction (HRI) settings is a challenging problem, as the robot's planning objectives may be at odds with the human's own intent and expectations. Recent approaches ensure safe robot operation in uncertain environments through a supervisory control scheme, sometimes called "shielding", which overrides the robot's nominal plan with a safety fallback strategy when a safety-critical event is imminent. These reactive "last-resort" strategies (typically in the form of aggressive emergency maneuvers) focus on preserving safety without efficiency considerations; when the nominal planner is unaware of possible safety overrides, shielding can be activated more frequently than necessary, leading to degraded performance. In this work, we propose a new shielding-based planning approach that allows the robot to plan efficiently by explicitly accounting for possible future shielding events. Leveraging recent work on Bayesian human motion prediction, the resulting robot policy proactively balances nominal performance with the risk of high-cost emergency maneuvers triggered by low-probability human behaviors. We formalize Shielding-Aware Robust Planning (SHARP) as a stochastic optimal control problem and propose a computationally efficient framework for finding tractable approximate solutions at runtime. Our method outperforms the shielding-agnostic motion planning baseline (equipped with the same human intent inference scheme) on simulated driving examples with human trajectories taken from the recently released Waymo Open Motion Dataset.
Stabilization of generative adversarial networks via noisy scale-space
May 04, 2021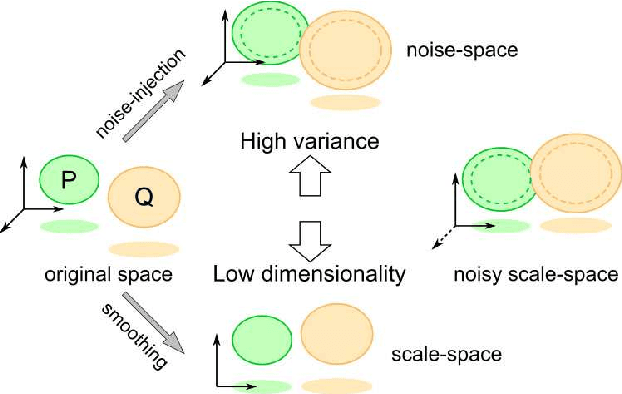
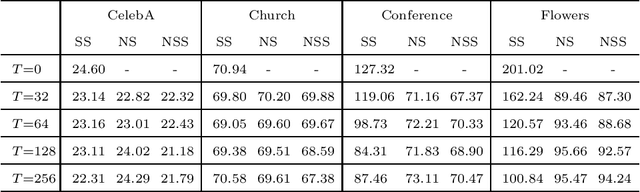

Generative adversarial networks (GAN) is a framework for generating fake data based on given reals but is unstable in the optimization. In order to stabilize GANs, the noise enlarges the overlap of the real and fake distributions at the cost of significant variance. The data smoothing may reduce the dimensionality of data but suppresses the capability of GANs to learn high-frequency information. Based on these observations, we propose a data representation for GANs, called noisy scale-space, that recursively applies the smoothing with noise to data in order to preserve the data variance while replacing high-frequency information by random data, leading to a coarse-to-fine training of GANs. We also present a synthetic data-set using the Hadamard bases that enables us to visualize the true distribution of data. We experiment with a DCGAN with the noise scale-space (NSS-GAN) using major data-sets in which NSS-GAN overtook state-of-the-arts in most cases independent of the image content.