 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHuman-like autonomy emerges from self-play and a pinch of human data
Jun 11, 2026Self-play reinforcement learning has recently emerged as a way to train driving policies without any human data. It uses cheap, large-scale simulations to substitute expensive, large-scale human driving demonstrations. A key limitation of this approach is that policies trained through pure self-play can learn effective but alien driving conventions incompatible with people. Previous works attempt to mitigate such behavioral misalignments through extensive reward engineering and domain randomization, which are brittle and labor-intensive. Instead of completely discarding human demonstrations, our method treats them as a regularization objective on top of a minimal safe goal-reaching reward. Like the spice in a good stew, we find that a little human data goes a long way: our method uses only 30 minutes of human demonstrations, 2500x fewer than comparable imitation learning approaches. Resulting policies coordinate with held-out human trajectories and complete training in 15 hours on a single consumer-grade GPU. Videos and full source code are available at https://spiced-self-play.com/.
Synthesis and Deployment of Maximal Robust Control Barrier Functions through Adversarial Reinforcement Learning
Apr 14, 2026Robust control barrier functions (CBFs) provide a principled mechanism for smooth safety enforcement under worst-case disturbances. However, existing approaches typically rely on explicit, closed-form structure in the dynamics (e.g., control-affine) and uncertainty models. This has led to limited scalability and generality, with most robust CBFs certifying only conservative subsets of the maximal robust safe set. In this paper, we introduce a new robust CBF framework for general nonlinear systems under bounded uncertainty. We first show that the safety value function solving the dynamic programming Isaacs equation is a valid robust discrete-time CBF that enforces safety on the maximal robust safe set. We then adopt the key reinforcement learning (RL) notion of quality function (or Q-function), which removes the need for explicit dynamics by lifting the barrier certificate into state-action space and yields a novel robust Q-CBF constraint for safety filtering. Combined with adversarial RL, this enables the synthesis and deployment of robust Q-CBFs on general nonlinear systems with black-box dynamics and unknown uncertainty structure. We validate the framework on a canonical inverted pendulum benchmark and a 36-D quadruped simulator, achieving substantially less conservative safe sets than barrier-based baselines on the pendulum and reliable safety enforcement even under adversarial uncertainty realizations on the quadruped.
Learning Personalized Agents from Human Feedback
Feb 18, 2026Modern AI agents are powerful but often fail to align with the idiosyncratic, evolving preferences of individual users. Prior approaches typically rely on static datasets, either training implicit preference models on interaction history or encoding user profiles in external memory. However, these approaches struggle with new users and with preferences that change over time. We introduce Personalized Agents from Human Feedback (PAHF), a framework for continual personalization in which agents learn online from live interaction using explicit per-user memory. PAHF operationalizes a three-step loop: (1) seeking pre-action clarification to resolve ambiguity, (2) grounding actions in preferences retrieved from memory, and (3) integrating post-action feedback to update memory when preferences drift. To evaluate this capability, we develop a four-phase protocol and two benchmarks in embodied manipulation and online shopping. These benchmarks quantify an agent's ability to learn initial preferences from scratch and subsequently adapt to persona shifts. Our theoretical analysis and empirical results show that integrating explicit memory with dual feedback channels is critical: PAHF learns substantially faster and consistently outperforms both no-memory and single-channel baselines, reducing initial personalization error and enabling rapid adaptation to preference shifts.
Video Generation Models in Robotics -- Applications, Research Challenges, Future Directions
Jan 12, 2026Video generation models have emerged as high-fidelity models of the physical world, capable of synthesizing high-quality videos capturing fine-grained interactions between agents and their environments conditioned on multi-modal user inputs. Their impressive capabilities address many of the long-standing challenges faced by physics-based simulators, driving broad adoption in many problem domains, e.g., robotics. For example, video models enable photorealistic, physically consistent deformable-body simulation without making prohibitive simplifying assumptions, which is a major bottleneck in physics-based simulation. Moreover, video models can serve as foundation world models that capture the dynamics of the world in a fine-grained and expressive way. They thus overcome the limited expressiveness of language-only abstractions in describing intricate physical interactions. In this survey, we provide a review of video models and their applications as embodied world models in robotics, encompassing cost-effective data generation and action prediction in imitation learning, dynamics and rewards modeling in reinforcement learning, visual planning, and policy evaluation. Further, we highlight important challenges hindering the trustworthy integration of video models in robotics, which include poor instruction following, hallucinations such as violations of physics, and unsafe content generation, in addition to fundamental limitations such as significant data curation, training, and inference costs. We present potential future directions to address these open research challenges to motivate research and ultimately facilitate broader applications, especially in safety-critical settings.
Machine Bullshit: Characterizing the Emergent Disregard for Truth in Large Language Models
Jul 10, 2025Bullshit, as conceptualized by philosopher Harry Frankfurt, refers to statements made without regard to their truth value. While previous work has explored large language model (LLM) hallucination and sycophancy, we propose machine bullshit as an overarching conceptual framework that can allow researchers to characterize the broader phenomenon of emergent loss of truthfulness in LLMs and shed light on its underlying mechanisms. We introduce the Bullshit Index, a novel metric quantifying LLMs' indifference to truth, and propose a complementary taxonomy analyzing four qualitative forms of bullshit: empty rhetoric, paltering, weasel words, and unverified claims. We conduct empirical evaluations on the Marketplace dataset, the Political Neutrality dataset, and our new BullshitEval benchmark (2,400 scenarios spanning 100 AI assistants) explicitly designed to evaluate machine bullshit. Our results demonstrate that model fine-tuning with reinforcement learning from human feedback (RLHF) significantly exacerbates bullshit and inference-time chain-of-thought (CoT) prompting notably amplify specific bullshit forms, particularly empty rhetoric and paltering. We also observe prevalent machine bullshit in political contexts, with weasel words as the dominant strategy. Our findings highlight systematic challenges in AI alignment and provide new insights toward more truthful LLM behavior.
Safety with Agency: Human-Centered Safety Filter with Application to AI-Assisted Motorsports
Apr 16, 2025We propose a human-centered safety filter (HCSF) for shared autonomy that significantly enhances system safety without compromising human agency. Our HCSF is built on a neural safety value function, which we first learn scalably through black-box interactions and then use at deployment to enforce a novel quality control barrier function (Q-CBF) safety constraint. Since this Q-CBF safety filter does not require any knowledge of the system dynamics for both synthesis and runtime safety monitoring and intervention, our method applies readily to complex, black-box shared autonomy systems. Notably, our HCSF's CBF-based interventions modify the human's actions minimally and smoothly, avoiding the abrupt, last-moment corrections delivered by many conventional safety filters. We validate our approach in a comprehensive in-person user study using Assetto Corsa-a high-fidelity car racing simulator with black-box dynamics-to assess robustness in "driving on the edge" scenarios. We compare both trajectory data and drivers' perceptions of our HCSF assistance against unassisted driving and a conventional safety filter. Experimental results show that 1) compared to having no assistance, our HCSF improves both safety and user satisfaction without compromising human agency or comfort, and 2) relative to a conventional safety filter, our proposed HCSF boosts human agency, comfort, and satisfaction while maintaining robustness.
RLHS: Mitigating Misalignment in RLHF with Hindsight Simulation
Jan 15, 2025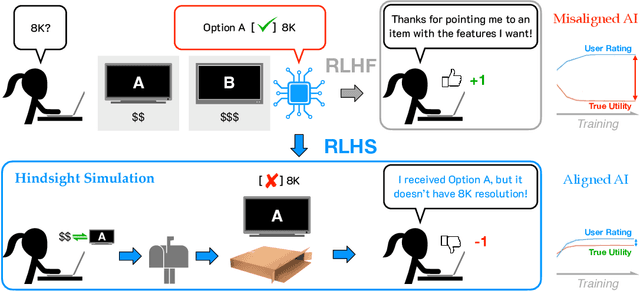



Generative AI systems like foundation models (FMs) must align well with human values to ensure their behavior is helpful and trustworthy. While Reinforcement Learning from Human Feedback (RLHF) has shown promise for optimizing model performance using human judgments, existing RLHF pipelines predominantly rely on immediate feedback, which can fail to accurately reflect the downstream impact of an interaction on users' utility. We demonstrate that feedback based on evaluators' foresight estimates of downstream consequences systematically induces Goodhart's Law dynamics, incentivizing misaligned behaviors like sycophancy and deception and ultimately degrading user outcomes. To alleviate this, we propose decoupling evaluation from prediction by refocusing RLHF on hindsight feedback. Our theoretical analysis reveals that conditioning evaluator feedback on downstream observations mitigates misalignment and improves expected human utility, even when these observations are simulated by the AI system itself. To leverage this insight in a practical alignment algorithm, we introduce Reinforcement Learning from Hindsight Simulation (RLHS), which first simulates plausible consequences and then elicits feedback to assess what behaviors were genuinely beneficial in hindsight. We apply RLHS to two widely-employed online and offline preference optimization methods -- Proximal Policy Optimization (PPO) and Direct Preference Optimization (DPO) -- and show empirically that misalignment is significantly reduced with both methods. Through an online human user study, we show that RLHS consistently outperforms RLHF in helping users achieve their goals and earns higher satisfaction ratings, despite being trained solely with simulated hindsight feedback. These results underscore the importance of focusing on long-term consequences, even simulated ones, to mitigate misalignment in RLHF.
MAGICS: Adversarial RL with Minimax Actors Guided by Implicit Critic Stackelberg for Convergent Neural Synthesis of Robot Safety
Sep 20, 2024While robust optimal control theory provides a rigorous framework to compute robot control policies that are provably safe, it struggles to scale to high-dimensional problems, leading to increased use of deep learning for tractable synthesis of robot safety. Unfortunately, existing neural safety synthesis methods often lack convergence guarantees and solution interpretability. In this paper, we present Minimax Actors Guided by Implicit Critic Stackelberg (MAGICS), a novel adversarial reinforcement learning (RL) algorithm that guarantees local convergence to a minimax equilibrium solution. We then build on this approach to provide local convergence guarantees for a general deep RL-based robot safety synthesis algorithm. Through both simulation studies on OpenAI Gym environments and hardware experiments with a 36-dimensional quadruped robot, we show that MAGICS can yield robust control policies outperforming the state-of-the-art neural safety synthesis methods.
Think Deep and Fast: Learning Neural Nonlinear Opinion Dynamics from Inverse Dynamic Games for Split-Second Interactions
Jun 14, 2024



Non-cooperative interactions commonly occur in multi-agent scenarios such as car racing, where an ego vehicle can choose to overtake the rival, or stay behind it until a safe overtaking "corridor" opens. While an expert human can do well at making such time-sensitive decisions, the development of safe and efficient game-theoretic trajectory planners capable of rapidly reasoning discrete options is yet to be fully addressed. The recently developed nonlinear opinion dynamics (NOD) show promise in enabling fast opinion formation and avoiding safety-critical deadlocks. However, it remains an open challenge to determine the model parameters of NOD automatically and adaptively, accounting for the ever-changing environment of interaction. In this work, we propose for the first time a learning-based, game-theoretic approach to synthesize a Neural NOD model from expert demonstrations, given as a dataset containing (possibly incomplete) state and action trajectories of interacting agents. The learned NOD can be used by existing dynamic game solvers to plan decisively while accounting for the predicted change of other agents' intents, thus enabling situational awareness in planning. We demonstrate Neural NOD's ability to make fast and robust decisions in a simulated autonomous racing example, leading to tangible improvements in safety and overtaking performance over state-of-the-art data-driven game-theoretic planning methods.
Versatile Scene-Consistent Traffic Scenario Generation as Optimization with Diffusion
Apr 03, 2024Generating realistic and controllable agent behaviors in traffic simulation is crucial for the development of autonomous vehicles. This problem is often formulated as imitation learning (IL) from real-world driving data by either directly predicting future trajectories or inferring cost functions with inverse optimal control. In this paper, we draw a conceptual connection between IL and diffusion-based generative modeling and introduce a novel framework Versatile Behavior Diffusion (VBD) to simulate interactive scenarios with multiple traffic participants. Our model not only generates scene-consistent multi-agent interactions but also enables scenario editing through multi-step guidance and refinement. Experimental evaluations show that VBD achieves state-of-the-art performance on the Waymo Sim Agents benchmark. In addition, we illustrate the versatility of our model by adapting it to various applications. VBD is capable of producing scenarios conditioning on priors, integrating with model-based optimization, sampling multi-modal scene-consistent scenarios by fusing marginal predictions, and generating safety-critical scenarios when combined with a game-theoretic solver.