 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePlanning-aligned Token Compression for Long-Context Autonomous Driving
Jun 05, 2026Monolithic vision-action models represent an emerging paradigm in autonomous driving. However, this architecture produces token sequences that quickly exceed real-time computational budgets when encoding extended temporal context for complex interactions. While approaches like linear transformers and external memory try to make the context lightweight, token compression is most compatible with the architecture as it requires no backbone modifications. Yet existing compression adopts rule-based heuristics like temporal decay, decoupled from planning, risking loss of decision-critical information. We propose COMPACT-VA, a planning-aligned working memory framework built on conditional VQ-VAE, compressing extended context into bounded representations. Compression is conditioned on both historical trajectory and a learned planning intent that the posterior encoder distills from future trajectories during training, while the prior encoder learns to predict it from compressed observations. The compressed memory, concatenated with the predicted latent, feeds the policy for end-to-end optimization, planning with retained decision-critical information. We evaluate on high-signal dynamic scenarios where historical context is most critical for behavior correctness (e.g., stop, yield, or proceed), and accordingly design behavioral metrics. Under comparable token budgets, we achieve $>$6% improvement (68.3%) on success rates with consistent gains across metrics. Ablations validate planning-aligned coupling effectiveness. Closed-loop evaluation confirms that COMPACT-VA maintained general driving performance with 3.3* speedup and 2.7* memory reduction over uncompressed processing.
ValueAlpha: Agreement-Gated Stress Testing of LLM-Judged Investment Rationales Before Returns Are Observable
Apr 28, 2026Long-horizon investment decisions create a pre-realization evaluation problem: realized returns are the eventual arbiter of investment quality, but they arrive too late and are too noisy to guide many model-development and governance decisions. LLM judges offer a tempting substitute for pre-deployment evaluation of AI-finance systems, but unvalidated judges may reward verbosity, confidence, or rubric mimicry rather than financial judgment. This paper introduces \textbf{ValueAlpha}, a preregistered agreement-gated stress-test protocol for deciding when LLM-judged investment-rationale claims are publishable, qualified, or invalid. In a controlled market-state capital-allocation prototype with 1,000 honest decision cycles and 100 preregistered adversarial controls (1,100 trajectories, 5,500 judge calls), ValueAlpha clears the aggregate agreement gate at \(\barκ_w = 0.7168\) but prevents several overclaims. Lower-rank systems collapse into a tie-class, one rubric dimension fails the per-dimension gate (\texttt{constraint\_awareness}, \(\barκ_w = 0.2022\)), single-judge rankings are family-dependent, and terse-correct rationales receive a \(Δ= -2.81\) rubric-point penalty relative to honest rationales. A targeted anchor-specificity probe further shows that financial constructs such as constraint awareness are operationally load-bearing. The contribution is therefore not a leaderboard and not a claim to measure true investment skill. ValueAlpha is a pre-calibration metrology layer for AI-finance evaluation: it determines whether a proposed LLM-judge-based investment-rationale claim is stable enough, agreed enough, and uncontaminated enough to be reported at all.
STORM: End-to-End Referring Multi-Object Tracking in Videos
Apr 12, 2026Referring multi-object tracking (RMOT) is a task of associating all the objects in a video that semantically match with given textual queries or referring expressions. Existing RMOT approaches decompose object grounding and tracking into separated modules and exhibit limited performance due to the scarcity of training videos, ambiguous annotations, and restricted domains. In this work, we introduce STORM, an end-to-end MLLM that jointly performs grounding and tracking within a unified framework, eliminating external detectors and enabling coherent reasoning over appearance, motion, and language. To improve data efficiency, we propose a task-composition learning (TCL) strategy that decomposes RMOT into image grounding and object tracking, allowing STORM to leverage data-rich sub-tasks and learn structured spatial--temporal reasoning. We further construct STORM-Bench, a new RMOT dataset with accurate trajectories and diverse, unambiguous referring expressions generated through a bottom-up annotation pipeline. Extensive experiments show that STORM achieves state-of-the-art performance on image grounding, single-object tracking, and RMOT benchmarks, demonstrating strong generalization and robust spatial--temporal grounding in complex real-world scenarios. STORM-Bench is released at https://github.com/amazon-science/storm-referring-multi-object-grounding.
ReSteer: Quantifying and Refining the Steerability of Multitask Robot Policies
Mar 18, 2026Despite strong multi-task pretraining, existing policies often exhibit poor task steerability. For example, a robot may fail to respond to a new instruction ``put the bowl in the sink" when moving towards the oven, executing ``close the oven", even though it can complete both tasks when executed separately. We propose ReSteer, a framework to quantify and improve task steerability in multitask robot policies. We conduct an exhaustive evaluation of state-of-the-art policies, revealing a common lack of steerability. We find that steerability is associated with limited overlap among training task trajectory distributions, and introduce a proxy metric to measure this overlap from policy behavior. Building on this insight, ReSteer improves steerability via three components: (i) a steerability estimator that identifies low-steerability states without full-rollout evaluation, (ii) a steerable data generator that synthesizes motion segments from these states, and (iii) a self-refinement pipeline that improves policy steerability using the generated data. In simulation on LIBERO, ReSteer improves steerability by 11\% over 18k rollouts. In real-world experiments, we show that improved steerability is critical for interactive use, enabling users to instruct robots to perform any task at any time. We hope this work motivates further study on quantifying steerability and data collection strategies for large robot policies.
Accelerating Structured Chain-of-Thought in Autonomous Vehicles
Feb 02, 2026Chain-of-Thought (CoT) reasoning enhances the decision-making capabilities of vision-language-action models in autonomous driving, but its autoregressive nature introduces significant inference latency, making it impractical for real-time applications. To address this, we introduce FastDriveCoT, a novel parallel decoding method that accelerates template-structured CoT. Our approach decomposes the reasoning process into a dependency graph of distinct sub-tasks, such as identifying critical objects and summarizing traffic rules, some of which can be generated in parallel. By generating multiple independent reasoning steps concurrently within a single forward pass, we significantly reduce the number of sequential computations. Experiments demonstrate a 3-4$\times$ speedup in CoT generation and a substantial reduction in end-to-end latency across various model architectures, all while preserving the original downstream task improvements brought by incorporating CoT reasoning.
Text-Guided Layer Fusion Mitigates Hallucination in Multimodal LLMs
Jan 06, 2026Multimodal large language models (MLLMs) typically rely on a single late-layer feature from a frozen vision encoder, leaving the encoder's rich hierarchy of visual cues under-utilized. MLLMs still suffer from visually ungrounded hallucinations, often relying on language priors rather than image evidence. While many prior mitigation strategies operate on the text side, they leave the visual representation unchanged and do not exploit the rich hierarchy of features encoded across vision layers. Existing multi-layer fusion methods partially address this limitation but remain static, applying the same layer mixture regardless of the query. In this work, we introduce TGIF (Text-Guided Inter-layer Fusion), a lightweight module that treats encoder layers as depth-wise "experts" and predicts a prompt-dependent fusion of visual features. TGIF follows the principle of direct external fusion, requires no vision-encoder updates, and adds minimal overhead. Integrated into LLaVA-1.5-7B, TGIF provides consistent improvements across hallucination, OCR, and VQA benchmarks, while preserving or improving performance on ScienceQA, GQA, and MMBench. These results suggest that query-conditioned, hierarchy-aware fusion is an effective way to strengthen visual grounding and reduce hallucination in modern MLLMs.
Counterfactual VLA: Self-Reflective Vision-Language-Action Model with Adaptive Reasoning
Dec 30, 2025Recent reasoning-augmented Vision-Language-Action (VLA) models have improved the interpretability of end-to-end autonomous driving by generating intermediate reasoning traces. Yet these models primarily describe what they perceive and intend to do, rarely questioning whether their planned actions are safe or appropriate. This work introduces Counterfactual VLA (CF-VLA), a self-reflective VLA framework that enables the model to reason about and revise its planned actions before execution. CF-VLA first generates time-segmented meta-actions that summarize driving intent, and then performs counterfactual reasoning conditioned on both the meta-actions and the visual context. This step simulates potential outcomes, identifies unsafe behaviors, and outputs corrected meta-actions that guide the final trajectory generation. To efficiently obtain such self-reflective capabilities, we propose a rollout-filter-label pipeline that mines high-value scenes from a base (non-counterfactual) VLA's rollouts and labels counterfactual reasoning traces for subsequent training rounds. Experiments on large-scale driving datasets show that CF-VLA improves trajectory accuracy by up to 17.6%, enhances safety metrics by 20.5%, and exhibits adaptive thinking: it only enables counterfactual reasoning in challenging scenarios. By transforming reasoning traces from one-shot descriptions to causal self-correction signals, CF-VLA takes a step toward self-reflective autonomous driving agents that learn to think before they act.
Towards Efficient and Effective Multi-Camera Encoding for End-to-End Driving
Dec 12, 2025We present Flex, an efficient and effective scene encoder that addresses the computational bottleneck of processing high-volume multi-camera data in end-to-end autonomous driving. Flex employs a small set of learnable scene tokens to jointly encode information from all image tokens across different cameras and timesteps. By design, our approach is geometry-agnostic, learning a compact scene representation directly from data without relying on the explicit 3D inductive biases, such as Bird-Eye-View (BEV), occupancy or tri-plane representations, which are common in prior work. This holistic encoding strategy aggressively compresses the visual input for the downstream Large Language Model (LLM) based policy model. Evaluated on a large-scale proprietary dataset of 20,000 driving hours, our Flex achieves 2.2x greater inference throughput while improving driving performance by a large margin compared to state-of-the-art methods. Furthermore, we show that these compact scene tokens develop an emergent capability for scene decomposition without any explicit supervision. Our findings challenge the prevailing assumption that 3D priors are necessary, demonstrating that a data-driven, joint encoding strategy offers a more scalable, efficient and effective path for future autonomous driving systems.
Latent Chain-of-Thought World Modeling for End-to-End Driving
Dec 11, 2025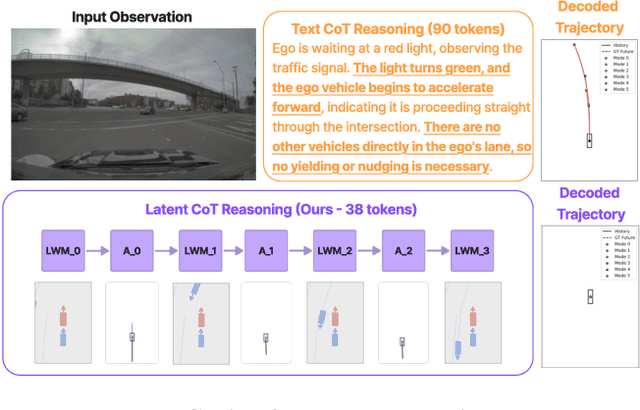
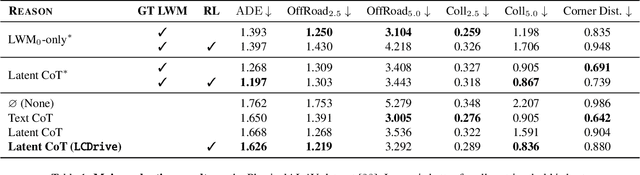
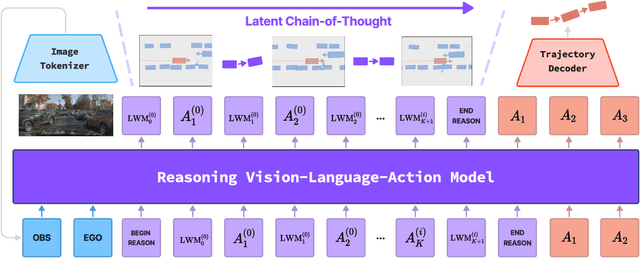
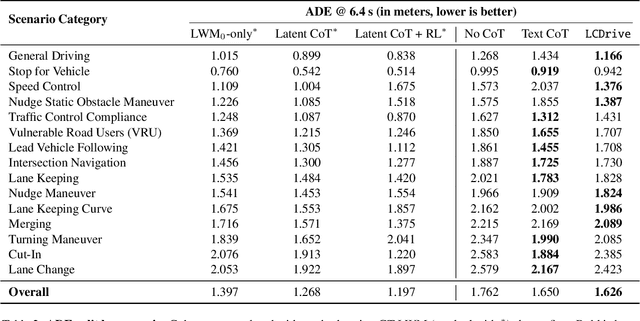
Recent Vision-Language-Action (VLA) models for autonomous driving explore inference-time reasoning as a way to improve driving performance and safety in challenging scenarios. Most prior work uses natural language to express chain-of-thought (CoT) reasoning before producing driving actions. However, text may not be the most efficient representation for reasoning. In this work, we present Latent-CoT-Drive (LCDrive): a model that expresses CoT in a latent language that captures possible outcomes of the driving actions being considered. Our approach unifies CoT reasoning and decision making by representing both in an action-aligned latent space. Instead of natural language, the model reasons by interleaving (1) action-proposal tokens, which use the same vocabulary as the model's output actions; and (2) world model tokens, which are grounded in a learned latent world model and express future outcomes of these actions. We cold start latent CoT by supervising the model's action proposals and world model tokens based on ground-truth future rollouts of the scene. We then post-train with closed-loop reinforcement learning to strengthen reasoning capabilities. On a large-scale end-to-end driving benchmark, LCDrive achieves faster inference, better trajectory quality, and larger improvements from interactive reinforcement learning compared to both non-reasoning and text-reasoning baselines.
RealDrive: Retrieval-Augmented Driving with Diffusion Models
May 30, 2025



Learning-based planners generate natural human-like driving behaviors by learning to reason about nuanced interactions from data, overcoming the rigid behaviors that arise from rule-based planners. Nonetheless, data-driven approaches often struggle with rare, safety-critical scenarios and offer limited controllability over the generated trajectories. To address these challenges, we propose RealDrive, a Retrieval-Augmented Generation (RAG) framework that initializes a diffusion-based planning policy by retrieving the most relevant expert demonstrations from the training dataset. By interpolating between current observations and retrieved examples through a denoising process, our approach enables fine-grained control and safe behavior across diverse scenarios, leveraging the strong prior provided by the retrieved scenario. Another key insight we produce is that a task-relevant retrieval model trained with planning-based objectives results in superior planning performance in our framework compared to a task-agnostic retriever. Experimental results demonstrate improved generalization to long-tail events and enhanced trajectory diversity compared to standard learning-based planners -- we observe a 40% reduction in collision rate on the Waymo Open Motion dataset with RAG.